手書きカタカナ文字をPCに認識させる(その②)
前回の記事では、ETL文字データベースのカタカナ5文字(アイウエオ)+独自に収集した手書きカタカナ文字(アイウエオ各450~650文字)を元に機械学習で作成した学習モデルを用いて、答案の解答欄に書かれた手書きカタカナ1文字(ア~オのいずれか)の識別に挑戦。自分なりに最善を尽くしたと判断した段階での実際の正解率は91%・・・。
今回は、前回とは別の方法で再チャレンジ。前回と同じデータでテストして、正解率95%を達成。自分で言うのもなんだけど、これなら自動採点も可能なんじゃないか・・・と。
【今回の記事の内容】
1.分類器を検索
2.Lobeを使う
3.tflite形式で書きだす
4.書きだしたtfliteファイルをDelphiで・・・(泣)
5.Pythonで再チャレンジ
6.正解率95%!
7.まとめ
8.お願いとお断り
1.分類器を検索
どうしても手書き答案の自動採点をあきらめきれない僕は、昨日も「Delphi 分類器」をキーワードにGoogle先生にお伺いをたてた。実は「分類器」なる言葉を知ったのは最近のことで、これまで機械学習関連の検索キーワードとしてこの言葉を使ったことがなく、これでヒットするページは「ほぼ既読のリンク表示にならない」ので、当分の間、このキーワードで情報を得ようと考えたのだ。
また、Pythonではなく、Delphiとしたのは、2022年の年末からほぼ1か月間、Python関連の機械学習(ライブラリはTensolflowとkerasを使用・言うまでもなくスクリプトはもちろん、ほぼ全部写経!)で手書き文字の自動採点を実現しようと試みたが、どう頑張っても期待したような結果が出せず、とりあえずPythonスクリプト以外の「新しい情報」が「もしあれば」そちらも探してみようと思ったのだ。新しい情報があって、それがDelphi関連なら、すごく・・・ うれしいから。
で、検索すると次のページがトップに表示された。
https://blogs.embarcadero.com/ja/how-to-build-a-digit-classifier-in-tensorflow-ja/
「著者: Embarcadero Japan Support 2021年11月09日」ってコトは ・・・
(へぇー! DelphiでもMNISTできるんだ。知らなかったー!!)
(しかも、日付がどちらかと言えば 最近!)
急に興味関心が湧いて、しばらく記事を読んでみる。記事によれば、現在 TensorFlow LiteがDelphiで利用可能とのこと(気分的には TensorFlow Super Heavy の方がマッチするんだけど、残念ながらそれはないようだ)。4年前にPythonでやったのと同じ、マウスで画面に数字を書いて、それが0~9の何なのかを判定するプログラムの画像が掲載され、「プロジェクト全体をダウンロードしてテストすることができます。」とある。
( なつかしいなー あの時はGUI作りにPyQtを使って・・・ 動かすのに苦労したなー )
( 今は数字じゃなくて、オレ、「ア」 って書きたいんだけど・・・ )
( ・・・てか、肝心の学習モデルはどうやって作ってるんだろう? )
なんだかドキドキしてきた!
ページのいちばん下には「下記のリンクにアクセスしてサンプルコードをダウンロードし、実際に試してみてください。」という、うれしい案内が。
思わず、小学生のように、笑顔で、元気よく、「はぁーい」と答えたくなる。
( MNISTは別にして、学習モデルだけでもどうなってるか、確認してみよう・・・ )
結果的には、これが大正解。その存在すら知らなかった「Lobe(ローブ)」に巡り合うきっかけになろうとは・・・。
早速、リンク先からサンプルコードをダウンロード・・・
できませんでした(号泣)
404 This is not the web page you are looking for.
僕の人生は七転八倒。こんなコトには慣れっこさぁ T_T
こんなときのラッキー キーワードはもちろん「 TensorFlow-Lite-Delphi 」
Google先生、たすけてー!
