手書きカタカナ文字をPCに認識させる(その③)
様々な経緯から、自前での手書き文字認識プログラムの作成(と言いつつ内容はほぼ写経)を断念した僕は、Microsoft社がBeta版として公開している画像分類器「Lobe」を使ってカタカナ「ア」~「オ」の学習モデルを作成。その性能をLobeが生成したPythonスクリプトで確認。Lobeの素晴らしい実力を知った(前回の記事)。今回は、DelphiでGUIを作成し、Object Pascalに埋め込んだPython Script内から、Lobeで作成した学習モデルのさらなる発展型(?)を呼び出して、手書きカタカナ文字認識(ただし、文字は「アイウエオ」の5文字に限定)に挑戦。
【学習モデルのさらなる発展型(?)を作った理由】
前回作った学習モデルでは、なぜか「ア」の認識率が異様に低いことが実験を繰り返す中で判明。そこで、これを改善するため、学習データを増やして学習モデルを再作成(アイウエオ各700文字→1700文字へ)。ただし・・・僕は素人も素人。機械学習のイロハも知らない、アタマの中は・・・言わば「機械学習のファンですー☆」みたいなキラキラ状態ですから、理論的な裏付けなどは超絶皆無の、自分史上最高レベルに!いい加減かつ、その場・その場での思いつき(代表例:学習データ数や二値化の閾値など)で素晴らしく適当に作り上げた・・・ホントに、こんなんでいいのか? みたいな・・・オリジナルと呼ぶのも恐ろしいデータセットを使い、言わば「カン」と「思い込み」と「自動採点に賭ける、もはや常人には理解し難い領域に達した・・・」ほとんど「狂気」に近い「異常な情熱」が相まって、ごくわかりやすく表現すれば「バカの一念の塊」のような学習モデルを作成することと、あいなりました。これは、自分的にはこれまでの経緯から見て、必然と言えば必然、当然と言えばあまりにも当然の結果なのですが。
・・・ただ、信じてもらえないカモですが、この学習モデルを使った認識実験の結果自体は、ウソだろー!と叫びたいくらいに・・・
So So So Gooooooooooooooooooooooooooooooooooooooooooooooooooooooood!
終わりよければすべてよし!(日本語には、ほんとに、いい言葉があるなー☆)もちろんこれは、ほとんど全部、Lobeのおかげですが、だからLobe ありがとう! とにかく、この学習モデルは僕の宝物です!
【今回の記事の内容】
1.embeddable pythonに必要なライブラリを入れる
2.TensorFlowを入れる時、パスが長すぎるとエラーが発生
3.Lobeで学習モデルを作る
4.浮動小数点例外をマスクする
5.手書きカタカナ文字をかなり正しく認識できた!
6.まとめ
7.お願いとお断り
1.embeddable pythonに必要なライブラリを入れる
重要 TensorFlowは「64bit環境」にしか入らない!
もしかして「常識」とでも言うべき?、上記の事実をまったく知らない僕は、手持ちの32bit用のembeddable pythonにTensorFlowを入れようと四苦八苦(前回の記事で、SDカード内にインストールして動かしていたWinPythonは64bitバージョンであったので、TensolFlowが32bit環境に対応していないことに、まったく気づかなかった・・・)。

Google先生に質問を繰り返す中で、エラーの真の原因をようやく理解した僕は、64bit版のembeddable pythonのダウンロードからやり直し。そう言えば、いつか、近所を走っていたトラックの屋根にも「イチから出直します」って書いてあったなー☆
https://www.python.org/downloads/windows/
上記ページの「Python 3.9.10 – Jan. 14, 2022」のダウンロードリンク「 Windows embeddable package (64-bit) 」をクリックして入手。
バージョン3.9.10を選んだ理由は、SDカードに入れたWinPythonが「3.9.8」だったので、これに近いバージョンの方がライブラリのインストールも含めて安心だと考えたため。
DLした「python-3.9.10-embed-amd64.zip」を適当なフォルダに解凍して、フォルダ名を「python39-64」に変更。こうしておけば、Pythonのバージョンと動作環境は一目瞭然。
スタートボタンを右クリック。「ファイル名を指定して実行」からコマンドプロンプトを起動して、まず、マークシートリーダー&手書き答案採点用embeddable python(32bit環境)にインストールしたライブラリを調査(64bit環境にも同じライブラリをインストールするため)。
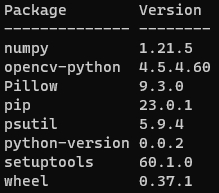
アクティブなディレクトリをPythonのインストールされているフォルダに変更して、「python -m pip list 」で現在インストールされているライブラリを確認&メモ。
pipは各種ライブラリをインストールするために必須だから最初にインストール。
numpy と opencv-python と pillow がマークシートリーダーや手書き答案採点用にインストールしたライブラリ。Pillowは画像処理用のライブラリだけど、僕はOpenCVへの画像読み込み時にエラーが起きないよう、Pillowで画像を読み込んでから、画像データをOpenCVに渡すようにしている・・・ので、そのために必要になり、後から追加・・・。
追加した理由は、確か・・・OpenCVのimread関数で、全角文字を含んだPathの先にある画像ファイルを読み込もうとすると失敗してしまうことに気づいて、それでこの失敗を回避する方法を調べて、「Pillowで画像を開き、NumPyへ変換して、それからOpenCVの画像形式に変更すればエラーにならない」ことを知り、あわてて実装したような・・・。
psutil は以前、いちばんカンタンなembeddable pythonの使い方をこのブログで紹介した時に入れたもの。
その他は入れた記憶がないので、最初から入っていたんじゃないかと。で、全体で158MBほど(DLして解凍したばかりのembeddable pythonは確か15~16MBくらいだった)。
64bit環境のembeddable pythonにも、これと同じライブラリを入れ、さらにTFLite形式でLobeが書きだした学習モデルを扱えるよう、TensorFlowもインストールする。各種ライブラリを入れるための準備と、ライブラリの実際のインストールのようすは次の通り。
pipを使えるようにしてから、64bit環境のembeddable pythonに各種ライブラリをインストール。コマンドプロンプトを起動し、先に作成しておいたpython39-64フォルダをカレントディレクトリにして、次のコマンドを入力。
python -m pip list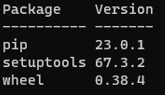
最初にNumpyを入れる。
python -m pip install numpy
次にOpenCVを入れる。
python -m pip install opencv-python
全角文字入りのPathに対応するため、Pillowも入れる。
python -m pip install pillow
2.TensorFlowを入れる時、パスが長すぎるとエラーが発生
次は、いよいよTensorFlowだ。
ちょっとドキドキしながら、おまじないを入力。で、Enterキーを叩く。
python -m pip install tensorflowしばらくは、順調そうな感じだったけれど・・・、突然、画面ニ赤ヒ、文字ガ、浮カビ・・・。
そう、Pythonのライブラリをいじるときは、いつも・・・これが、どこかで出現・・・
するんだなー もう(>_<)

OSError ってナニ?
