ほんとうは、今回のお話のタイトルは・・・
手書き答案の「デジタル採点補助プログラム」のつもりで作った僕のAC_Reader に自動採点機能も搭載しました!
・・・にしたかったのですが、すみません。その前に、自動採点を行うための準備ついて、どこのサイトにもあまり書いてないことを、書いておきたいと思います。
これから書くことは、もしかしたら僕が知らなかっただけで、機械学習に携わる方であれば注意・留意事項以前の「常識」と言っていいようなことなのかもしれません。
それでも、万一にでも、僕の経験が、初めて機械学習や自動採点に挑戦される方の参考になれば、それこそ、何よりの幸いです。
追記
機械学習のライブラリは何にするか・・・とか、溢れんばかりに、いや、溢れかえるほどに情報があることではなく、僕は、それ以前の物語(準備作業)の重要性に気づいたのです。思ったような結果が出ないのは、ライブラリが悪いのではなく、学習用データや推論用データの作り方に問題があったのです。
ある規格に揃えられた、ブレないデータで学習し、学習時と同じ規格で生成された、ブレないデータで推論(判定)する。これがさんざんまわり道をしてたどり着いた、僕なりの結論です。機械学習の最重要ポイントは、データの作成にありました。
【もくじ】
1.学習&推論データについて
2.解答欄の切り出し
3.解答欄からの解答の切り出し
4.学習用データを作る
5.学習モデルを作る
6.まとめ
7.お願いとお断り
1.学習&推論データについて
機械学習を行うためには、機械に学習させるデータが必要なことは言うまでもありません。数字ならMNIST、日本語のカタカナであれば ETL といったところでしょうか。
2年前、初めて機械学習にチャレンジしたとき、上の2つのデータベースを知り、当時は keras とニューラルネットワークを使ってカタカナ「アイウエオ」の自動採点に挑戦・・・
それなりに時間と、手間暇をかけて自分なりに頑張ったのですが、どうしても夢見たような結果が得られず、最終的には・・・ 自作のデジタル採点プログラムへの搭載を断念。
そのいちばんの原因は、(今思えば)学習モデル作成以前に、「高品質な学習データを準備できなかった」ことにありました。
例えば、学習データとする文字・数字・記号を縦横 28 ピクセルの画像として用意するとした場合、画僧中の文字・数字・記号の大きさ、位置、濃さ、その他、画像中のシミや汚れ、等々と言った実に様々な要素の影響を考慮し、必要な場合は修正(補正)を施して・・・、
学習モデル作成用に準備した学習用画像の「それ」と
実際の採点に利用する解答用紙の解答欄から切り出した推論用画像の「それ」が
完全に一致するように「学習用」&「推論用」画像を準備しなければなりません。
場合によっては、推論対象ごとに処理(修正・補正)を変更する必要すら生じます。例えば「1」や「イ」など、その形状が比較的単純な数字・文字は、画像を二値化して処理した方が認識率が高まるのではないかと実験して感じました(あくまでも、僕自身の実験結果からの判断です。ご注意ください。ただ、僕自身は、この目で見た実験の結果を信じて、推論対象とする数字や文字ごとに処理を分けて実装しています)。
2年前の僕は、学習用画像を作成する段階で、解答用紙の『解答欄の切り出し』にはなんとか成功したものの、解答欄の中の『解答そのものの切り出し』に失敗(例えば、同じ「ア」でも、「つ」と「ノ」の組み合わせのように見える「ア」の場合、機械は「ア」ではなく、「つ」と「ノ」のように別々に輪郭検出)してしまい、高品質な学習用画像が作れませんでした。もちろん、同じ理由から、思うような推論用画像も、生成できるわけがなく・・・
様々に試行を繰り返しましたが、結果としては、自作ソフトへの自動採点機能の搭載を断念せざるを得ませんでした。ただ、自分がとった方法では『ダメ』だという事実と、無加工状態の大量の手書きのカタカナ文字「アイウエオ」、数字の「0~9」、記号の「 〇 と × 」の画像データが残りました。今回の再チャレンジで、これらのデータが役に立ったことは言うまでもありません。もちろん、『ダメだった』という貴重な経験も、今回はその方向に進んではいけないという、良い指標となりました。
まとめると、良い学習モデルを作成するためには、学習モデルを作成するために使用する学習用画像そのものの品質を、高品質化・・・ と言うか、学習用画像の作成方法と、推論用画像の作成方法の差異をなくし、縦横 28 ピクセルの画像とする過程で、数字・文字・記号の大きさを揃え、画像中の位置を中心化し、シミや汚れの除去等々、徹底した修正(補正)を行って、機械が学習しやすく、かつ、判定もより確実に行えるよう、推論用の画像データも学習用データと同じ処理を行って作成したものにする等、ヒトの側で、学びやすい環境と推論しやすい環境を整えてあげることが、ライブラリ云々以前に、他のどんな要素よりも重要で大切なことなんだということが(僕がそう思うだけかもしれませんが)自分なりに納得できた、機械学習で使用する学習&推論用データ作成に関する最終的な結論です。
以下、僕自身が行った画像の切り出しと修正(補正)方法の一部を紹介します。
2.解答欄の切り出し
2年前は、64 ビット環境で作業したのですが、今回は敢えて 32 ビット環境での機械学習にチャレンジすることにしました。理由は、ただひとつ。自分のアプリケーションがいつも利用している組み込み用の Python 環境である Embeddable Python が 32 ビットバージョンであるためです。
利用するライブラリも、2年前の keras ではなく、scikit-learn に変更しました。2年前は、見様見真似で作ったニューラルネットワークを用いましたが、今回は特徴量を抽出する手法(HOG + LBP)を用いて学習モデルを作成し、推論に利用しました。
世の中の流れには、完全に逆行しているような気がしますが、『正しく自動採点できた!』という結果が出せれば、方法は何でも良いと考え、ニューラルネットワークのことは忘れることにしました。
『機械学習』と言えば、即、ニューラルネットワークだと思い込んでいた・・・2年前の僕に、今は・・・、「そんなに短絡的に、思い込まなくても、よかったんじゃないか・・・」って言ってあげたい気もします。
それより、学習用データや、推論用データを、しっかり作ることの方が、大切だよ・・・って。
データが正しければ、ライブラリは間違えない。
データに誤りがあれば、ライブラリも間違える。
ライブラリの性能を、最高に引き出せるデータを作ることが、
機械学習では、きっと・・・
いちばん、大切な、こと・・・ なんだよ って。
それが、今回のチャレンジを終えて、感じた・・・ 僕自身の偽りのない、正直な、思いです。
プログラムに自動採点機能を実装するためには、文字を認識し、推論(判定)する処理が必要です。そのため、最初に行わなければならないのが解答用紙画像から解答欄矩形を切り出す処理です。これには次のようなスクリプトを使用しました。
# 解答用紙から解答欄矩形を切り出すスクリプト(AnswerColumnCutter.py)
import cv2
import numpy as np
import os
from glob import glob
# 入出力フォルダ
input_folder = r'.\MyData' # 解答用紙画像のあるフォルダ
output_folder = r'.\ACData' # 切り出した解答欄の保存先
os.makedirs(output_folder, exist_ok=True)
# 対象画像の拡張子
image_extensions = ['*.png', '*.jpg', '*.jpeg']
image_files = []
for ext in image_extensions:
image_files.extend(glob(os.path.join(input_folder, ext)))
# 解答欄サイズの閾値(調整可能)
min_width = 100
min_height = 50
max_width = 800
max_height = 400
