手書きカタカナ文字をPCに認識させる(その①)
【お断りと注意】
これは「失敗の記録」です。最後までお読みいただいても、ここに述べた方法では手書きカタカナ文字を100%正確にPCで識別することはできません。できないのですが・・・「この方法ではダメなんだ」という、失敗の例として公開します。僕自身は、今より良くなりたいので、継続して手書きカタカナ文字の認識プログラム作りに挑戦します。その結果は、まとまり次第、手書きカタカナ文字をPCに認識させる(その②)として報告します。
【研究と構想の概要】

カタカナ一文字の自動採点を最終的な目標に、まず、解答欄に書かれた手書きのカタカナ文字の位置座標を取得し、これをもとにカタカナ文字を矩形選択・切り取って、画像ファイルとして保存する(前回の記事)。
次に、手書きカタカナ5文字(ア・イ・ウ・エ・オに限定)を学習済みの文字認識プログラムで、この画像ファイル中の文字が何という文字であるのかを判別(今回の記事)し、採点。
カタカナ文字の矩形選択と画像ファイル化、判別まではObject PascalにPythonスクリプトを埋め込んでPython側で処理し、ユーザーから見える部分はDelphiでGUI等を作成する。もし、夢見たような記号部分の自動採点プログラムが作れたら、先に作成済みのマークシートリーダー&手書き答案採点ソフトの「おまけ」としてユーザーにプレゼント・・・できたらいいなぁ!
このような手順を考えた理由は、前回の記事に書いたように、無料で利用可能な、AIを利用しないOCRでは、手書き文字の認識がまだ不安定で、現時点では採点用途には利用できないと実験の結果から判断したため(2022年末現在)。
【今回の記事の内容】
1.手書きのカタカナ文字データベースを探す
2.カタカナ文字の機械学習
【学習モデル作成上の工夫 その1】
【学習モデル作成上の工夫 その2】
【学習モデル作成上の工夫 その3】
3.手書きのカタカナ文字を判別
4.まとめ
5.お願いとお断り
1.手書きのカタカナ文字データベースを探す
4年前、いろいろあって機械学習を勉強する必要が生じ、興味半分・仕事半分で、あの超有名なMNISTデータベースを使って数字を機械学習、ユーザーがマウスで画面に描いた数字が0~9の何なのかをボタンクリックで判断、アニメ音声で出力するプログラムを書いた。
今年は同様の内容で、PCに話しかけるとその言葉(日本語音声)に応じて、それを英語に翻訳して英語音声で出力したり、動画を再生したり、Web検索した結果を表示(例:天気予報など)して日本語で音声出力したりする・・・みたいなプログラムをまた書いた(?)んだ・・・けど。
ほぼ全部、写経の組合せ。
情報は溢れているし、やりたいこと、すぐできるし、表向きPython最高! なんだけど。
他言語でやったら、間違いなく、すごい! こと・・・やってるのに(なぜか、自分的には、全然、面白くなかった・・・)。
そういう意味では、OCRを使わない日本語の「文字」認識プログラム作りは難しい。
MNISTデータベース関連の情報に比べたら、検索結果は極端に少なくなる。
検索結果が少ないと、(困ったー!)と思う反面、(・・・開拓されてない・・・)そう感じて、未知の世界の扉の前に立っているような気もする・・・。
情報そのものが少ない中で、今回利用させていただいた日本語文字情報DBは、産業技術総合研究所が公開している「ETL文字データベース(このDBは、手書きまたは印刷の英数字、記号、ひらがな、カタカナ、教育漢字、JIS 第1水準漢字など、約 120万の文字画像データを収集しているとのこと)」。
データベースを利用したい場合は、次のリンク先の画面上部にある「DOWNLOAD」をクリックすると表示される「Download Request」画面に必要事項を入力して、送信ボタンをクリックすると、連絡先として入力したメールアドレスに電子メールが送付されるので、以後の手続きはそのメールを参照して行う。
http://etlcdb.db.aist.go.jp/?lang-ja
【重要】
このETL文字データベースは、研究目的に限り無料で使用可なので、商用利用が必要な場合は別途問い合わせが必要とのこと。ですので、ダウンロード&ご使用にあたっては、くれぐれも、使用規約をご確認いただき、無償での利用の可否について、ご判断ください。
ETL文字データベースのダウンロードと、その利用方法については、次のWebサイト様で紹介されていた情報を参考にさせていただきました。
https://financewalker.jp/programming20431/
2.カタカナ文字の機械学習
学習済みのモデル作成までの作業の流れは、次の通り。
(1)ETL文字データベース内のファイルからpng形式の画像を抽出。
(2)画像をリサイズしてkatakana.pickleファイルに保存。
(3)このpickleファイルからカタカナ文字の学習を実行して、学習済みモデル(モデル構造と学習済みの重み)の保存。
この一連の作業は、次のWebサイト様に掲載のあったPythonスクリプトを利用させていただきました。
https://github.com/devinoue/Katakana_OCR
上記リンク先にあるPythonスクリプトを次の順番で実行(スクリプト内のファイル等へのPathは、実行環境に合わせて適宜変更)。
(1)preprocessing_image_enhance.pyを実行
(2)preprocessing_image_resize.pyを実行
(3)katakana_cnn.pyを実行
なお、(3)については、モデルの評価のスクリプトの後に、次の一行を加え、学習済みのモデルが保存されるようにしてから実行した方がイイかも。
# 学習済みモデルの保存
model.save('任意の名称_model.h5')今回、実験に使用した学習済みモデルは、独自に手書き文字の追加学習用データを作成、このデータに対して『水増し処理』(=Data Augmentation)を実行したオリジナルh5ファイルを使用。
batch_size=128、epochs=12とした場合の学習結果は、次の通り。
参考:学習は、データセットを幾つかのサブセットに分けて行われる(学習データとテストデータに分けるのとは別)。このサブセットに含まれるデータの数がバッチサイズ。(数千件程度のデータに対しては128とか、256あたりがよく使われる値?)