今度は見事にヒット!
https://github.com/Embarcadero/TensorFlow-Lite-Delphi
DLも無事成功! プログラムソースの学習モデルの指定部分を探すと・・・
//DCUnit1.pasより一部を引用
procedure TForm1.Recognize;
var
i, X, Y: DWORD;
・・・
begin
try
var fModelFile := 'mnist3.tflite';
case rdModel.ItemIndex of
0: fModelFile := 'mnist.tflite';
1: fModelFile := 'mnist1.tflite';
2: fModelFile := 'mnist2.tflite';
3: fModelFile := 'mnist3.tflite';
end;fModelFileとあるから、まずコレが学習モデルの代入先で・・・
んで、入れてるのが『mnistX.tflite』??? あんだ? コレあ?
拡張子 tflite から想像して、学習モデルは TensorFlow Lite で作成したモノのようだ・・・
Pythonの機械学習では見たことない気がするけど。
もし、この tflite 形式で、手書きカタカナ文字の学習モデルが作成できれば・・・
お絵描き部分は、共用可能だから・・・
マウスで「ア」って書いて、PCに「これ、なぁーに?」って!! きけるカモ ↑
コレだ。コレだ。コレだ。コレだ。コレだ。僕は、コレを待っていたんだ!!
即、Google先生にお伺いをたてる。
「Delphi tflite 書き込み」 ポチ!
すると、検索結果の上から3番目くらいに、
[Lobe] Lobeで作成したモデルをTensorflow Lite形式で …
というリンクを発見。
( Lobeってナンだか知らんけど、これで学習モデルが作れる・・・ のかな? )
( で、Tensorflow Lite形式でモデルの保存ができるの・・・ かな? )
とりあえず、クリックだぁ!!
*(^_^)*♪
2.Lobeを使う
リンク先の記事・その他を読んでわかったことは、まず、Lobeは「Microsoftによって公開されている機械学習ツール」であるということ。
https://www.lobe.ai/
さらにそれは、無料でダウンロードでき、しかも完全にローカルな環境で、コードを1行も書かずに機械学習を実現する、夢のような分類器(ツール)らしい。
(こんなのがあったのか! まるで知らなかった・・・)
Lobeの使い方を紹介したWebサイトの記事を片っ端から読んで、だいたいの作業の流れを理解。次に示すような感じで、自分でも実際にやってみた。
Lobeを起動して、まず、タイトルを設定。
importするのは、もちろん画像なんだけど・・・
Datasetの説明に Import a structured folder of images. とあるから、これはつまり、「ア」の画像データは、それだけをひとつのフォルダにまとめておけば、フォルダ名でラベル付けして、それをひとつのデータセットとして読み込んでくれるってコト?
「ア」を入れるフォルダ名は、最初「a」にしようかとちょっと思ったけれど、そうすると昇順の並びが「aeiou」になることを思い出し、躊躇。
やっぱり、ここは、後できっとLoopを廻すであろうことを予想して、
「ア」→フォルダ名「0」
「イ」→フォルダ名「1」
「ウ」→フォルダ名「2」
「エ」→フォルダ名「3」
「オ」→フォルダ名「4」
とすることに決定。
モノは試し、最初は様子だけ見てみようということで、データセットはとりあえず自分で集めた手書き文字だけにして実験することに決めたんだけど、ここでデータセットの整理を思い立つ。
・・・というのは、オリジナル手書き文字画像データを作る際に、元の画像から切り抜いたカタカナ文字画像をETL文字データベースのETL1及びETL6の画像サイズに合わせ、幅64・高さ63に成形するPythonのスクリプトを書いたんだけど、その中にはガウシアンフィルタをかけても取り切れないようなシミや黒点がある画像がかなりあること(汚れがすごく目立つ画像は、ひとりで大我慢大会を開催し、「これは修行なんだ」と自分に言い聞かせて、1枚ずつペイントでそれなりにキレイにしたんだけど、それでもまだ汚れの目立つ画像がいくつも残っていた)。
ただ、文字情報とは関係のない黒い点なんかは、多少あった方が過学習を防止するのに役立つカモ(?)という観点から、小さなシミのある画像は敢えてそのままにしたものもそれなりにある。このへんは画像を見た感じでテキトーに判断(理論的なコトは勉強していないので、まったくわかりません)。