No such file or directory: ってコトは・・・つまり、とんでもなくながーいPathの最後にある「bufferizableopinterface.cpp.inc」が見えないってコトなのかなー???
いったい、なんじゃろー。。。
とりあえず、検索キーワードを「bufferizableopinterface.cpp.inc 」にして、Google先生にきいてみよう!(こんなんで、挫けてる場合じゃない。ここまでで、夢の実現に、もう二ヶ月かかってる・・・)

あった! あった!
きっと、コレだ。
迷わず「このページを訳す」の方をクリックすると、以下の記事が・・・
問題は、パスの文字数制限です。Windows でこの制限を無効にすることが解決策です。それかー☆
パスの文字数制限を解除するには、下記のように操作するとのこと。
スタートボタンの右隣りにある「検索」で、「グループポリシーの編集」と入力して、「ローカルグループポリシーエディター」を表示。で、「コンピューターの構成」→「管理用テンプレート」→「システム」→「ファイル システム」とたどって、右側、ファイルシステム「設定」画面の「Win32の長いパスを有効にする」をダブルクリック。
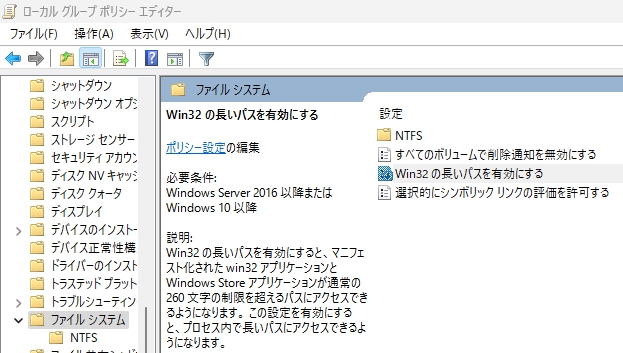
「Win32の長いパスを有効にする」というCaptionのWindowが表示されるので、画面左にある「有効」のラジオボタンをチェックして「OK」をクリック。
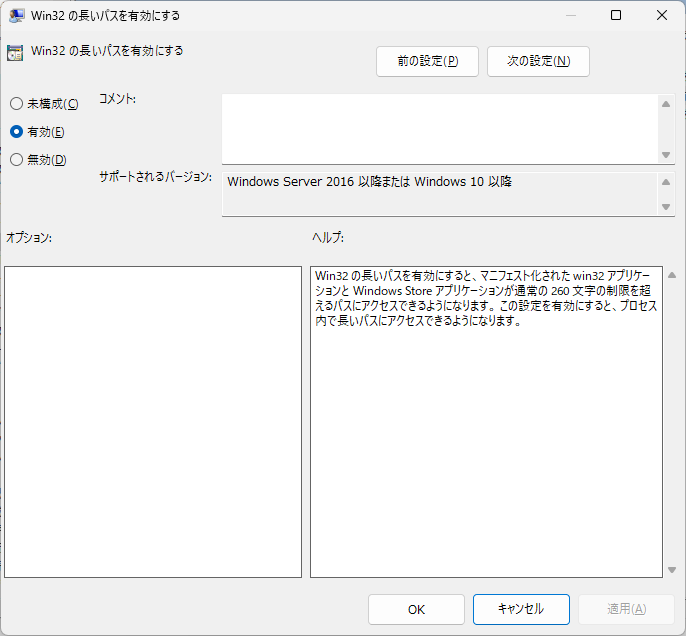
やったー☆ きっと、もう大丈夫!