# 保存ファイルの連番用カウンタ
save_index = 1
# 処理ループ
for image_path in image_files:
filename = os.path.basename(image_path)
# 画像読み込み(日本語ファイル名に対応)
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if image is None:
print(f'読み込み失敗: {filename}')
continue
# グレースケール変換と二値化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
_, binary = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 輪郭検出(内枠も含める)
contours, _ = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
area = cv2.contourArea(cnt)
if area < 1000:
continue
approx = cv2.approxPolyDP(cnt, 0.02 * cv2.arcLength(cnt, True), True)
if len(approx) == 4:
x, y, w, h = cv2.boundingRect(approx)
if min_width <= w <= max_width and min_height <= h <= max_height:
roi = image[y:y+h, x:x+w]
save_name = f'answer_{save_index:04d}.png'
save_path = os.path.join(output_folder, save_name)
cv2.imencode('.png', roi)[1].tofile(save_path)
save_index += 1
print(f'Saving complete! {save_index - 1} items saved.')実行結果は、次の通りです。数字・文字(記号)は、この記事用にすべて自分で書きました。
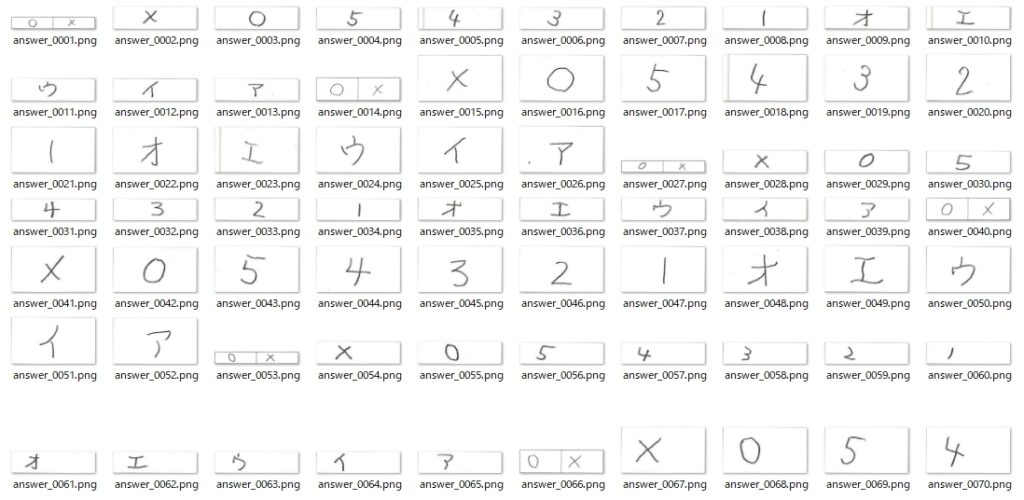
これでOKかというと、実はOKではありません。解答用紙の画像から切り出した解答欄の画像1枚1枚をよく見ると・・・

文字の他に、解答欄の矩形の一部が見えます。最終的には輪郭検出で文字の部分のみを見つけて、文字のみを切り出すので影響はないようにも思いますが、より確実に文字を切り出すために不安要素はすべて準備段階で取り除いておくことにしました。
上のスクリプトに、枠線(罫線)を除去する機能を追加します。
# 解答欄矩形の枠線を消す処理を追加したスクリプト(AnswerColumnCutter2.py)
import cv2
import numpy as np
import os
from glob import glob
# 入出力フォルダ
input_folder = r'.\MyData' # 解答用紙画像のあるフォルダ
output_folder = r'.\ACData' # 切り出した解答欄の保存先
os.makedirs(output_folder, exist_ok=True)
# 対象画像の拡張子
image_extensions = ['*.png', '*.jpg', '*.jpeg']
image_files = []
for ext in image_extensions:
image_files.extend(glob(os.path.join(input_folder, ext)))
# 解答欄サイズの閾値(調整可能)
min_width = 100
min_height = 50
max_width = 800
max_height = 400
# ROIの枠線除去用パディング(上下左右のピクセル数)※状況によっては、個別に指定することも可とした
Pad = 10 # 画像の状態に応じて適宜修正する
padding_top = Pad
padding_bottom = Pad
padding_left = Pad
padding_right = Pad
# 保存ファイルの連番用カウンタ
save_index = 1
# 処理ループ
for image_path in image_files:
filename = os.path.basename(image_path)
# 画像読み込み(日本語ファイル名対応)
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if image is None:
print(f'読み込み失敗: {filename}')
continue
# グレースケール変換と二値化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
_, binary = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 輪郭検出(内枠も含める)
contours, _ = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
area = cv2.contourArea(cnt)
if area < 1000:
continue
approx = cv2.approxPolyDP(cnt, 0.02 * cv2.arcLength(cnt, True), True)
if len(approx) == 4:
x, y, w, h = cv2.boundingRect(approx)
if min_width <= w <= max_width and min_height <= h <= max_height:
roi = image[y:y+h, x:x+w].copy()
# 枠線を削除(上下左右 padding ピクセルを白で塗りつぶす)
roi[:padding_top, :] = 255 # 上
roi[-padding_bottom:, :] = 255 # 下
roi[:, :padding_left] = 255 # 左
roi[:, -padding_right:] = 255 # 右
save_name = f'answer_{save_index:04d}.png'
save_path = os.path.join(output_folder, save_name)
cv2.imencode('.png', roi)[1].tofile(save_path)
save_index += 1
print(f'Saving complete! {save_index - 1} items saved.')結果は、次の通りです。

では、これで OK かというと、まだ問題があります。問題の1つが画像中の黒や灰色の汚れです。

これらも出来る限り、除去できるよう解答欄の切り出しスクリプトを改良します。
'''
解答欄矩形の枠線を消す処理を追加したスクリプト(AnswerColumnCutter2.py)に
黒点も削除する処理を追加したAnswerColumnCutter3.py
'''
import cv2
import numpy as np
import os
from glob import glob
# 入出力フォルダ
input_folder = r'.\MyData' # 解答用紙画像のあるフォルダ
output_folder = r'.\ACData' # 切り出した解答欄の保存先
os.makedirs(output_folder, exist_ok=True)
# 対象画像の拡張子
image_extensions = ['*.png', '*.jpg', '*.jpeg']
image_files = []
for ext in image_extensions:
image_files.extend(glob(os.path.join(input_folder, ext)))
# 解答欄サイズの閾値(調整可能)
min_width = 100
min_height = 50
max_width = 800
max_height = 400
# ROIの枠線除去用パディング(上下左右のピクセル数)
Pad = 5
padding_top = Pad
padding_bottom = Pad
padding_left = Pad
padding_right = Pad
# 保存ファイルの連番用カウンタ
save_index = 1
# 処理ループ
for image_path in image_files:
filename = os.path.basename(image_path)
# 画像読み込み(日本語ファイル名対応)
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if image is None:
print(f'読み込み失敗: {filename}')
continue
# グレースケール変換と二値化(binaryにはblurされた白黒反転画像が入る)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
_, binary = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 輪郭検出(内枠も含める)
contours, _ = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
area = cv2.contourArea(cnt)
if area < 1000:
continue
approx = cv2.approxPolyDP(cnt, 0.02 * cv2.arcLength(cnt, True), True)
if len(approx) == 4:
x, y, w, h = cv2.boundingRect(approx)
if min_width <= w <= max_width and min_height <= h <= max_height:
# imageは元のカラー画像(輪郭検出に使用したbinaryではないことに注意する!)
roi = image[y:y+h, x:x+w].copy()
# 枠線を削除(上下左右 padding ピクセルを白で塗りつぶす)
roi[:padding_top, :] = 255 # 上
roi[-padding_bottom:, :] = 255 # 下
roi[:, :padding_left] = 255 # 左
roi[:, -padding_right:] = 255 # 右
# --- シミやノイズを除去する処理を追加 ---
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
# 小さな黒点や灰色点を除去(モルフォロジー開演算)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
opened = cv2.morphologyEx(gray_roi, cv2.MORPH_OPEN, kernel, iterations=1)
# 小さな輪郭(ノイズ)を除去
cleaned = opened.copy()
contours_noise, _ = cv2.findContours(255 - opened, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours_noise:
if cv2.contourArea(c) < 150: # 小さな汚れを消す
cv2.drawContours(cleaned, [c], -1, 255, -1)
# グレースケール→カラーに戻す
cleaned_color = cv2.cvtColor(cleaned, cv2.COLOR_GRAY2BGR)
roi = cleaned_color
# 保存
save_name = f'answer_{save_index:04d}.png'
save_path = os.path.join(output_folder, save_name)
cv2.imencode('.png', roi)[1].tofile(save_path)
save_index += 1
print(f'Saving complete! {save_index - 1} items saved.')結果は、次の通り。

しかし、まだ問題が残っています。それは・・・

この灰色の直線のようなものが入る理由がわからないのですが、現実問題として、僕が利用している複合機でスキャンしたJpeg画像には時折り、このような直線が入ってしまいます(もっと黒い線になることもあります)。理由はともあれ、これを除去できるよう、新しくスクリプトを作成しました。解答用紙から切り出して保存した解答欄画像に対して処理を行っていることにご注意ください。
'''
縦線は画像の高さに匹敵する長さ、
横線は画像の幅に匹敵する長さを持つ直線のみを除去するスクリプト。
image.shape を使って幅 (width) と高さ (height) を取得。
縦線: 傾き ≒ 垂直(3度以内)かつ 長さ ≥ 高さの 80%。
横線: 傾き ≒ 水平(3度以内)かつ 長さ ≥ 幅の 80%。
'''
import cv2
import numpy as np
import os
from glob import glob
# 処理対象フォルダ
folder = r'.\ACData' # 解答欄画像として保存したデータを修正しています
image_extensions = ['*.png', '*.jpg', '*.jpeg']
image_paths = []
for ext in image_extensions:
image_paths.extend(glob(os.path.join(folder, ext)))
for image_path in image_paths:
# 日本語ファイル名対応で画像読み込み
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if image is None:
print(f"読み込み失敗: {image_path}")
continue
height, width = image.shape[:2]
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# エッジ検出(低い閾値で薄い線も対象)
edges = cv2.Canny(gray, threshold1=20, threshold2=80, apertureSize=3)
# HoughLinesPで直線検出
lines = cv2.HoughLinesP(
edges,
rho=1,
theta=np.pi / 180,
threshold=50,
minLineLength=30,
maxLineGap=5
)
# 線を描画するマスク
mask = np.zeros_like(gray)
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
dx = x2 - x1
dy = y2 - y1
length = np.sqrt(dx ** 2 + dy ** 2)
# 傾きが垂直に近く、高さに匹敵する長さを持つ線
if (abs(dx) < 1e-5 or abs(dy / dx) > 20) and length >= height * 0.8:
cv2.line(mask, (x1, y1), (x2, y2), 255, thickness=2)
# 傾きが水平に近く、幅に匹敵する長さを持つ線
elif (abs(dy) < 1e-5 or abs(dx / dy) > 20) and length >= width * 0.8:
cv2.line(mask, (x1, y1), (x2, y2), 255, thickness=2)
# マスクされた領域を修復(inpainting)
if np.count_nonzero(mask) > 0:
inpainted = cv2.inpaint(image, mask, inpaintRadius=3, flags=cv2.INPAINT_TELEA)
else:
inpainted = image # 線が見つからなければそのまま
# 上書き保存(日本語ファイル名対応)
cv2.imencode('.png', inpainted)[1].tofile(image_path)
print(f'修正完了: {os.path.basename(image_path)}')
print("全ファイルの処理が完了しました。")結果は、次の通り。

これでようやく安心して使える解答欄の切り出し画像が準備できました!
3.解答欄からの解答の切り出し
次は、解答の切り出しです。2年前はここで失敗しました。今回、あらためて失敗の原因を考えてみると、2年前も輪郭検出までは成功したのですが、輪郭検出できた場合に、『その後の処理をどう行うか?』という部分で(2年前は)工夫が足りなかったことに気づきました。
それはどういうことか、説明します。
まず、輪郭検出です。わかりやすさのために、検出した部分を赤枠で囲って示します。
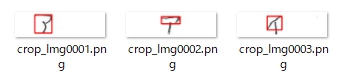
文字全体が一筆書きのように描かれていれば正しく検出できるのですが、文字を構成する部品が独立して描かれている場合には、文字全体を正しく検出できていません。
今回は、『輪郭検出できた部分を組み合わせて出来る範囲の周囲を文字と見なして切り取る』という方法を用いてみました。次の画像にその結果を示します。
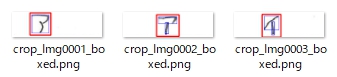
左から順に拡大して見てみます。

拡大すると、文字を構成する部品が完全に繋がっているわけではないようです。が、輪郭検出自体には成功しています。輪郭検出に使用した OpenCV は本当に優秀なライブラリです。
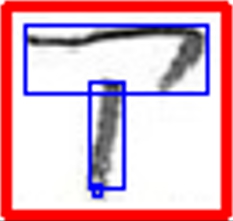
こちらの「ア」は、3つの輪郭の範囲を合わせて文字として認識。切り出しに成功しました!

こちらの「イ」は、2つの輪郭の範囲を合わせて文字として認識。切り出しに成功しました!
では、これで本当に OK かというと、コトはそう簡単ではありませんでした。
次のような、黒点が残ってしまった画像に対し、この切り抜き処理を実行すると・・・

次のように、左隅の黒点部分まで、文字を構成する部品の一部と見なし、(ヒトから見れば)誤った範囲を文字として切り出してしまいます。
機械的には、極めて正確に、ヒトの命令に忠実に、正しい処理を行っているわけですが・・・

この問題に対しては、『検出した輪郭の中から「面積の大きな輪郭」(最大輪郭の面積の10%以上のもの)をすべて組み合わせた領域を文字領域とみなし、その周囲に上下左右10ピクセルの白い余白を付けて切り抜く』方法で対応しました。次がそのスクリプトです。
import cv2
import numpy as np
import os
from glob import glob
# 入出力フォルダのパス(必要に応じて変更)
input_folder = r'.\MyInputFolder' # ←処理対象フォルダ
output_folder = r'.\Crop04_Pic' # ←保存先フォルダ
os.makedirs(output_folder, exist_ok=True)
# 画像拡張子に対応
image_extensions = ['*.png', '*.jpg', '*.jpeg']
image_files = []
for ext in image_extensions:
image_files.extend(glob(os.path.join(input_folder, ext)))
# 処理ループ
for image_path in image_files:
filename = os.path.basename(image_path)
# 日本語ファイル名対応の読み込み
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if image is None:
print(f'読み込めません: {filename}')
continue
# グレースケール & 二値化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 縦線除去処理(細い直線ノイズを消す)
vertical_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 30)) # 縦方向に長いカーネル
vertical_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, vertical_kernel, iterations=1)
binary_cleaned = cv2.subtract(binary, vertical_lines)
# 輪郭検出(外側のみ)
contours, _ = cv2.findContours(binary_cleaned, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if not contours:
print(f'輪郭なし: {filename}')
continue
# 最大輪郭の面積を基準に、大きな輪郭(最大輪郭の10%以上)を抽出
max_area = max([cv2.contourArea(c) for c in contours])
area_threshold = 0.1 * max_area
large_contours = [c for c in contours if cv2.contourArea(c) >= area_threshold]
if not large_contours:
print(f'大きな輪郭なし: {filename}')
continue
# 大きな輪郭群の外接矩形の結合領域を求める
x_vals = []
y_vals = []
x2_vals = []
y2_vals = []
for cnt in large_contours:
x, y, w, h = cv2.boundingRect(cnt)
x_vals.append(x)
y_vals.append(y)
x2_vals.append(x + w)
y2_vals.append(y + h)
combined_x = min(x_vals)
combined_y = min(y_vals)
combined_x2 = max(x2_vals)
combined_y2 = max(y2_vals)
# 余白を加える(画像範囲内に収める)
pad = 10
x1 = max(combined_x - pad, 0)
y1 = max(combined_y - pad, 0)
x2 = min(combined_x2 + pad, image.shape[1])
y2 = min(combined_y2 + pad, image.shape[0])
cropped = image[y1:y2, x1:x2]
# 保存(PNG形式、元のファイル名と同じ名前)
save_path = os.path.join(output_folder, os.path.splitext(filename)[0] + '.png')
cv2.imencode('.png', cropped)[1].tofile(save_path)
print(f'Saving complete!')次のように、構成部品が離れている「ア」であっても(思った通りに)切り出すことに成功しました!