それと最初に書いた画像成形のスクリプトが不完全で文字の一部が欠けてしまった画像も若干含まれていることなど、今、ちょっと冷静になって振り返ってみると、自分では慎重に処理を進めてきたつもりでも、やはり無我夢中でやってると、その時々は気づかなかった「さらに良くすることができた・より良くすべきだった」見落としがポロポロあり、ここで、ようやく僕は、見落とし箇所の改善を思い立ったのだ。
例えば・・・シミや汚れ取りは(ある文字の一部を部分的に拡大)
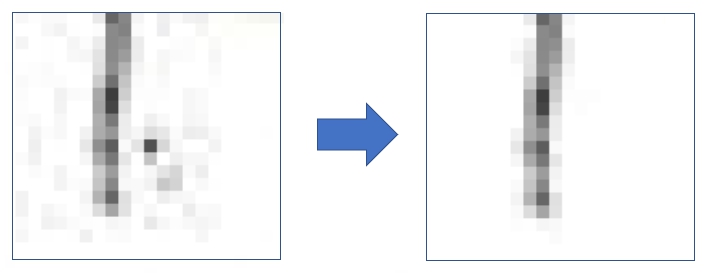
※ 実際には、この程度のシミと汚れは過学習防止用に敢えて残した画像も多数あり。
機械学習の事前準備処理の中で、学習用データとして使用する画像に、ガウスぼかしをかけたり、二値化したりして、上の左の画像に見られるようなごく薄い汚れは自動的に消えるから、すべての画像について徹底的にクリーニングする必要はないと思うのだけれど、ただ、明らかに濃度の高いシミ等は、なるべく消しておいた方が真っ白な気持ちで学びを開始するキカイに、少しはやさしいかな・・・みたいな気もするし *^_^*
反面、学習させたいデータ(例えば「ア」)とは直接関係のない黒いシミがある画像が多少は混じっていたほうが、過学習が起こりにくいのかなー? みたいな気もするし・・・
パラメータが利用できる場合は、ドロップアウトを何%にするかで、そういうことも含めて調整できるのかなー? みたいな気もするし・・・
ちゃんと勉強しなさい!という
神さまのドデカイ声が、力いっぱい
聴こえるような気もするケド・・・
『いったい、何が幸いするのか』まったくわからん。機械学習はほんとに難しい・・・などと、イロイロ考え(自分を誤魔化し)ながら、極端に大きなシミがある画像はとりあえずクリーニングし、また、これは不要と思われる文字(例:崩しすぎた文字、極端に小さな文字、ぼやけ・かすみの激しい文字等)を「テキトー」に削除した結果、ア~オ各文字のデータ数にばらつきが生じてしまった・・・。
たしか、MNISTだって各数字の総数はそろってなかったような気がするけど、今、僕が用意できたデータはMNISTの約1/100しかないから、質はともかく量的には明らかに不足しているはず・・・
今、手元にあるデータの数は・・・
ア:641
イ:653
ウ:652
エ:459
オ:575
「エ」がちょっと少ないのが気になると言えば、気になるけど、これしか集められなかったんだから仕方ない。せっかく集めたデータを利用しないのは嫌だし・・・。とりあえず、各文字の個数を水増しスクリプトで700に統一しようか・・・
データの水増しに使用するPythonスクリプトは、次のWebサイト様の情報を参照して作成じゃなくてほぼ写経(Pythonスクリプトの全容は、引用させていただいたWebサイト様の情報をご参照ください)。
https://keras.io/ja/preprocessing/image/#imagedatagenerator
https://www.yakupro.info/entry/digit-dataset
# ライブラリのインポートとパラメータの設定部分のみ
# Error
# from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array
# OK!
from keras_preprocessing.image import ImageDataGenerator, load_img, img_to_array
if __name__ == '__main__':
generator = ImageDataGenerator(
rotation_range=3, # ランダムに回転する回転範囲
width_shift_range=0.1, # 水平方向にランダムでシフト(横幅に対する割合)
height_shift_range=0.1, # 垂直方向にランダムでシフト(縦幅に対する割合)
#zoom_range=0.1, # 文字のハミ出しを防止するため設定せず
shear_range=0.5, # 斜め方向に引っ張る
fill_mode='nearest', # デフォルト設定(入力画像の境界周りを埋める)
)
sample_num = 700 # 各ラベルの画像がこの数になるよう拡張するこれでア~オの各文字約700個ずつのデータセットができた!