で、あらためて、おまじないを実行。
python -m pip install tensorflow今度は・・・
Collecting tensorflow
Using cached tensorflow-2.11.0-cp39-cp39-win_amd64.whl (1.9 kB)
Collecting tensorflow-intel==2.11.0
Using cached tensorflow_intel-2.11.0-cp39-cp39-win_amd64.whl (266.3 MB)
Requirement already satisfied: ・・・
Requirement already satisfied: ・・・
Requirement already satisfied: ・・・
・・・これがたくさん出て・・・
・・・パスを通すか、警告を制御しなさい・・・というお決まりのアレが出て・・・
・・・でも、最後にこれが出たら成功だから、このメッセージは僕にとって吉兆・・・
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed tensorflow-2.11.0 tensorflow-intel-2.11.0やったー!! 入ったー☆☆☆
入ったケド・・・ Python39-64フォルダの容量は全体で「1.27GB」になっちゃった。
ちょっと、デカくない? ってか、ヒトにあげるのは躊躇するくらいの大きさだなー。
不要なファイルの削り方が知りたい・・・。
3.Lobeで学習モデルを作る
実際の処理の流れでいうと、これがいちばん先なんだけれど・・・
前回、機械学習用に準備した手書きカタカナ文字画像(水増しを含む)700枚は、そのまま今回も使用することにして、新たにETL文字データベースのア~オを学習用データに利用することにした。
ただし、そのままでは使用できないので、輝度反転し、さらに二値化して学習用データとする。輝度反転のスクリプトは次の通り。※ファイル名には、例えば「ア」の画像であれば「a0000.png」のように「a+0埋めした4桁の通し番号」を付けている。
# 輝度反転
from PIL import Image
import numpy as np
from matplotlib import pylab as plt
for i in range(2898):
# 画像の読み込み
im = np.array(Image.open(r"X:\Path"+r"\a"+'{0:04d}'.format(i)+".png").convert('L'))
# 輝度反転
im = 255 - im[:,:]
# print(im.shape, im.dtype)
#保存
Image.fromarray(im).save(r"X:\Path"+r"\a"+'{0:04d}'.format(i)+".png")上記スクリプトを実行して輝度反転すると・・・

文字以外の部分に、かなり濃い灰色の部分がたくさん生じてしまう。このまま学習用データとして利用した方がいい(ロバスト性が高まる?)のか、それともさらに二値化して、完全に白と黒の極端方向に振った学習データとするか、しばし、悩む。自分の中に理論的な裏付けなど何もないので、悩むと言っても、選択肢は二つのうちのどちらかしかないんだけど。
ここで思い出したのが、前回、学習用に用意した画像の特徴・・・。職場の各階の要所に備え付けられている複合機のスキャナーで読み取ったグレースケールの画像(読み取り解像度200dpi)は二値化していないので、空白(文字のない)部分はごく薄い、少しだけ濃淡のある灰白色で構成され、また、文字部分も完全な黒ではない。

理論的な根拠なんか、なーんにもないけど、学習モデルのロバスト性を高める分には、コレが700枚もあれば必要にして十分なんじゃないか?
新しく用意する画像は、二値化で白と黒だけにして、最も極端な方向で学習データを作成してみて、これに前の実験で使った700枚の画像を加えて機械学習を実行。その結果を見て必要であれば、また次の方法を考えたらいいんじゃないか?
みたいな感じで、だんだん、考えがまとまってきた!
とりあえず、新しく用意した画像データを二値化してみる。閾値は試行錯誤を数回繰り返して「200」とした。
# 二値化
import cv2
for i in range(2898):
# 画像の読み込み
img = cv2.imread(r"X:\Path"+r"\a"+'{0:04d}'.format(i)+".png", 0)
# 閾値の設定
threshold = 200
# 二値化(閾値を超えた画素を255にする。)
ret, img_thresh = cv2.threshold(img, threshold, 255, cv2.THRESH_BINARY)
#保存
cv2.imwrite(r"X:\Path"+r"\a"+'{0:04d}'.format(i)+".png", img_thresh)二値化した画像を部分拡大。ビシっと見事に白と黒に分かれた(当然)。これが吉と出るか、凶と出るか、結果は神のみぞ知る・・・

それから、二値化して困ったのは、次のようなシミ・汚れが多数ある画像の取り扱い。

様々に思い悩んだが、結局、新規に作成する文字データは、白 or 黒いずれかの色のみで構成すると決めたので、中途半端なシミや汚れは排除することにして、シミや汚れのある画像を徹底的に手動で削除。これは修行だと考えて、1万枚を超える画像を1枚ずつチェックしながら、一心不乱に作業した。せっせ、せっせ、せっせ、せっせ・・・
あー! 消さなくてもイイ画像 消しちゃった!! みたいな >_<
こうして最終的に「ア~オ」の各文字約3000枚程度の機械学習用画像データができた。これをフォルダ名を半角数字で「0~4」とした五つのフォルダに入れ、Lobeで機械学習を実行。
1分・・・、 3分・・・、 5分・・・ 時は静かに流れる・・・
ひまだなー。ひまだなー。
10分・・・、 30分・・・、1時間・・・ Lobeさん、まぁだぁ???
ものすごぉーく、ひまなんだケドー
2時間・・・ たっても、
まだ1/4しか進行状況を示すインジケーターが進んでない!!
ご主人様、
もぉ 無理。
待ちくたびれました。
忠犬ハチ公もこんな気持ちだったのか・・・、なー☆
前回、各文字700枚で処理した時は、20~30分くらいで機械学習が終了した気がするんだけど・・・。各文字3000枚だと、もしかして数日必要だったりするとか・・・???
うわー! そんなんイヤだ。
やり直そう。
・・・ということで、残念ながらいったんLobeを強制終了。プロジェクトは削除する。
あらためて学習させる文字データの数について再考。前回作成した文字データ700枚に、今回新たに作成した文字データを1000枚加えて、各文字1700枚、合計8500枚で学習モデルを作成してみることに決定(理由は特になし)。
Lobeを再起動し、プロジェクト名を「aiueo2」にして、用意した学習データを再度読み込ませ、機械学習を開始。今度は約2時間50分でトレーニングが終了。続けて、Lobeの推奨設定の通りに「最適化」してTFLite形式の学習モデルを書き出す。これに要した時間がさらに2時間40~50分。およそ半日を要したが、ついに念願(?)の学習モデルが完成した。
1%程度の画像が分類不可とされたが、これらの画像は再学習の対象とせず、破棄することにした(前回、再学習させようとしたら、トレーニングの進行状況の表示が99%からいきなりガクンと落ちて40%台になり、Lobeはそこから学習を再開。これを分類不可とされた文字ごとにエンエンと繰り返しながら、根気強くトレーニングの完了を待つ気にはどうしてもなれなかったことを思い出した。今回は画像数も倍増させたし・・・。どうしてもその必要性を感じたら、その時、考えればイイかぁ・・・みたいな)。
4.浮動小数点例外をマスクする
カタカナ画像ファイルを直接読み込み、準備した学習モデルが書かれている文字を認識、ユーザーに対してその結果を表示する・・・、もし、ショー的な要素が必要なければ、それだけのプログラムで全然OKなんだけど、演示実験的にShowすることも目的に含めてテストするには、やはりマウスで直接、PC画面にリアルタイムでカタカナ文字を書いて、ボタンクリックで画像中の文字を認識、結果を表示するという流れが好ましい。
そこで、手書きカタカナ文字認識のGUIは、前回の記事を書いたときに見つけたエンバカデロさんのMNISTの手書き数字認識プログラムの紹介記事にあったGUIを参考にして作成。4年前にMNISTの手書き数字認識を試したときは、PyQtでさんざん苦労してGUIを作成したけど、今度はDelphi☆ ヒトとキカイの間を取り持つインターフェイスはすぐに完成!