このようにして切り出した画像から、次に機械学習による学習モデルを作るための学習用データを準備します。今回は、scikit-learn の HOG特徴量抽出を利用するので、解答欄から切り出した手書き数字・文字・記号の画像を、手書き数字や単純な記号認識に適しているとされ、MNISTデータセット(手書き数字認識の標準データセット)で採用されているサイズである 28 × 28 ピクセルの画像に変換します。
次に、その変換方法について説明します。
4.学習用データを作る
機械学習の学習用データの作成方法として、僕が行ったことが正しいかどうかは、この記事をお読みになった方ご自身でご判断ください。僕自身は、機械学習を理論的な背景を含め、基礎からきちんと学んだことはありませんし、今回利用した HOG( Histogram of Oriented Gradients )+ LBP(Local Binary Patterns )という特徴量抽出手法についてもその詳細な部分まで理解しているわけではないからです。そのような点を御理解の上、記事をお読みいただけましら幸いです。
学習用データは、予め、「ア」なら「ア」だけを、正解ラベル名を付けたフォルダに分類しておきます。
これを処理して、次に示すような 28 × 28 ピクセルの画像を作成します。
この 28 × 28 ピクセルの画像を作成する過程で、必要に応じて、補正処理をかけ、機械学習を行うために必要十分と思われる画像となるよう準備します。ここで言う必要十分とは、機械に見せる画像内の推論対象の「大きさ・位置・傾き・濃さ」等をヒト基準で一定の範囲に収まるように、予め個々の画像を学習前・推論前に調整し、学習時も推論時も同じ処理の過程を経て作成された・・・言わば「ブレていない」画像(データ)を機械が見れる = 機械は余計な気遣いなどできないので、同じ条件下で作成された画像を見て、機械は「その特徴量抽出のみに専念できるようにする」という意味です。
繰り返しになりますが、学習用画像を作成する時だけでなく、推論用画像を作成する際も、学習用画像を作成する際に行ったのと同じ処理をそっくりそのまま行って、機械が常に同じ(安定した)条件下で推論(手書き文字の認識作業)を実行できるようにするという部分も非常に重要だと考えます。
処理に使用したライブラリの一覧です。
import cv2
import numpy as np
import os
from glob import glob
import re
import joblib
from skimage.feature import hog, local_binary_pattern文字を傾きを均一化し、分類器がより正確な特徴を学習できるようにするために次の関数を用意。
def deskew(img):
m = cv2.moments(img)
if abs(m["mu02"]) < 1e-2:
return img.copy()
skew = m["mu11"] / m["mu02"]
M = np.float32([[1, skew, -0.5 * 28 * skew], [0, 1, 0]])
return cv2.warpAffine(img, M, (28, 28), flags=cv2.INTER_NEAREST | cv2.WARP_INVERSE_MAP, borderValue=255)学習用画像データの読み込み処理部分は割愛します。
次が学習用画像の処理ループ部分です。任意に指定した学習用データを保存したフォルダ内の全画像について処理を以下の通り実行します。補正処理の実行内容は、各々のコメントをご参照ください。
index = 1
light_text_threshold = 215 # 文字の視認性の向上(薄いと判断する閾値)
pad = 10 # 周囲に設定する余白
clip_limit = 0.3 # コントラストの過剰な増加を防ぐための制限値。ごく弱く設定。
tile_grid_size = 2 # 画像を分割するグリッドのサイズ。ごく小さめに設定
# 学習用データの数だけループする
for image_path in image_files:
image = imread_utf8(image_path)
if image is None:
continue
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
'''
小さすぎる or 明るすぎる成分は除外して、画像の連結成分を解析し、有効な成分のみを抽出、
適切な境界を決めて、その範囲を文字として切り出す処理。
'''
num_labels, labels, stats, centroids = cv2.connectedComponentsWithStats(binary, connectivity=8)
min_area = 50
brightness_threshold = 200
valid_components = []
for i in range(1, num_labels):
x, y, w, h, area = stats[i]
if area < min_area:
roi = gray[y:y+h, x:x+w]
mean_val = cv2.mean(roi)[0]
if mean_val > brightness_threshold:
continue
valid_components.append((x, y, w, h))
if not valid_components:
cropped = np.full((28, 28, 3), 0, dtype=np.uint8)
else:
x_vals = [x for x, y, w, h in valid_components]
y_vals = [y for x, y, w, h in valid_components]
x2_vals = [x + w for x, y, w, h in valid_components]
y2_vals = [y + h for x, y, w, h in valid_components]
combined_x = min(x_vals)
combined_y = min(y_vals)
combined_x2 = max(x2_vals)
combined_y2 = max(y2_vals)
x1 = max(combined_x - pad, 0)
y1 = max(combined_y - pad, 0)
x2 = min(combined_x2 + pad, image.shape[1])
y2 = min(combined_y2 + pad, image.shape[0])
cropped = image[y1:y2, x1:x2]
'''
明るい文字のコントラストを調整し、認識しやすくする処理。白飛びを防ぎ、画像の視認性を改善する。
'''
trimmed_gray = cv2.cvtColor(cropped, cv2.COLOR_BGR2GRAY)
mask = (trimmed_gray >= light_text_threshold).astype(np.uint8) * 255
adjusted = trimmed_gray.copy()
adjusted[mask == 255] = np.clip(adjusted[mask == 255] - 20, 0, 255)
# 輪郭検出
contours, _ = cv2.findContours(adjusted, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if contours:
# CLAHEを適用
clahe = cv2.createCLAHE(clipLimit=clip_limit, tileGridSize=(tile_grid_size, tile_grid_size))
trimmed_gray = clahe.apply(trimmed_gray)
# 調整した結果、ここではぼかし無しと同等にしておくことにした。必要であればより強く設定。
trimmed_blur = cv2.GaussianBlur(trimmed_gray, (1, 1), 0)
# 単純な形であれば二値化して処理する
if label in ["イ", "1"]:
_, trimmed_thresh = cv2.threshold(trimmed_blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
h_trim, w_trim = trimmed_thresh.shape[:2]
else:
h_trim, w_trim = trimmed_blur.shape[:2]
scale = 20.0 / max(h_trim, w_trim)
new_w = int(w_trim * scale)
new_h = int(h_trim * scale)
if label in ["イ", "1"]:
resized = cv2.resize(trimmed_thresh, (new_w, new_h), interpolation=cv2.INTER_AREA)
else:
resized = cv2.resize(trimmed_blur, (new_w, new_h), interpolation=cv2.INTER_AREA)
# 学習用データから切り出した文字を28×28ピクセルのキャンバスの中央に配置する。
# 入力画像を統一されたサイズに整える。
canvas = np.full((28, 28), 255, dtype=np.uint8)
x_offset = (28 - new_w) // 2
y_offset = (28 - new_h) // 2
canvas[y_offset:y_offset + new_h, x_offset:x_offset + new_w] = resized
# 文字の傾きを均一化する
deskewed = deskew(canvas)
# - 画像のモーメント(統計量) を計算し、文字の重心(中心)を求めてセンタリングする処理
M = cv2.moments(deskewed)
if M["m00"] != 0:
cx = int(M["m10"] / M["m00"])
cy = int(M["m01"] / M["m00"])
# 画像を重心基準で移動
shift_x = 14 - cx
shift_y = 14 - cy
trans_mat = np.float32([[1, 0, shift_x], [0, 1, shift_y]])
deskewed = cv2.warpAffine(deskewed, trans_mat, (28, 28), flags=cv2.INTER_AREA, borderValue=255)
canvas = deskewed
# 画像の標準化
mean, std = cv2.meanStdDev(canvas)
std = std[0][0] if std[0][0] > 1e-5 else 1.0
# 画像の正規化
norm_img = (canvas.astype(np.float32) - mean[0][0]) / std
norm_img = cv2.normalize(norm_img, None, 0, 255, cv2.NORM_MINMAX)
canvas = norm_img.astype(np.uint8)
else:
# - 有効な画像データがない場合は、白色の 28×28 画像を作成。
canvas = np.full((28, 28), 255, dtype=np.uint8)
# png形式で保存する
save_path = os.path.join(output_folder, f"crop_Img{index:04d}.png")
is_written = cv2.imencode(".png", canvas)[1]
with open(save_path, "wb") as f:
f.write(is_written)
index += 1png 形式での保存を選択したことにも理由があります。データを間引いて保存する Jpeg 形式よりも、可逆圧縮を使用し、元の画像データを損失なく保存(ピクセル単位での正確性を維持)できる png 形式の方が機械学習には適しているからです。
こうして、次のような学習用データが完成しました。
こんな小さな画像ですが、ここまで到達するには・・・ 本当に長い時間と・・・ 試行錯誤が必要でした。
5.学習モデルを作る
任意のフォルダ内(ここでは trimed フォルダ)に、正解ラベルの名前を付けたフォルダを必要数分準備して、上の4で作成した学習データを格納しておきます。
そして、学習モデルを作成するスクリプトを実行します。例としてカタカナ「アイウエオ」の推論用の学習用データ作成スクリプトを示します。
import os
import cv2
import numpy as np
import joblib
from skimage.feature import hog, local_binary_pattern
from sklearn.decomposition import IncrementalPCA
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report
LABELS = {'ア': 0, 'イ': 1, 'ウ': 2, 'エ': 3, 'オ': 4}
IMG_SIZE = (28, 28)
LBP_RADIUS = 1
LBP_POINTS = 8 * LBP_RADIUS
LBP_METHOD = 'uniform'
DATASET_DIR = r".\aiueo\Trimed"
def extract_features(image):
image = cv2.GaussianBlur(image, (3, 3), 0)
hog_features = hog(image, pixels_per_cell=(4, 4), cells_per_block=(2, 2), feature_vector=True)
lbp = local_binary_pattern(image, LBP_POINTS, LBP_RADIUS, method=LBP_METHOD)
lbp_hist, _ = np.histogram(lbp.ravel(), bins=np.arange(0, LBP_POINTS + 3), range=(0, LBP_POINTS + 2))
lbp_hist = lbp_hist.astype("float32")
lbp_hist /= (lbp_hist.sum() + 1e-6)
return np.concatenate([hog_features, lbp_hist])
def load_dataset_in_batches(root_dir, max_samples_per_label=7000, batch_size=500, show_progress=False):
label_dirs = [d for d in os.listdir(root_dir) if os.path.isdir(os.path.join(root_dir, d)) and d in LABELS]