Lobeを起動し、ImportからDatasetを選び、0(アが入っている)~4(オが入っている)のフォルダの親フォルダを指定する。
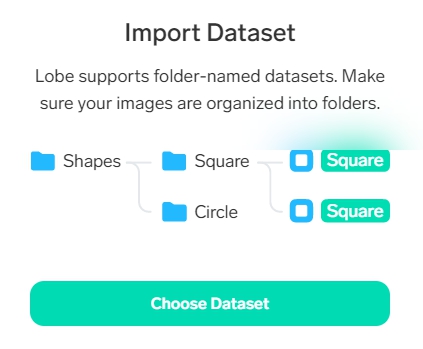
で、画像を Import すれば、あとは何にもしなくても、勝手に学習が始まるようだ。わずか(?)3500個のデータであるが、それなりに処理時間は必要(読ませた画像のサイズは幅64×高さ63で統一)。他のことをしながら処理が終わるのを待ったので、実際に何分かかったのか、定かではない(20~30分くらいか)。気がついたら終わっていた感じ。
表示が Training ⇨ Train になったら、終了 らしい。
学習結果は、次の通り。
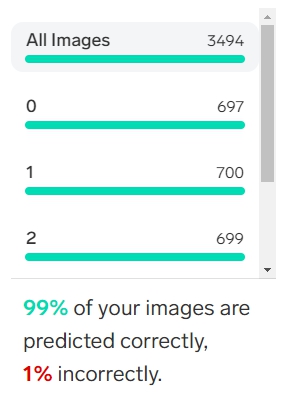
自動で分類できなかった文字は、ラベル付けして再学習も可能なようだが、今回はLobeが自動認識できなかった文字はそのままにして先へ進むことにした。
・・・と言うか、自動認識できなかった文字をクリックしてなんかテキトーにいじったら、その文字だけでなく、他の文字の処理も再び始まり(Train ⇨ Training に変化)、99%だった進行状況を表す数値がいきなりガクンと低下して、84%とかになってしまった。
自動認識できなかった文字は1%と言っても、数にすれば約30個あるから、その全てをこんなふうに再学習させたら、間違いなく日が暮れてしまう・・・。中には「コレが ア なら、7も1」、「雰囲気が『ア』ですー」みたいな文字も混じっているから、先へ急ぎたい僕は(本格的な再学習は次の機会に行うことにして)学習モデルの書き出し処理を優先することにしたのだ。
3.tflite形式で書きだす
Training が完了したら、次のように操作して学習モデルを tflite 形式で書き出し。
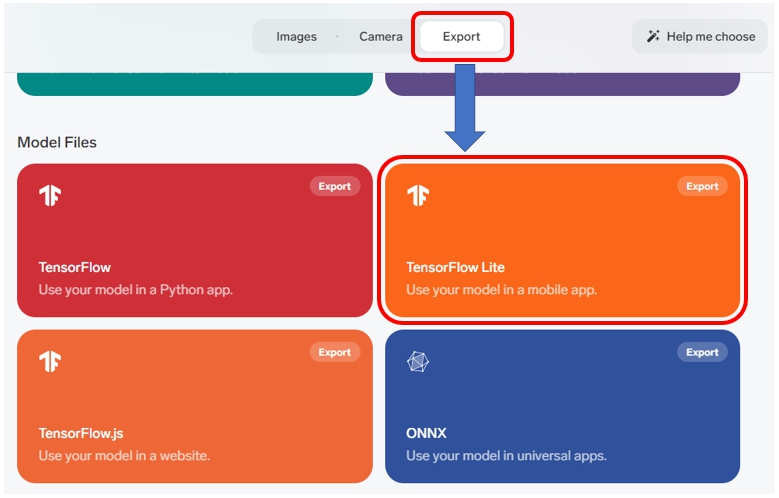
なんか、ものすごくかんたんに、tflite 形式で学習モデルができちゃったけど。
これでイイのかなー???