https://blogs.embarcadero.com/ja/how-to-build-a-digit-classifier-in-tensorflow-ja/
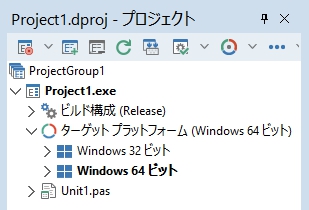
ターゲットプラットフォームは64bitに設定。
動作に最低限必要と思われるプログラムを書いて、デバッガを使わずに実行してみた・・・。
とりあえずマウスで「ア」と書いて、「文字として認識」をクリック。
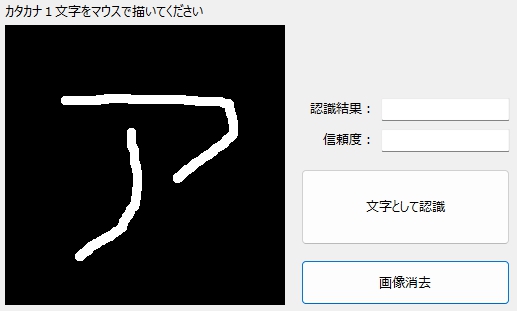
予想もしなかった結果が。
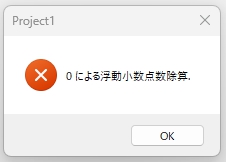
・・・てか、想定外以外のナニモノでもないんだケド。
32bit環境では、見た記憶のないエラーメッセージ。
で、「デバッガを使わずに実行(Shift+Ctrl+F9)」ではなく、デバッガ例外通知のある「実行(F9)」で状況を再確認。
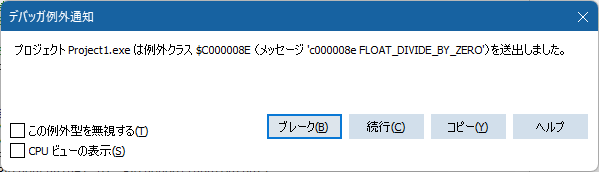
なんで、こうなるのか?
メッセージにある「c000008e FLOAT_DIVIDE_BY_ZERO」を検索キーワードにしてGoogle先生に質問。すると・・・
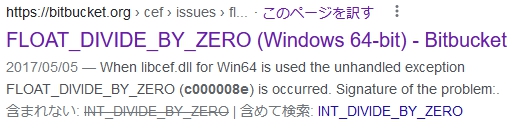
https://bitbucket-org.translate.goog/chromiumembedded/cef/issues/2166/float_divide_by_zero-windows-64-bit?_x_tr_sl=en&_x_tr_tl=ja&_x_tr_hl=ja&_x_tr_pto=sc
もちろん、英語はじっくり読まないとわからないから「このページを訳す」をクリック。そして、表示されたWebページの中に次の語句を発見。
Delphi - Set8087CW、SetMXCSR、および TWebBrowser を使用した浮動小数点例外のマスキング」を参照してください。Delphi – Set8087CW、SetMXCSR、および TWebBrowser を使用した浮動小数点例外のマスキング」を参照してください。
https://stackoverflow-com.translate.goog/questions/19187479/masking-floating-point-exceptions-with-set8087cw-setmxcsr-and-twebbrowser?_x_tr_sl=en&_x_tr_tl=ja&_x_tr_hl=ja&_x_tr_pto=sc
(マスキング・・・ってことは、つまり、覆い隠すってコト?)
リンク先を読んでみると・・・(上記Webサイトより引用)
最も簡単な方法は、初期化コードのある時点で例外をマスクすることです。
これを行う最良の方法は次のとおりです。
SetExceptionMask(exAllArithmeticExceptions);
ナニがどうしてエラーが起きているのか、その本当の原因は、まるでわかんないけど、取り敢えず、対応方法だけはわかった気がする! 調べてみると、SetExceptionMaskuses は、Mathユニットにあるようなので、uses に System.Math を追加して・・・
implementation
uses
System.Math,
//System.Mathは
//PythonEngine1.ExecStrings()で「0による浮動小数点数除算」のエラーを出ないようにするおまじない
//SetExceptionMask(exAllArithmeticExceptions)を実行するために追加
{$R *.dfm}で、FormCreateに次の1行を追加。
procedure TForm1.FormCreate(Sender: TObject);
var
//Python39-64へのPath
AppDataDir:string;
begin
//「0による浮動小数点数除算」のエラーを出ないようにするおまじない
SetExceptionMask(exAllArithmeticExceptions);
//Embeddable Pythonの存在の有無を調査
AppDataDir:=ExtractFilePath(Application.ExeName)+'Python39-64';
if DirectoryExists(AppDataDir) then
begin
//フォルダが存在したときの処理
//MessageDlg('Embeddable Pythonが利用可能です。', mtInformation, [mbOk] , 0);
PythonEngine1.AutoLoad:=True;
PythonEngine1.IO:=PythonGUIInputOutput1;
PythonEngine1.DllPath:=AppDataDir;
PythonEngine1.SetPythonHome(PythonEngine1.DllPath);
PythonEngine1.LoadDll;
//PythonDelphiVar1のOnSeDataイベントを利用する
PythonDelphiVar1.Engine:=PythonEngine1;
PythonDelphiVar1.VarName:=AnsiString('var1'); //プロパティで直接指定済み
//初期化
PythonEngine1.Py_Initialize;
end else begin
MessageDlg('Embeddable Pythonが見つかりません!',
mtInformation, [mbOk] , 0);
PythonEngine1.AutoLoad:=False;
end;
end;こうなったら、実行以外の選択肢はない。結果を信じて、実行!