参考:データを何グループに分けたかが「イテレーション」。これは上のバッチサイズが決まれば自動的に決まる値。
参考:モデルが何回全データを見たか(=何回、学習したか)がエポック数。
まずはAccuracy(正解率)について、
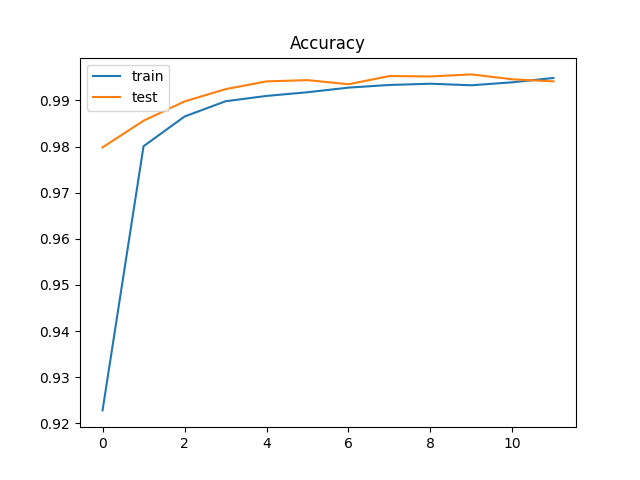
最後の部分で過学習が発生しているようだ。なので、Dropoutを0.25として再実行。
続いて、Loss(損失関数の出力する値)は、次の通り。
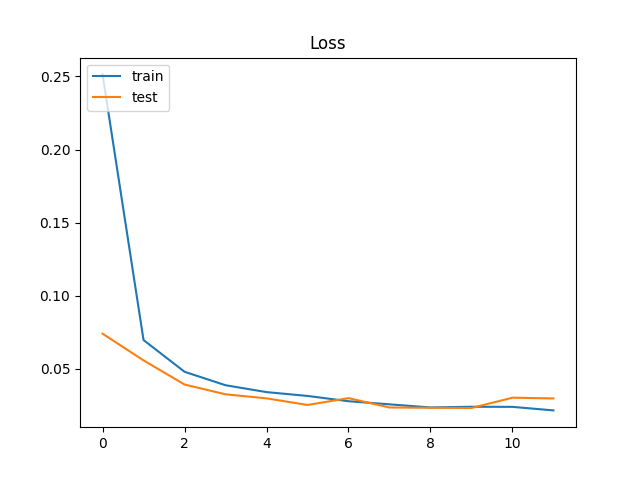
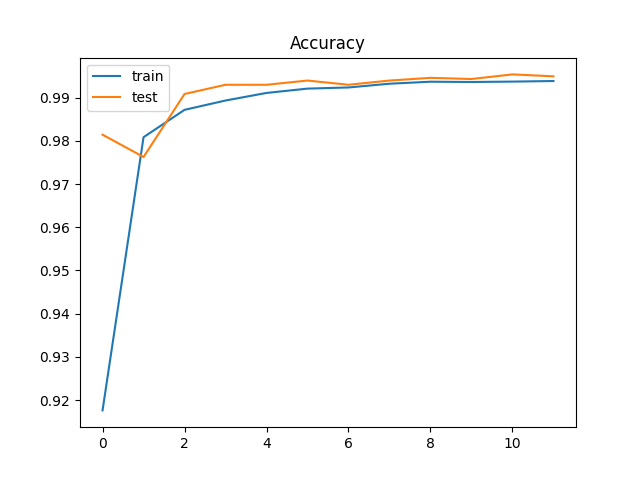
やはり、学習の最終段階で過学習が発生している。で、Dropoutを0.25にすると・・・
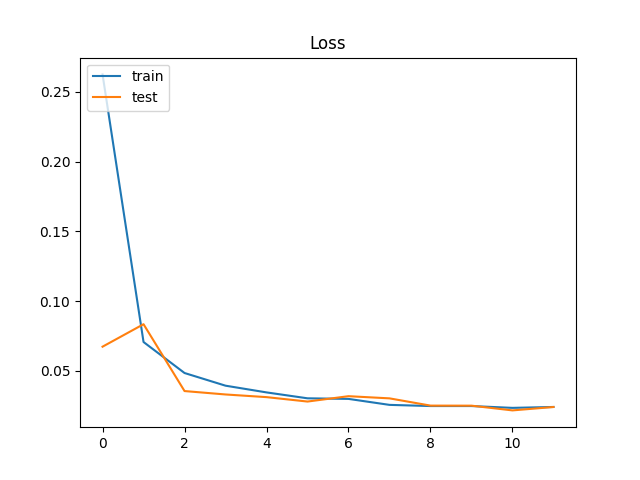
Loss(損失関数の出力する値)は、『「正解値」と、学習モデルが出力した「予測値」とのズレの大きさ(=Loss:損失)』を意味するとのこと。そこから考えると、イイ感じに学習できているのではないだろうか?
参考:Dropoutは、「ある特定のレイヤーの出力を学習時にランダムにゼロにしてしまう」ことで、これを行うことで「学習モデルがデータの欠損に対して強く」なり、「学習データの局所特徴の過剰評価が抑止」され、「学習モデルのロバスト性が向上」する。
【学習モデル作成上の工夫 その1】
実験の当初は、ETL文字データベースのカタカナ文字すべてについて機械学習を行ったが、これにより得られた学習モデルで、手書きカタカナ文字の読み取り実験を行うと、実際のテストでは解答用記号にまず使用されない「例:ワ・ヲ・ン」などで(誤)認識結果が出力されることに気付いた。そこで思い当たったのが「選択肢1/50音(学習は46文字)とするより、1/5で判定した方が正解率が高まるのでは?」ということ。
選択肢ア・イ・ウ・エ・オの5つで実験して上手く行ったら、選択肢カ・キ・ク・ケ・コや、選択肢サ・シ・ス・セ・ソに特化した学習モデルも作成。後からDelphiで作るGUIで設問の解答を設定する際に、正解の入力欄の下にComboBoxを利用して、例えば「正解:ア~オ」の設問については、判定に「ア行の学習モデル」を使用できるようにすればいいのではないか?
設定がひと手間増えるが、ここは採点の正確さを高める方が優先。選択肢数が5を超えるような設問は自動採点の対象外とするか、問題そのものを分割する等、自動採点用の問題となるよう、ユーザーに工夫してもらえばいい。
早速、「ア・イ・ウ・エ・オ」の5文字のみ、学習したモデルとなるよう、次のようにそれぞれのスクリプトを変更して、学習モデル作りを再実行。※ 上に掲載した正解率と損失関数の出力値のグラフは、この形式で作成した学習モデルで得られたもの。正解率が0.99以上になっているのは、正解の選択肢を1/46から1/5に変更したためと解釈(当初の選択肢1/46のモデルでの正解率は、パラメータの設定で変動するが最高で0.96程度)。
preprocessing_image_resize.py
# カタカナの画像が入っているディレクトリから画像を取得(オリジナル)
# kanadir = list(range177,220+1)
# kanadir.append(166)#ヲ
# kanadir.append(221)#ン
# カタカナの画像が入っているディレクトリから画像を取得(変更)
kanadir = list(range(177, 180+1)) # 177フォルダに「ア」が入っている
kanadir.append(181) # オkatakana_cnn.py
# out_size=46 #ア~ンまでの文字数(オリジナル)
out_size=5 #ア~オまでの文字数(変更)【学習モデル作成上の工夫 その2】
ETL文字データベースのカタカナ文字を眺めていて気がついたことは、確かに手書き文字なんだけれど、非常に丁寧に書かれた感のある手書き文字で、MNISTの数字のような、実際のテストの際に書かれる、時間に追われてます感満載の、あの書きなぐったような「部分部分がつながってない文字」が案外少ないということだ(著作権その他の問題を考慮して、例に挙げた汚いカタカナ文字はWordのペン機能で自作)。