それから、ちょっと気になったので、tflite_example.py の内容をエディタでチラ見。
# tflite_example.pyの一部を引用
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Predict a label for an image.")
parser.add_argument("image", help="Path to your image file.")
args = parser.parse_args()
dir_path = os.getcwd()
if os.path.isfile(args.image):
image = Image.open(args.image)
model = TFLiteModel(dir_path=dir_path)
model.load()
outputs = model.predict(image)
print(f"Predicted: {outputs}")
else:
print(f"Couldn't find image file {args.image}")outputs = model.predict(image) ・・・ってコトは、学習モデルにイメージ(=画像)を predict(=予測)させ、outputs に代入(=出力)してるから、
うわー すごいおまけがついてる!
コレもあとから試してみよう!
※ 自分の中では、tflite形式で出力された学習モデルをDelphiから直接呼び出して文字認識を実行する方が、この時はあくまでも優先でした。
4.書き出したtfliteファイルをDelphiで・・・(泣)
早速、出来上がった(書き出された) saved_model.tflite ファイルを、DelphiのDebugフォルダにコピー。
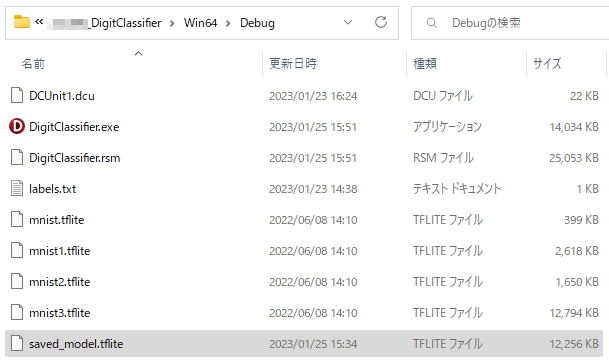
んで、コードを書き替えて・・・
//コードを書き換えた部分
procedure TForm1.Recognize;
var
・・・
//fOutput: array [0 .. 10 - 1] of Float32;
fOutput: array [0 .. 5 - 1] of Float32;
・・・
begin
・・・
try
{var fModelFile := 'mnist3.tflite';
case rdModel.ItemIndex of
0: fModelFile := 'mnist.tflite';
1: fModelFile := 'mnist1.tflite';
2: fModelFile := 'mnist2.tflite';
3: fModelFile := 'mnist3.tflite';
end;}
var fModelFile := 'saved_model.tflite';
case rdModel.ItemIndex of
0: fModelFile := 'saved_model.tflite';
1: fModelFile := 'saved_model.tflite';
2: fModelFile := 'saved_model.tflite';
3: fModelFile := 'saved_model.tflite';
end;この他には、関係ありそうな箇所は見当たらないから、きっとこれで準備OK! *^_^*
実行して、「ア」の上の「つ」部分を描いたところでマウスの左ボタンを離す・・・と、
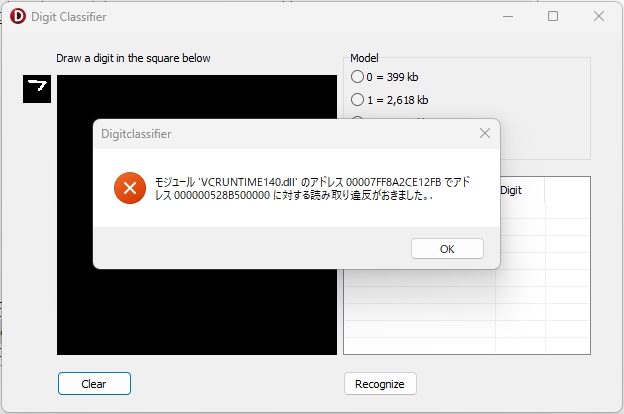
うわーん!( T_T )
君の見ている風景は・・・
どこまでも すべてが 涙色
君を悲しませるもの
その理由は もう 聞かないよ・・・
それでも僕は・・・
Delphi きみが大好きだ!