マウスで「ア」って書いて、「文字として認識」をクリック☆
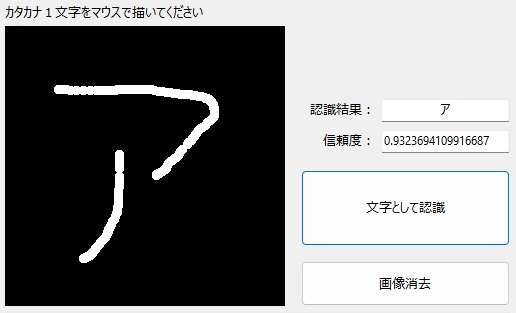
エラーがマスクされ、結果が「正解」で返ってキタ。でも、これでいいのかなー?
なんとか動くようになったところで、ナニがどうなって、エラーが起きているのか、確かめてみることに。
コードを追いかけてみると、どうやら「文字として認識(button2)」ボタンをクリックした際に実行される手続き内の PythonEngine1.ExecStrings 部分でエラーが発生しているようだ。・・・ってコトは、Python4Delphi側の問題?
Delphi PythonEngine1.ExecStrings エラー上記の検索キーワードで、Google先生にお伺いを立てると・・・
https://github.com/pyscripter/python4delphi/issues/124
上のリンク先Webサイトに、新たな情報を発見!(上記Webサイトより引用)
this is the example where you need to put the "MaskFPUExceptions(True);"
procedure TForm1.Button1Click(Sender: TObject);
begin
MaskFPUExceptions(True);
PythonEngine1.ExecStrings( Memo1.Lines );
end;そういう方法もあったのか・・・。
ってか、この関数、Webからコピペしただけなのに未定義の識別子エラーにならない? ・・・オレ、新しいユニットは何にもusesしてないぞ・・・ってことは、もしかして、この関数は、Python4Delphiに、はじめから備わってる関数なんじゃないの? ふと、そんな気が。マウスでMaskFPUExceptionsをポイントすると・・・
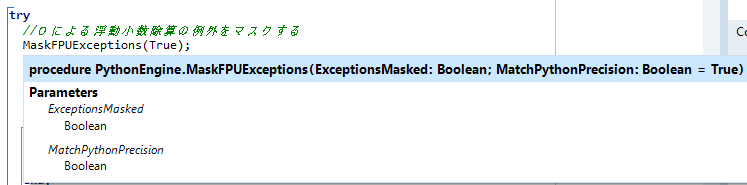
その通りだったようで。それなら、こっちを使う方がいいのかなー?
そもそも「FPU」なるモノは、「Floating-point number Processing Unit:浮動小数点数演算装置」の略称とのことで、その「Exceptions」=例外の「Mask」だから、「浮動小数点例外のマスク」ということでMaskFPUExceptions。実に覚えやすい良い名前。
一方の、SetExceptionMask関数も名前は良いんだけど、System.Mathをusesしなければ使えないところが玉にキズ。しばらく時間を置いた後は(あれ、usesするユニットはなんだったっけ?)みたいなコトになりそう・・・。
結局、なぜ、浮動小数点例外が発生するのかは、わからずじまいだったけれど。プログラムが動作しないという最悪の事態だけは回避できました☆
5.手書きカタカナ文字をかなり正しく認識できた!
手書きカタカナ文字を認識する部分のPythonのスクリプトは、LobeからTFLite形式で学習モデルを書き出した際、一緒に作られたexampleフォルダにあった「tflite_example.py」を参考にして作成。
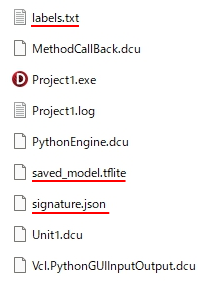
正解のlabelは「ア」を入れたフォルダ名を「0」、「イ」を「1」、「ウ」を「2」、「エ」を「3」、「オ」を「4」としたので「0~4」。先に述べたように、このフォルダ名&構成のままLobeにDatasetとして読み込ませて機械学習を実行。その学習モデルをTFLite形式で出力。その際に自動的に生成された、TFLite形式の学習モデルと、正解ラベルのテキストファイルと、ラベル名や入力形式など学習モデルに関する様々な情報が入っているらしい signature.json ファイルをexeと同じフォルダにコピー。※下図で赤い下線を引いたファイル
作成したLobeの学習モデルは、カタカナ文字の認識結果を、上記1~4の数字で返すので、次のようにPythonからDelphiへ値を渡す処理を記述。
outputs = model.predict(image)
if outputs["label"] == "0":
var1.Value = str("ア") + "," + str(outputs["confidence"])
elif outputs["label"] == "1":
var1.Value = str("イ") + "," + str(outputs["confidence"])
elif outputs["label"] == "2":
var1.Value = str("ウ") + "," + str(outputs["confidence"])
elif outputs["label"] == "3":
var1.Value = str("エ") + "," + str(outputs["confidence"])
elif outputs["label"] == "4":
var1.Value = str("オ") + "," + str(outputs["confidence"])Delphi側で、var1にセットされた値を受け取り、文字列リストに追加。
private
{ Private 宣言 }
//Pythonから送られたデータを保存する
strAnsList:TStringList;
procedure TForm1.PythonDelphiVar1SetData(Sender: TObject; Data: Variant);
begin
//値がセットされたら文字列リストに値を追加
strAnsList.Add(Data);
Application.ProcessMessages;
end;最終的な処理として、戻り値に入れておいたカンマを区切り記号として文字列を分割。
認識結果と信頼度のTEditにそれぞれの値を表示。
こうしてGUIはDelphiで、内部的な文字認識はPythonで実行する手書き文字認識プログラムができた☆ さっそく実行!!