例えば、「ア」は「ノ」の部分が大きく離れているような「ア」が多い。

「イ」も同じ。

「ウ」はむしろ、上の「|」が下の「ワ」に付いていない方が圧倒的多数。

「エ」は上の「ー」に「|」が付かない場合が多い。

さらに、急いで書くためか、右肩上がりの斜めになった「エ」も多い。

「オ」も「ノ」が切れたり、

出るべき場所が、ほとんど出ていなかったり、

それは「オ」じゃなくて「才」だろ・・・みたいな

これらの実際の手書き文字に見られる傾向を追加学習できるよう、ア・イ・ウ・エ・オの各文字について104文字ずつ、追加学習用の手書きカタカナ文字データを作成。
なぜ各104文字なのかというと、もっと多くの追加学習用データを集めたいのはヤマヤマだったのですが、時間的な制約と、104文字ずつ集めたところで本人が「力尽き」ました。(この実験が上手く行ったら、あとからたっぷり時間をかけて、さらに大量のデータを集めて再度、学習モデルを作成する予定。この後、最終的には少ない文字で450~多い文字で650程度まで増加させた。)
上記の処理は、機械学習について学んだ範囲で、何とか学習データを効率よく増やせないかと考えて工夫・実験的に行ったもので、手法的に正しいのかという点も含め、その効果はまったく保証できないものであることにご注意ください。左右90°回転とか、左右・上下反転というような、現実に存在しない「水増し」データではないから、多少は意味や効果があるかなー? と考えた次第。
【学習モデル作成上の工夫 その3】
文字画像データを作成する際、いちばん困ったのが、例えば「ア」の「ノ」部分が離れている場合、文字を矩形選択して切り抜くプログラムが(機能的には正しく動作しているのだが)こちらの期待に反する挙動を示すこと。つまり、次の例のように


この問題に「どう対応するか?」
世の中の誰一人悩んでないだろう、こんな問題で悩めるなんてある意味とても幸せな気もしますが、解答は自分で探すしかありません。
探すと言うか、自分で何とかするしかないのですが、その方法がわかりません。
しかし、解答は思わぬところに落ちてました。
例えば、次の構成部品の全てが離れた「ウ」を切り抜く(=画像化)するとき、

マイ切り抜きスクリプトで矩形選択すると、こうなって・・・
上は、余白(=マージン)設定「5」で実行。まだ「ウ」全体が入らない・・・。
そこで最適なマージンを設定するために、Loop用変数の値がそのままマージンになるようなスクリプトを準備し、かつ、その一つ一つの切り抜き画像について、学習済みモデルがどう判定するかを実験してみようと思い立ち、早速、書いたのが次のスクリプト。
# ある文字について、その最適なマージンを調べる & 文字を判定
import sys
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import cv2
import numpy as np
from PIL import Image
from keras.models import load_model
from tensorflow.keras.preprocessing.image import load_img, img_to_array
# 余白を追加する関数
def add_margin(pil_img, top, right, bottom, left, color):
width, height = pil_img.size
new_width = width + right + left
new_height = height + top + bottom
result = Image.new(pil_img.mode, (new_width, new_height), color)
result.paste(pil_img, (left, top))
return result