for label_name in label_dirs:
label_path = os.path.join(root_dir, label_name)
files = os.listdir(label_path)
np.random.shuffle(files)
batch_features = []
batch_labels = []
total_files = min(len(files), max_samples_per_label)
if show_progress:
print(f"\n[{label_name}] 読み込み開始 (最大{total_files}枚)")
for i, file in enumerate(files):
if i >= max_samples_per_label:
break
file_path = os.path.join(label_path, file)
image = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)
if image is None or image.shape != IMG_SIZE:
continue
feat = extract_features(image)
batch_features.append(feat)
batch_labels.append(LABELS[label_name])
if show_progress and ((i + 1) % max(1, total_files // 20) == 0 or (i + 1) == total_files):
progress = (i + 1) / total_files * 100
print(f" {i+1}/{total_files}枚完了 ({progress:.1f}%)")
if len(batch_features) >= batch_size:
yield np.array(batch_features, dtype=np.float32), np.array(batch_labels, dtype=np.int32)
batch_features = []
batch_labels = []
if batch_features:
yield np.array(batch_features, dtype=np.float32), np.array(batch_labels, dtype=np.int32)
# 特徴抽出
print("\n[特徴量収集]")
all_features = []
all_labels = []
for batch_features, batch_labels in load_dataset_in_batches(DATASET_DIR, show_progress=True):
all_features.append(batch_features)
all_labels.append(batch_labels)
X_all = np.vstack(all_features)
y_all = np.hstack(all_labels)
# PCA学習
print("\n[PCA学習開始]")
n_components = 200
pca = IncrementalPCA(n_components=n_components)
pca.fit(X_all)
# 特徴量変換
X_pca = pca.transform(X_all)
# データ分割
print("\n[データ分割]")
X_train, X_test, y_train, y_test = train_test_split(X_pca, y_all, test_size=0.2, random_state=42)
# 間違えてもとにかく判定
# model = SVC(kernel='rbf', gamma='scale', C=10)
# 指定正解率未満の場合は「判定不可能」と表示
# この指定着きでビルドしていない場合、判定スクリプトを実行すると「handwritten_digit_0.png の推定結果: モデルが確率推定に未対応」と表示される
model = SVC(kernel='rbf', C=10, probability=True)
'''
# ハイパーパラメータ探索 -> 1, 10, 50, 100 の中から探す。結果、C=10 だった!
print("\n[グリッドサーチ]")
param_grid = {'C': [1, 10, 50, 100]}
svc = SVC(kernel='rbf', gamma='scale')
clf = GridSearchCV(svc, param_grid, cv=3)
clf.fit(X_train, y_train)
print(f"最適なCの値: {clf.best_params_['C']}")
model = clf.best_estimator_
'''
# モデル学習(これが抜けているとエラーになる!)
model.fit(X_train, y_train)
# 評価
print("\n[テストデータで評価]")
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=list(LABELS.keys())))
# 確率推定
# y_proba = model.predict_proba(X_test) # 各クラスの確率を取得
# print(y_proba[:5]) # 最初の5つの予測結果の確率を表示
# モデル保存
print("\n[モデル保存]")
joblib.dump(model, "aiueo_svm_model.pkl")
joblib.dump(pca, "aiueo_pca.pkl")
print("[保存完了]")実行結果は、次の通りです。
[特徴量収集]
[ア] 読み込み開始 (最大2511枚)
125/2511枚完了 (5.0%)
・・・(省略)・・・
2511/2511枚完了 (100.0%)
[イ] 読み込み開始 (最大2575枚)
128/2575枚完了 (5.0%)
・・・(省略)・・・
2575/2575枚完了 (100.0%)
[ウ] 読み込み開始 (最大2636枚)
131/2636枚完了 (5.0%)
・・・(省略)・・・
2636/2636枚完了 (100.0%)
[エ] 読み込み開始 (最大2582枚)
129/2582枚完了 (5.0%)
・・・(省略)・・・
2582/2582枚完了 (100.0%)
[オ] 読み込み開始 (最大2602枚)
130/2602枚完了 (5.0%)
・・・(省略)・・・
2602/2602枚完了 (100.0%)
[PCA学習開始]
[データ分割]
[テストデータで評価]
precision recall f1-score support
ア 1.00 1.00 1.00 516
イ 1.00 1.00 1.00 538
ウ 1.00 1.00 1.00 537
エ 1.00 1.00 1.00 499
オ 1.00 1.00 1.00 492
accuracy 1.00 2582
macro avg 1.00 1.00 1.00 2582
weighted avg 1.00 1.00 1.00 2582上のスクリプトで、
X_train, X_test, y_train, y_test = train_test_split(X_pca, y_all, test_size=0.2, random_state=42)としていますので、データセットの 80% を学習用 (X_train, y_train)、20% をテスト用 (X_test, y_test) に分割していることになります。