結果は次の通り。
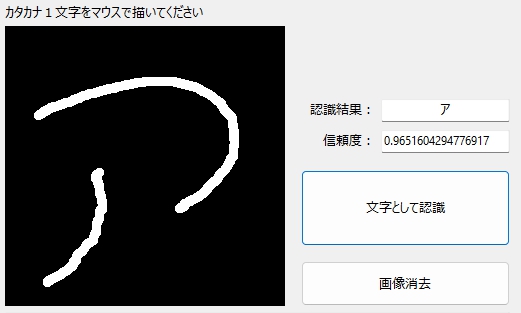
「ア」の認識
それは、ひらがなの「つ」と、カタカナの「ノ」だろ! みたいな「ア」も、しっかり認識してくれました☆
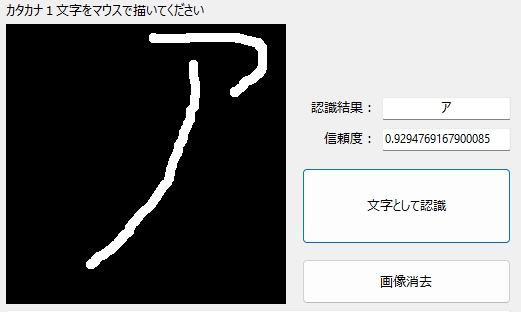
数字の「3」みたいな「ア」も、無事認識☆
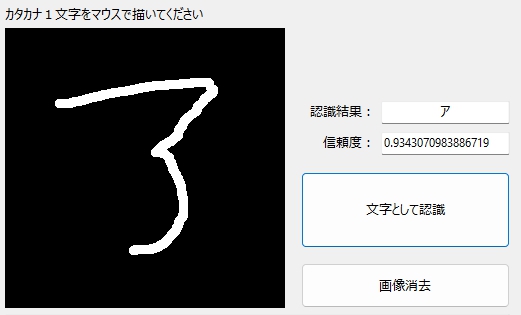
多少、小さくても、はじっこに片寄っても、大丈夫☆
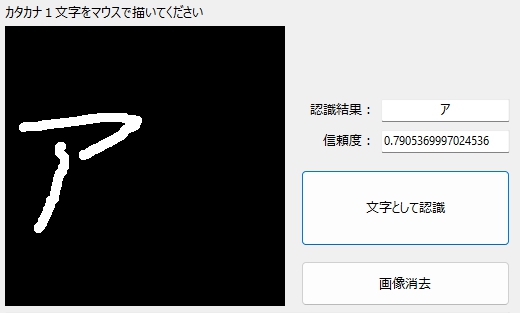
気のながそーな「ア」もイケました☆
もちろん、標準的(?)な「ア」なら、信頼度は99.9% 不安感はゼロ☆
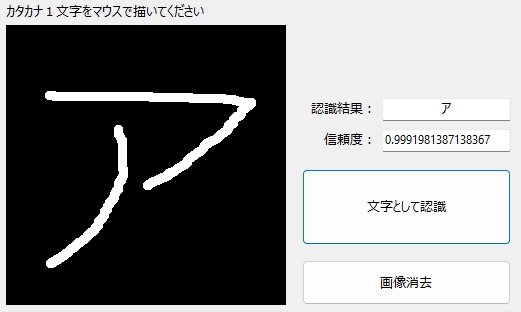
Pythonのみで、ほとんど写経で作った学習モデルをもとにしたカタカナ文字認識を試したときは、うまく判定してくれるかどうか、毎回、祈るような気持ちで、判定結果を見つめた・・・もの。そこには、With かなりのドキドキ感(・・・と言うか、なんかダメそう・・・みたいなネガティブな感覚)が常につきまとって、それを最後まで拭い去ることはできなかったのですが、今回、Lobeで作成した学習モデルには、そのような不安感をほぼ感じません。Lobeの学習モデルには、ほぼ正しく手書きカタカナ文字を認識してくれるという、ナニモノにも代えがたい安心感があります。
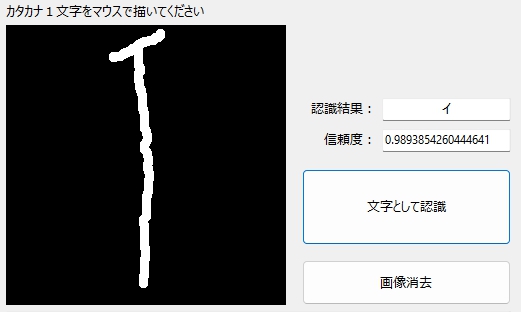