for j in range(50):
file_path = r".\img\u01.jpg"
org_img = Image.open(file_path)
# 十分な余白を上下左右に追加しておく
pil_img = add_margin(org_img, 50, 50, 50, 50, (255, 255, 255))
img = np.array(pil_img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.adaptiveThreshold(blur, 255, 1, 1, 11, 2)
#contours = cv2.findContours(thresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
contours = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
num = len(contours)
mylist = np.zeros((num, 4))
i = 0
#red = (0, 0, 255)
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
if h < 20: # 高さが小さすぎる輪郭は見えなかったコトに
mylist[i][0] = 0
mylist[i][1] = 0
mylist[i][2] = 0
mylist[i][3] = 0
else:
mylist[i][0] = x
mylist[i][1] = y
mylist[i][2] = x + w
mylist[i][3] = y + h
#cv2.rectangle(img, (x, y), (x+w, y+h), red, 2)
i += 1
pw, ph = pil_img.size
if pw > ph:
mylist_sort = mylist[np.argsort(mylist[:, 0])]
else:
mylist_sort = mylist[np.argsort(mylist[:, 1])]
# マージン指定用に準備した変数には(とりあえず消さずに)0を代入
intTweak = 0
# 切り抜く範囲の座標を取得
for i in range(num):
if mylist_sort[i][0] != 0:
x1=int(mylist_sort[i][0]-intTweak-j)
y1=int(mylist_sort[i][1]-intTweak-j)
x2=int(mylist_sort[i][2]+intTweak+j)
y2=int(mylist_sort[i][3]+intTweak+j)
break
img_crop = pil_img.crop((x1,y1,x2,y2))
# 読み込んだ画像の幅、高さを変更(幅64, 高さ63)
(width, height) = (64, 63)
# 画像をリサイズする
img_resized = img_crop.resize((width, height))
img_resized.save(r".\img2\crop"+str(j)+".jpg")
model_file_name="katakana_model.h5"
model=load_model(model_file_name)
for j in range(50):
# ここに書いてLoopを回すと警告される
# model_file_name="katakana_model.h5"
# model=load_model(model_file_name)
img_path = (r".\img2\crop"+str(j)+".jpg")
img = img_to_array(load_img(img_path, color_mode = "grayscale", target_size=(25,25)))
img_nad = img_to_array(img)/255
img_nad = img_nad[None, ...]