スクリプトを実行する度に、テスト用の20%の内容は変化しますので [テストデータで評価] の部分は変化するはずですが、何回か、実行した結果悪くても 0.99 で、どの文字についても、ほとんど 1.00 から変化がありませんでした。
ちなみに、もう1回実行してみると・・・
[テストデータで評価]
precision recall f1-score support
ア 1.00 1.00 1.00 516
イ 1.00 1.00 1.00 538
ウ 1.00 1.00 1.00 537
エ 1.00 1.00 1.00 499
オ 1.00 1.00 1.00 492
accuracy 1.00 2582
macro avg 1.00 1.00 1.00 2582
weighted avg 1.00 1.00 1.00 2582もう1回、実行してみました。
[テストデータで評価]
precision recall f1-score support
ア 1.00 1.00 1.00 516
イ 0.99 1.00 1.00 538
ウ 1.00 1.00 1.00 537
エ 1.00 1.00 1.00 499
オ 0.99 0.99 0.99 492
accuracy 1.00 2582
macro avg 1.00 1.00 1.00 2582
weighted avg 1.00 1.00 1.00 2582「イ」と「オ」が 0.99 ですが、それでも 0.99 です。
・適合率 (precision) が ほぼ 1.00 なので、正解ラベルを正しく予測できています。
・再現率 (recall) が ほぼ 1.00 なので、実際の正解ラベルを確実に検出できています。
・F1スコア が ほぼ 1.00 なので、誤分類はありません。
で、総合精度 (accuracy) が 1.00 ですから、今回、作成した学習モデルはテストデータに対して完璧に近い性能を発揮していると言ってよいと思います。ただ、ただ、過学習に陥ってないことを祈るのみです。過学習に陥っていないことの確認するのは簡単です。未知の手書きカタカナ「アイウエオ」のデータを、この学習モデルに見せて、正しく推論できるか、テストしてあげればよいのです。
なので、未知のカタカナ文字を正しく推論できるか、テストしてみました。

テストに使用したスクリプトです。こちらは簡易版で、実際の場面では、より良い推論用データとなるよう、このスクリプトを適用する前処理として、上で学習用データを作成するために行った補正(修正)を上の5つの画像に対して行い、その後、このテスト用スクリプトを適用することになります。
# アイウエオ判定用最終版
import os
import cv2
import numpy as np
import joblib
from skimage.feature import hog, local_binary_pattern
# 定数
IMG_SIZE = (28, 28)
LBP_RADIUS = 1
LBP_POINTS = 8 * LBP_RADIUS
LBP_METHOD = 'uniform'
# 特徴量抽出関数(前処理スクリプトと整合)
def extract_features(image):
image = cv2.GaussianBlur(image, (3, 3), 0)
# HOG特徴量
hog_features = hog(
image,
pixels_per_cell=(4, 4),
cells_per_block=(2, 2),
feature_vector=True
)
# LBP特徴量(ヒストグラム)
lbp = local_binary_pattern(image, LBP_POINTS, LBP_RADIUS, method=LBP_METHOD)
lbp_hist, _ = np.histogram(
lbp.ravel(),
bins=np.arange(0, LBP_POINTS + 3),
range=(0, LBP_POINTS + 2)
)
lbp_hist = lbp_hist.astype("float")
lbp_hist /= (lbp_hist.sum() + 1e-6)
return np.concatenate([hog_features, lbp_hist])
# モデルとPCA読み込み
model = joblib.load("aiueo_svm_model.pkl")
pca = joblib.load("aiueo_pca.pkl")
# 推論対象ファイル(日本語ファイル名対応)
file_list = [f"katakana_sample_{i+1}.jpg" for i in range(5)]
# 推論実行
for file_name in file_list:
if not os.path.exists(file_name):
print(f"ファイルが存在しません: {file_name}")
continue
file_path = os.path.abspath(file_name)
# 日本語パス・ファイル名対応
image = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)
if image is None:
print(f"読み込み失敗: {file_name}")
continue
# サイズ変換(28x28)と前処理との整合
image_resized = cv2.resize(image, IMG_SIZE, interpolation=cv2.INTER_AREA)
# 特徴量 → PCA変換 → SVM予測
features = extract_features(image_resized)
features_pca = pca.transform([features])
prediction = model.predict(features_pca)
print(f"{file_name} の推定結果: {prediction[0]}")学習モデル( aiueo_svm_model.pkl と aiueo_pca.pkl )は、スクリプトと同じ場所に置いて実行します。結果は、次の通りです。
katakana_sample_1.jpg の推定結果: 0
katakana_sample_2.jpg の推定結果: 1
katakana_sample_3.jpg の推定結果: 2
katakana_sample_4.jpg の推定結果: 3
katakana_sample_5.jpg の推定結果: 4よかった・・・。過学習には陥っていないようです。
あとは・・・ Delphi の P4D( Python4Delphi )を使って、僕の手書き答案採点補助プログラム AC_Reader で、このスクリプトを実行すれば・・・
自動採点を、実現できます。
6.まとめ
機械学習で良い学習モデルを作るには、学習用データ作りをしっかり行うことが大切。文字の大きさ・位置(配置)・濃さ等の調節、及び、画像中の不要な点(シミ)や汚れを除去する等々して、個々にブレのない安定した学習用データ(もちろん、推論用データも同様)を作成、これを元に学習モデルを作成すれば上に示した結果を出せるはずです。
今回の記事で紹介した内容は、テストを繰り返し行って、問題点を洗い出し、それら問題点を1つ1つ丁寧に解決した結果です。絶対に『あきらめない』こと、もしかしたら、それがいちばん重要で大切なポイントかもしれません。
7.お願いとお断り
このサイトの内容を利用される場合は、自己責任でお願いします。記載した内容(プログラムを含む)を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。