「イ」の認識
アルファベットの「T」みたいな「イ」であっても、学習モデルは正しく「イ」と判定。
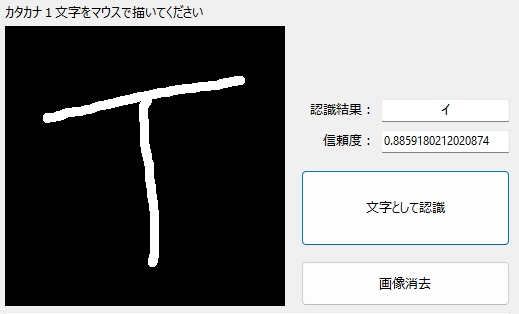
こちらも、多少の片寄りは、ほぼ問題なし。
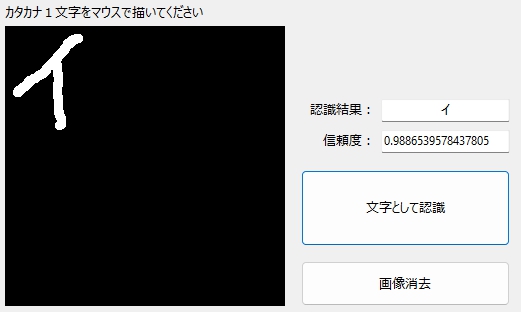
少しくらいなら、傾いても、大丈夫。タイトルは「酔っぱらったイ」。
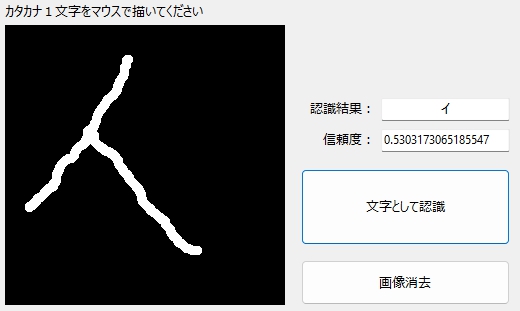
末広がり(?)な「イ」も・・・
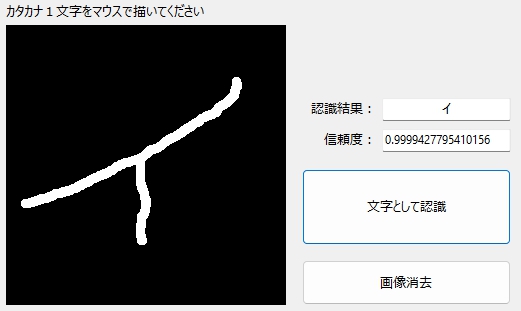
僕のような、やせっぽちの「イ」も、平気でした☆
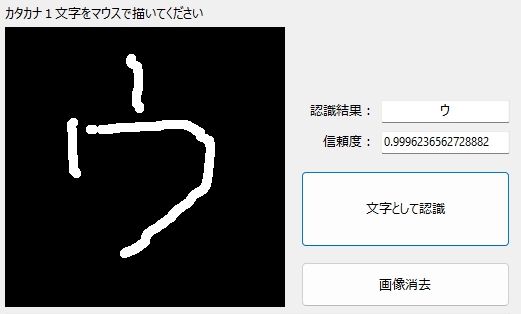
「ウ」の認識
まずは、無難な「ウ」
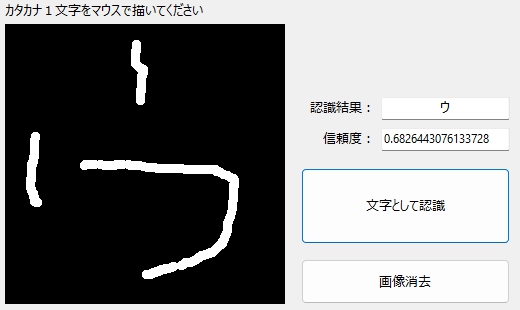
砕け散った「ウ」も・・・
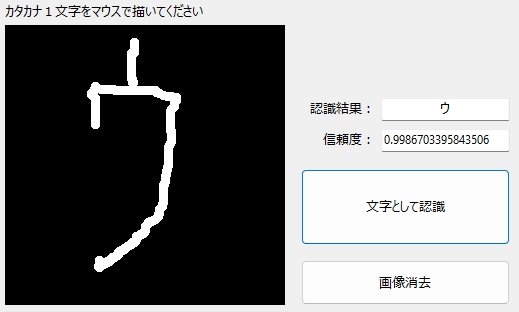
やせっぽちの「ウ」も・・・
「ラ」に恋をしたような「ウ」も・・・(実際に、こんな「ウ」があった)
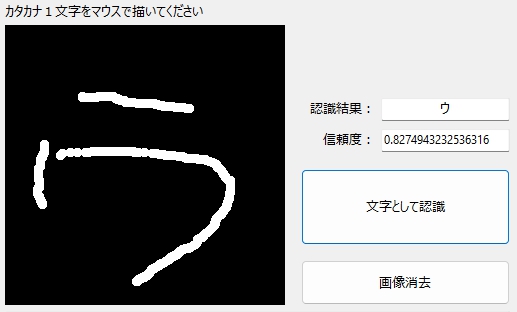
斜体の「ウ」も正しく認識。
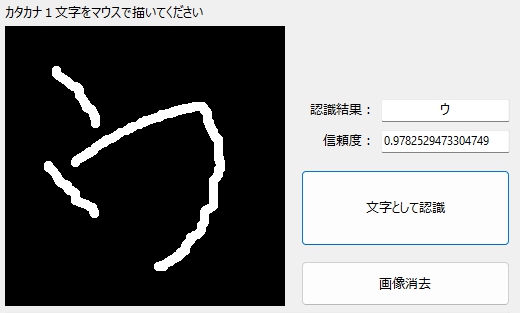
「エ」の認識
まずは、普通の「エ」。信頼度は99.99%!
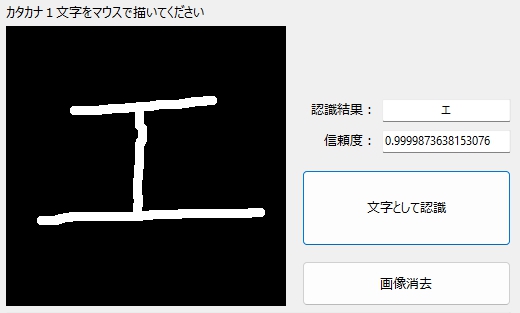
片寄ってもOK!