label=["ア","イ","ウ","エ","オ","カ","キ","ク","ケ","コ","サ","シ","ス","セ","ソ","タ","チ","ツ","テ","ト","ナ","ニ","ヌ","ネ","ノ","ハ","ヒ","フ","ヘ","ホ","マ","ミ","ム","メ","モ","ヤ","ユ","ヨ","ラ","リ","ル","レ","ロ","ワ","ヲ","ン"]
pred = model.predict(img_nad, batch_size=1, verbose=0)
pred_label = label[np.argmax(pred[0])]
print(str(j)+": "+"name:",pred_label)※ 画像をリサイズしていいのか? という疑問を持たれる方もいらっしゃるかもしれませんが、PCに見せる画像(学習用・判定用ともに)は、例外なくすべてこのスクリプトで処理するので問題ないんじゃないかと・・・。
で、このスクリプトを実行すると・・・
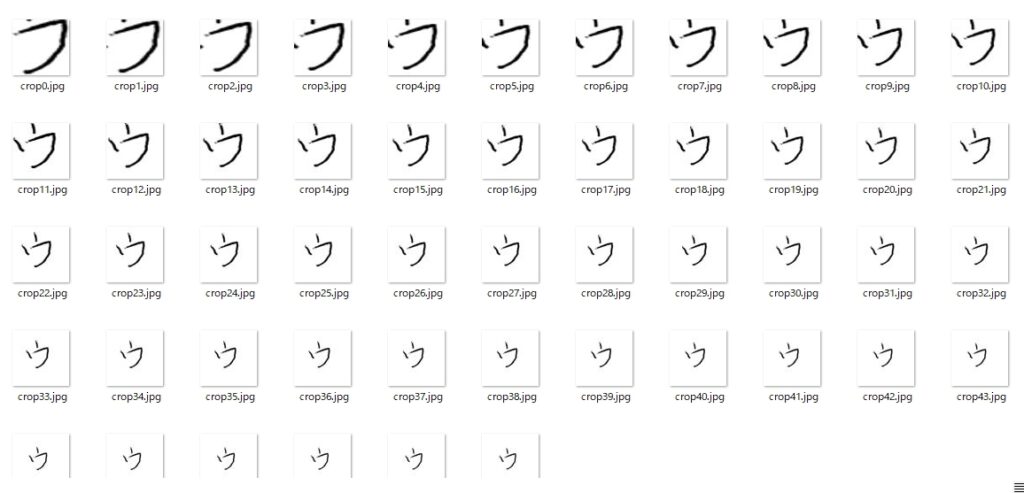
Loopがまわる度にマージンが大きくなり、ある程度Loopを廻せば文字全体をなんとか切り抜けることを発見。やったー! これでほぼ問題をクリア!