※ ファイルどうしの依存関係とか、よくわからんけど、もしかしたらそれがあるカモと考え、saved_model.tflite と同じフォルダに書き出されてた labels.txt や signature.json もDebugフォルダ内へ全部コピーして実行しても同じ結果でした。
イロイロ調べてみると、tflite 形式のファイルにもイロイロあるようで・・・
同じ .tflite のファイルでも違いがいろいろ:メタデータまわりについてTeachable Machine、Lobe、TensorFlow Hub等で出力した画像分類用のものを例に
https://qiita.com/youtoy/items/e58c02c1e32c56358d03
たぶん、saved_model.tflite と同じフォルダに書き出されてた labels.txt や signature.json の内容が tflite ファイル内に必要なんじゃないかなー。よくわかんないけど。
tfliteファイルを編集する知識なんて、僕にあるわけないし・・・
(ちょっと調べてみたら、PythonでTF Lite SupportのAPIを利用して、ラベル等の情報をtfliteファイル内に追加することができるようなんだけど、回り道が長すぎる気が・・・)
いずれにしても、どこかしら邪な、このチャレンジは失敗。
ちなみに labels.txt の内容は・・・
0
1
2
3
4
ちなみに signature.json の内容は
{
"doc_id": "9276cb74-46aa-435d-9edd-c0dcfa978a77",
"doc_name": "aiueo",
"doc_version": "fb48bd091c2950039e3841e1204230f2",
"format": "tf_lite",
"version": 45,
"inputs": {
"Image": {
"dtype": "float32",
"shape": [null, 224, 224, 3],
"name": "Image"
}
} みたいな感じで、よくわかりません(以下、略)5.Pythonで再チャレンジ
Delphiで tflite ファイルを直接読み込んでの文字認識に失敗して、すぐに思い出したのは先に見た『 tflite_example.py 』
PythonのスクリプトをDelphiのObject Pascal に埋め込んで実行することなら僕にもできるから、tflite_example.py で学習モデルがまだ見たことのないカタカナ文字画像の認識に成功すれば、最終的な目標の実現は可能だ。
すごいまわり道になりそうだけど、Delphiから直接読み込めるように tflite ファイルを編集する方法だってまだ残されている。ただ、僕はものごとを理解するのが遅く、学習には普通のヒトの何倍もの時間が必要だから、これはいよいよとなった時の最終手段だ。
SDカードに入れたWinPythonとAtomエディタで、僕は持ち運べるPython実行環境を作っている。Atomが開発中止になってしまったのはちょっとイタいけど、取り敢えずPythonスクリプトを書いて、実行するのに今のところ何ひとつ不自由はない。そのSDカードへLobeが書き出したファイルをフォルダごとコピーする。
Atomを起動。今、コピーしたexampleフォルダを開く。オリジナルの tflite_example.py をコピーして tflite_example2.py を作成。Atomに入れたパッケージ「script」から実行できるようにスクリプトを少し変更。exampleフォルダ内に次の画像を用意して・・・

スクリプトをクリックしてアクティブにしておいて、Shift + Ctrl + B で実行・・・
# 実行結果
Predicted: {'predictions': [
{'label': '0', 'confidence': 0.9855427742004395},
{'label': '3', 'confidence': 0.008924075402319431},
{'label': '1', 'confidence': 0.005291116423904896},
{'label': '4', 'confidence': 0.00012611295096576214},
{'label': '2', 'confidence': 0.0001159566527348943}]}
[Finished in 14.759s]学習モデルが予測したラベルは「0」つまり「ア」、信頼性は99%!
やった。成功だ。待ちに待った瞬間が、ついに訪れた・・・ ありがとう Lobe!
次々に画像を変えて実験。

# 実行結果
Predicted: {'predictions': [
{'label': '1', 'confidence': 0.8973742723464966},
{'label': '4', 'confidence': 0.10129619389772415},
{'label': '2', 'confidence': 0.0012468534987419844},
{'label': '3', 'confidence': 4.6186032705008984e-05},
{'label': '0', 'confidence': 3.642921365099028e-05}]}
[Finished in 3.313s]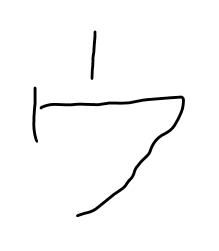
# 実行結果
Predicted: {'predictions': [
{'label': '2', 'confidence': 0.9924760460853577},
{'label': '1', 'confidence': 0.0038044601678848267},
{'label': '0', 'confidence': 0.0017367065884172916},
{'label': '3', 'confidence': 0.0010746866464614868},
{'label': '4', 'confidence': 0.0009080663439817727}]}
[Finished in 13.591s]
# 実行結果
Predicted: {'predictions': [
{'label': '3', 'confidence': 0.9999231100082397},
{'label': '1', 'confidence': 7.657476089661941e-05},
{'label': '4', 'confidence': 2.250336166298439e-07},
{'label': '0', 'confidence': 7.755971154210783e-08},
{'label': '2', 'confidence': 6.385280215681632e-08}]}
[Finished in 15.323s]
# 実行結果
Predicted: {'predictions': [
{'label': '4', 'confidence': 1.0},
{'label': '3', 'confidence': 1.7214372288743007e-11},
{'label': '1', 'confidence': 4.185582436200264e-12},
{'label': '0', 'confidence': 8.478809288784556e-14},
{'label': '2', 'confidence': 4.801435060631208e-14}]}
[Finished in 13.506s]すべて、正解 ・・・
なんだか、こころがカラッポになった。
そう、夢が叶う瞬間は、いつも・・・
6.正解率95%!