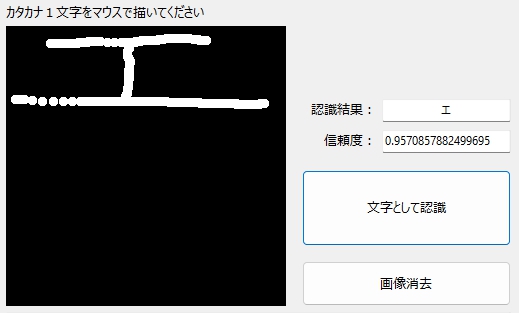
伸びてもOK!
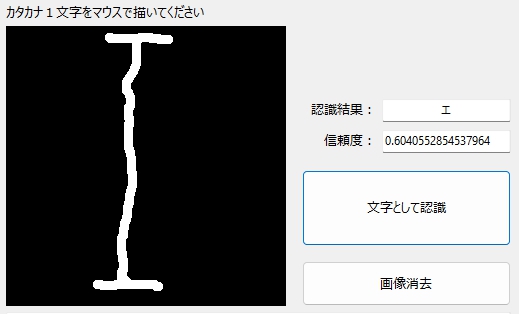
傾いてもOK!
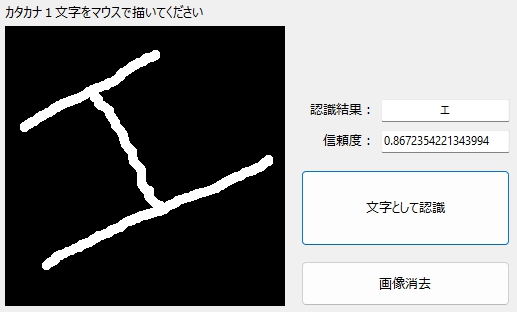
「オ」の認識
普通の「オ」。
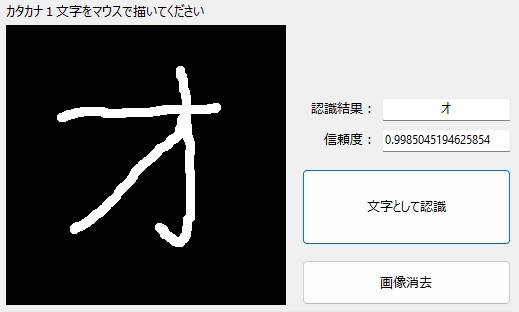
それは漢字の「才」だろ・・・みたいな「オ」も
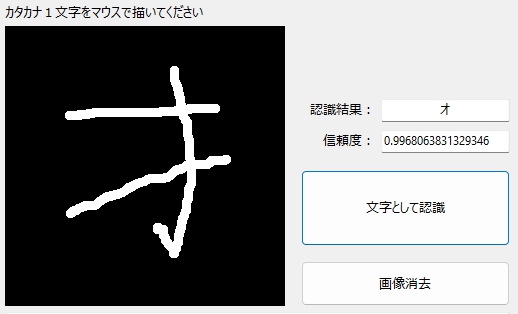
出ているハズの部分が、ほとんど出てない「オ」も・・・
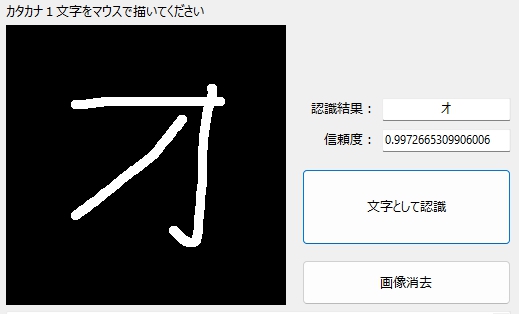
斜体の「オ」も・・・
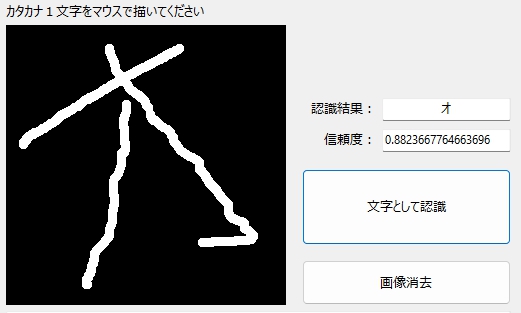
伸びても・・・
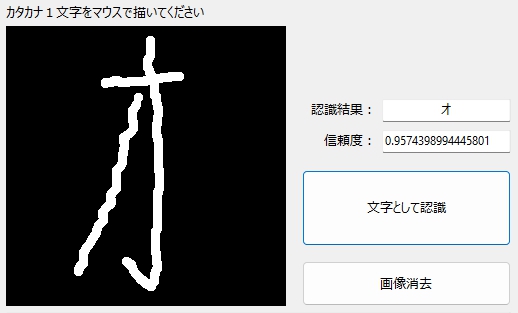
Lobe ほんとに優秀!
ただし、新たに気づいてしまった、ある問題を除いては・・・
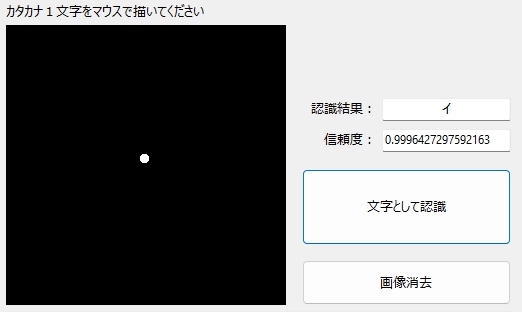
僕の自由研究はつづく・・・
6.まとめ
(1)TensorFlowは「64bit環境」にしか入らない!
(2)TensorFlowを入れる時、パスの文字数制限の解除が必要になる場合もある。
(3)学習データが大量にある場合、機械学習にも、最適化にも時間がかかる。
(4)0による浮動小数除算エラーが発生する場合は、例外をマスクする。
(5)学習モデルが未学習のデータに出会った時の挙動は今後要研究。
7.お願いとお断り
このサイトの内容を利用される場合は、自己責任でお願いします。ここに記載した内容を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。