さらに、判定結果は・・・驚くべきことに、
0: name: ウ
1: name: ウ
2: name: ウ
3: name: ウ
4: name: ウ
5: name: ウ
6: name: ウ
7: name: ウ
8: name: ウ
9: name: ア
10: name: ウ
11: name: ウ
12: name: ウ
13: name: ウ
14: name: ウ
15: name: ウ
16: name: ウ
17: name: ウ
18: name: ウ
19: name: ウ
20: name: ウ
21: name: ウ
22: name: ウ
23: name: ウ
24: name: ウ
25: name: ウ
26: name: ウ
27: name: ウ
28: name: ウ
29: name: ウ
30: name: ウ
31: name: ウ
32: name: ウ
33: name: ウ
34: name: ウ
35: name: ウ
36: name: ウ
37: name: ウ
38: name: ウ
39: name: ウ
40: name: ウ
41: name: ウ
42: name: ウ
43: name: ウ
44: name: ウ
45: name: ウ
46: name: ウ
47: name: ウ
48: name: ウ
49: name: ウ
[Finished in 33.656s]10回廻ったところで、なぜか「ア」と判断しているが、それ以外は全部「ウ」と判定。
(最初見たときは『なんて優秀なんだ!』と激しく感動したが、あまりにも優秀すぎる結果に対し、実験を重ねるごとにナニかが違う、なんかオカシイと思い始め、最終的に気がついたことは、文字が小さくなると、この学習モデルは「エ」以外は何でも「ウ」にしたがるということ。わかんなかったら、とりあえず「ウ」だ!と、機械が思ってるわけではないんでしょうが・・・とにかく これより、ある程度Loopが廻り、画像中の文字が小さくなると、判定結果の信頼性も著しく低下すると考えていいことがわかりました)
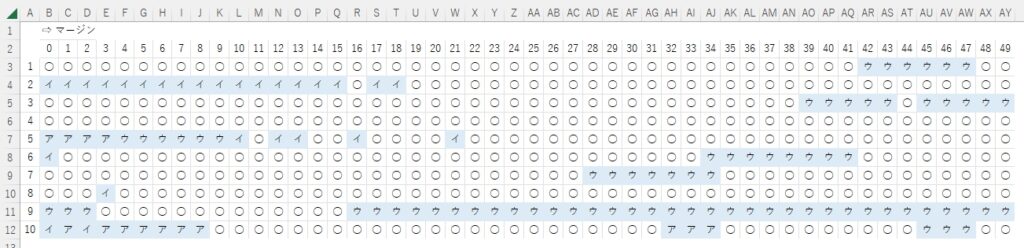
この他にも状態が良さげ(=上手に見える)手書き文字について、上の切り抜き実験を繰り返し行い、結果を表にして最適な余白設定を考える。とほーもない量の実験データがあれば、統計的に処理して最適な余白設定が行えるのだろうけど、計算に時間もかかるし、ア~オの各文字について各10文字ずつ、実験するのが自分的な限界。これだけでほぼ1日費やした。がんばったなー
次の表は、「オ」に関する実験結果。
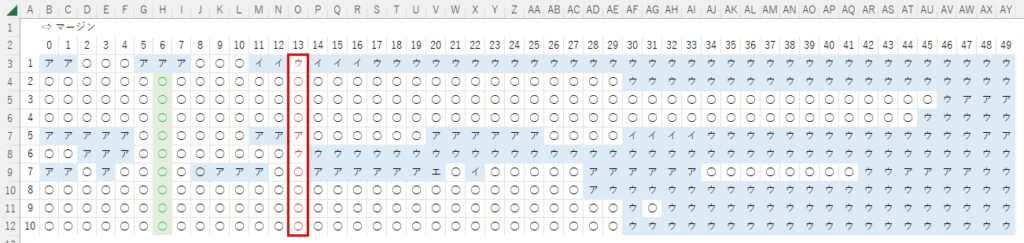
たった10個でこんなこと言っちゃいけない(=判定しちゃいけない)と自分でも間違いなく思うけど、だけど、オレにはこのデータしかないから、これを信頼するしか「ない」。
ぱっと見、25回以上Loopが廻ったところで、「ウ」が大好きなマイ学習モデルはちからいっぱい「ウ」に見えますとPRしてくる・・・から、26回目以降のデータは「全て無視」することにして、文字全体がだいたい見えてくる13回目あたりが余白設定に適切な値なのではないかと・・・。
この「オ」の例では5・6・7Loop目の成績が良いが、この程度のLoopだと、まだ文字全体が見えてない場合があることも考慮して、共通して設定する余白は「13」に決定。誤判定が多くなり始める「26」の半分の値にしておけば(いちばん、安心かな?)みたいな。
ちなみに「ア」は・・・
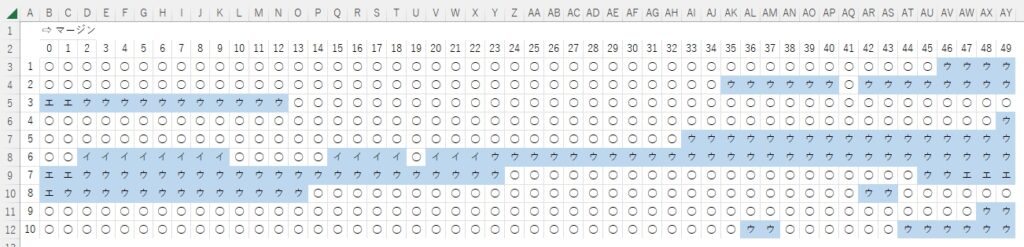
Loop回数が少ないのに読み取れないのは・・・

ちなみに「イ」は・・・
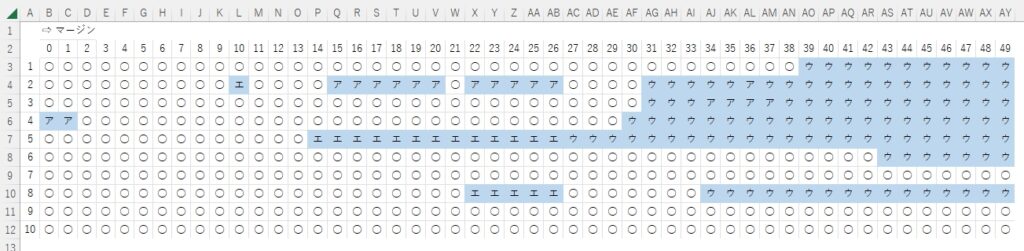
ちなみに「ウ」は・・・(ペール・オレンジ部分は文字全体が見えないので削除)
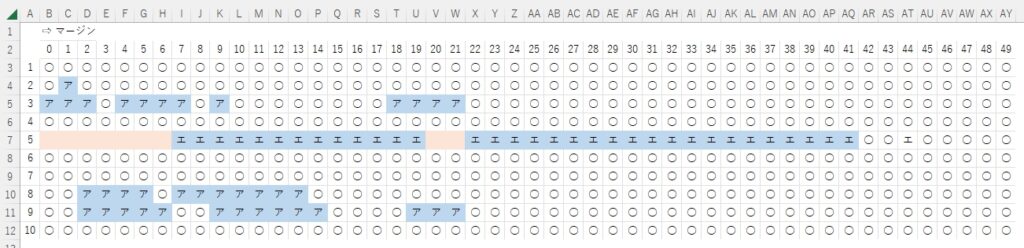

ちなみに「エ」は・・・
Loop回数が少ないのに読み取れない「エ」は・・・

そんなこんなで、極めていい加減ではありますが、追加学習データ用の切り抜き画像に共通して適用する余白設定は「13」に決定。
実は、最初は余白を適当に設定しておりまして、何となく「13」あたりに設定した時の判定結果が良いことに気付いていたのですが、きちんと視覚化して見て、あらためて納得。
3.手書きのカタカナ文字を判別
上で、もうすでにやってますが、最終的に完成した手書きカタカナ文字画像を認識&判別するスクリプトは次の通り。ここでは連続して5枚の画像を判定できるようLoop処理しているが、Loopを外せば1枚の画像処理用に使える。