チャレンジの総仕上げとして、前回の実験では正解率91%だった手書きカタカナ「アイウエオ」画像37セットをLoopで判定し、認識結果を「アイウエオ」で出力できるよう、スクリプトを準備。
結果を信じて、実行。
# 実行結果
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
イ:×
イ:〇
エ:×
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
イ:×
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
イ:×
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
イ:×
エ:〇
オ:〇
ア:〇
イ:〇
エ:×
エ:〇
オ:〇
エ:×
イ:〇
ア:×
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
ア:〇
イ:〇
エ:×
エ:〇
オ:〇
ア:〇
イ:〇
ウ:〇
エ:〇
オ:〇
[Finished in 18.27s]正解率をExcelで計算。
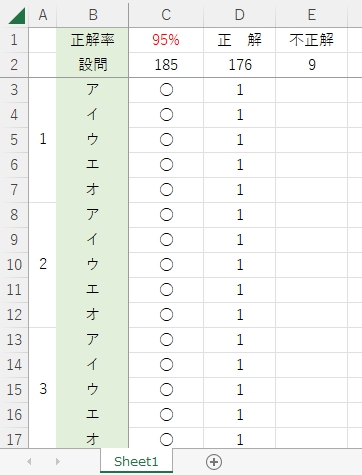
手書きアイウエオ画像185枚のうち、176枚を正しく認識できた。
これなら、自動採点に使える。
とうとう、やった。
夢の実現へ、大きく一歩を踏み出せた!
7.まとめ
無料で利用できるOCR技術を利用した手書き文字認識は、自分が試した範囲では、現状まだ実用には程遠い感触であった。
そこで、次に、手書き文字の座標を輪郭検出で取得し、文字を矩形選択して、解答欄のスキャン画像中から切り抜いて画像データ化、Web上に大量に情報が溢れているPythonライブラリ(TensorFlow+keras)を使用した機械学習で処理して学習モデルを作成(読み取り対象文字はアイウエオの5文字に限定)、この学習モデルを使っての文字認識にチャレンジしたが、学習データ数及びパラメータ設定を様々に工夫しても実際の検証データに対する正解率は91%より上昇することはなく、最終的な目標としていた自動採点に繋げることはできなかった。
そこで、今回は情報の収集範囲を広げて再チャレンジ。Lobeという分類器の存在を知る。このLobeに約3500枚(総文字数)の手書きカタカナ画像を読ませて tflite 形式の学習モデルを作成。これに前回の実験で使用したのと同じ手書きカタカナ文字(アイウエオの5文字 × 37セット=185枚)を見せたところ、95%の文字を正しく認識することができた。
この結果より、今後、より多くの良質な機械学習用手書き文字画像を集め、Lobeを利用して全自動で学習モデルを生成、さらにLobeが自動分類できなかった画像の質をチェックし、もし必要と判断される場合はラベル付けして追加学習を行い、より良くトレーニングされた学習モデルを準備できれば、最終的に人が必ずチェックするという条件の元で、機械と協働しての答案の自動採点は十分可能であると、僕は感じた。
なぜ、それを実現したいのか?
僕の中で、その理由はひとつしか、ない。
地位も、名誉も、富も、その前で、輝きを失う言葉に、僕は巡り合えたからだ。
The purpose of life is to contribute in some way to making things better.