いま、ふと思ったんだけど、PCの処理性能が高く、時間的にも問題がなければ、同じ画像に対して余白設定を少しずつ変更してLoopを廻し、結果の多数決で文字を判別するような用途にも使えるかもしれない(実験はしていません)。
いずれにしても、「正解でない手書き文字(=解答)」を「正解である」と誤判定して、つまり、正答が「ア」である設問で、解答欄に実際に書いてある文字は「ウ」であるのに、これを「ア」であると認識し、誤った採点を行う可能性が多分にあるので、最終的にはヒトの目視によるチェックが必須であることは、言うまでもありません(当然、この逆、つまり誤った解答を正答であると誤判定する場合もあり得ます)。
だったら・・・自動採点じゃない かな?
でも、ヒトだってかなり間違えて採点するから、プログラムの信頼性を十分実用になるレベルまで高めて、その上でPCと協働採点すれば、答案を二重にチェックしたことになるし、ここで挫けたら、この段階の次(複数文字=文字列=文章の自動採点)に進めない・・・。だから、プログラムが完成したら、ユーザーにはチェックの必要性について、ここで述べたように説明して理解してもらおう。
また、実際の答案画像の処理を行う場合には、「解答が書かれていない」=「空欄」であった場合への対応が必須です。検出された輪郭数が0(ゼロ)であったら処理しないというような条件分岐を追加してください。
# 画像の中の文字を検出して、最初の一文字の画像を保存し、その文字がカタカナの何であるかを判定するScript
# アイウエオの5文字セット用 -> Loop処理を外せば一文字を判定可能
# 判定用の手書きカタカナ文字画像は答案画像から切り出して用意しておく
# 画像はJpeg形式で用意(png形式なら拡張子の書き換えが必要)
# 文字のない(空白の)画像には未対応であることに注意
# 実行には予めア~オの手書き文字を機械学習した「学習済みモデル」が必要
# 判定結果は用意した学習済みモデルの性能次第
# (学習済みモデル名は "katakana_model.h5 "とした)
import sys
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2' # 警告を表示しない
import cv2
import numpy as np
from PIL import Image
from keras.models import load_model
from tensorflow.keras.preprocessing.image import load_img, img_to_array
# 余白を追加する関数
def add_margin(pil_img, top, right, bottom, left, color):
width, height = pil_img.size
new_width = width + right + left
new_height = height + top + bottom
result = Image.new(pil_img.mode, (new_width, new_height), color)
result.paste(pil_img, (left, top))
return result
for j in range(5):
if j == 0:
file_path = r".\img\a.jpg"
elif j == 1:
file_path = r".\img\i.jpg"
elif j == 2:
file_path = r".\img\u.jpg"
elif j == 3:
file_path = r".\img\e.jpg"
elif j == 4:
file_path = r".\img\o.jpg"
org_img = Image.open(file_path)
# 十分な余白を上下左右に追加しておく
pil_img = add_margin(org_img, 50, 50, 50, 50, (255, 255, 255))
img = np.array(pil_img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.adaptiveThreshold(blur, 255, 1, 1, 11, 2)
# # 白の輪郭、黒の輪郭、内側、外側関係なく、同じ階層で輪郭を抽出する
#contours = cv2.findContours(thresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
# 最も外側の輪郭のみを抽出する
contours = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
num = len(contours)