人生の目的は、ものごとを良くすることに対して何らかの貢献をすることだ。
Robert F. Kennedy
DelphiやPythonと力を合わせれば、夢見たことを実現できる。そして、僕がひとりで夢見たことが、本当に、本当になったとして、それが僕自身だけでなく、偶然でもかまわないから・・・、知らない人でもいい、僕でない、他の誰かのために、もし、役立ったなら・・・、その時、こんな僕の拙く幼い学びにも、そこに、初めて「意味」や「価値」が生まれるんだ、と・・・。僕は本気で、そう信じている。
採点プログラムへのチャレンジは、再生紙に印刷したマークシートを、複合機のスキャナーでスキャンして電子データ化、このスキャン画像から、ほぼ100%正しくマークを読み取れるマークシートリーダーを作ることから始まった(完成したプログラムは任意の選択肢数を設定可能な一般用の他、選択肢の最大数を記号-、±、数字0~9、文字A~Dの計16 として「読み取り結果を抱き合わせての採点も可能」な数学採点用途にも対応)。開発当初は読み取りパラメータの最適な設定がわからず、読み取り解像度も高くする必要があったが、最終的にはパラメータ設定を工夫し、職場内の複数個所に設置されている複合機のスキャナーのデフォルト設定である200dpiの解像度で読み取ったJpeg画像でエラーなく稼働するものを実用化できた。これを職場のみんなに提供できた時、僕は本当に、心からうれしい気持ちになれた。人生の師と仰ぐ、ロバート・フランシス・ケネディの言葉をほんの少しだけ、僕にも実践できたかもしれない・・・と、そう本気で思えたからだ。
次に、マークシートとも併用可能な、手書き答案の採点ソフト作りにチャレンジした。最初は横書きの答案から始め、最終的には国語の縦書き答案も採点できるものに仕上げた。採点記号も 〇 や × だけでなく、負の数をフラグに使うことで、部分点ありの△も利用可能とし、コメント挿入機能や、現在採点している解答を書いた児童生徒の氏名も解答欄画像の左(or 右)に表示できるように工夫した(横書き答案のみ)。もちろん、合計点は自動計算。返却用の答案画像の印刷機能も必要十分なものを実装できた。採点作業が最も大変な、国語科7クラス分の答案を、午後の勤務時間内で全部採点出来たと聞いた時は、胸がたまらなく熱くなった・・・。
その次のチャレンジは、解答用紙の解答欄の自動認識機能の搭載だった。手書き答案採点プログラムを使うユーザーを見ていて、いちばん強く感じたことは、PCに解答欄の位置座標を教えるため、解答欄の数だけ矩形選択を繰り返さなくてはならない採点準備作業を何とかして低減、せめて半自動化できないか・・・ということだった。ここではOpenCVの優秀な輪郭検出器に巡り合い、点線を活用するなど解答欄の作成方法を工夫することで、全自動とまではいかないが、取り敢えず解答用紙中の全矩形の位置座標を自動取得し、必要な解答欄矩形の座標のみ、ユーザーが取捨選択できるプログラムを作成・提供できた。
そして、今、僕は、手書き・カタカナ1文字(アイウエオ限定)の自動採点にチャレンジしている・・・。
Ask and it will be given to you.
この言葉を信じ、失敗の山を築きながら、
次はきっと・・・
誓って自分に言い続けて。
生きるちからを失くしたときが、このチャレンジの終わり。
でも、僕は、僕がこの世から消えたあとも、
動くプログラムを作るんだ・・・
正直、今回、最終的に自分でやったことはアイウエオの画像データの準備だけ・・・みたいな感じになっちゃったけど、結局、Lobeとの出会いがすべてだったけれど、もし、途中で夢をあきらめていたら、絶対にLobeには出会えなかった・・・。
さぁ 次はアイウエオ限定の自動採点機能の実装だ。
Delphiが笑顔で、僕を待ってる・・・
8.お願いとお断り
このサイトの内容を利用される場合は、自己責任でお願いします。記載した内容を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。また、本記事内で紹介させていただいた実験結果は、あくまでも私自身が用意した文字データに対してのものであり、別データで実験した場合、同様の結果が得られることを保証するものではありません。