mylist = np.zeros((num, 4))
i = 0
#red = (0, 0, 255)
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
if h < 20: # 高さが小さすぎる輪郭は見えなかったコトに
mylist[i][0] = 0
mylist[i][1] = 0
mylist[i][2] = 0
mylist[i][3] = 0
else:
mylist[i][0] = x
mylist[i][1] = y
mylist[i][2] = x + w
mylist[i][3] = y + h
#cv2.rectangle(img, (x, y), (x+w, y+h), red, 2)
i += 1
pw, ph = pil_img.size
if pw > ph:
mylist_sort = mylist[np.argsort(mylist[:, 0])]
else:
mylist_sort = mylist[np.argsort(mylist[:, 1])]
# マージン調整
intTweak = 13
# 最初に見つかった文字が最も左にある文字
for i in range(num):
if mylist_sort[i][0] != 0:
x1=int(mylist_sort[i][0]-intTweak)
y1=int(mylist_sort[i][1]-intTweak)
x2=int(mylist_sort[i][2]+intTweak)
y2=int(mylist_sort[i][3]+intTweak)
#cv2.rectangle(img, (x1,y1), (x2, y2), green, 2)
break
img_crop = pil_img.crop((x1,y1,x2,y2))
# 読み込んだ画像の幅、高さを変更(幅64, 高さ63)
(width, height) = (64, 63)
# 画像をリサイズする
img_resized = img_crop.resize((width, height))
img_resized.save(r".\img\crop"+str(j)+".jpg")
# オブジェクトの明示的な解放
#del mylist
model_file_name="katakana_model.h5"
model=load_model(model_file_name)
for j in range(5):
# ここに書いてLoopを回すと警告される
# model_file_name="katakana_model.h5"
# model=load_model(model_file_name)
img_path = (r".\img\crop"+str(j)+".jpg")
img = img_to_array(load_img(img_path, color_mode = "grayscale", target_size=(25,25)))
img_nad = img_to_array(img)/255
img_nad = img_nad[None, ...]
# 発展的な未来を信じて、五十音を全部用意してあります・・・
label=["ア","イ","ウ","エ","オ","カ","キ","ク","ケ","コ","サ","シ","ス","セ","ソ","タ","チ","ツ","テ","ト","ナ","ニ","ヌ","ネ","ノ","ハ","ヒ","フ","ヘ","ホ","マ","ミ","ム","メ","モ","ヤ","ユ","ヨ","ラ","リ","ル","レ","ロ","ワ","ヲ","ン"]
pred = model.predict(img_nad, batch_size=1, verbose=0)
pred_label = label[np.argmax(pred[0])]
print('name:',pred_label)こうしてimgフォルダ内に用意した「a,i,u,e,o」の各Jpeg画像の手書き文字を正しく認識できるか・どうか、繰り返し実験したが、正解率は90%くらいの感じで、学習モデル作成の際にAccuracyとして表示された99%には程遠い。
そのうち、imgフォルダ内の手書き文字画像をいちいち入れ替えて実験するのが面倒になってきたので、01~37という名称のフォルダを作成し、この中にアイウエオの手書き文字画像を入れ、37回連続でさまざまな手書きアイウエオ画像を認識・判定するスクリプトを書いて、実際的な正解率を出してみた。次がその結果。
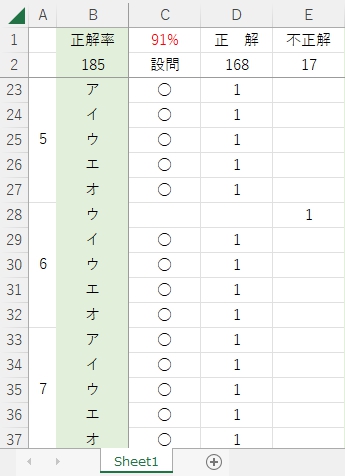
ヒトの場合、テストで91点採れれば、ほめられることはあっても、叱られることはまずないと思うが・・・。それは平均点がだいたい6割程度に設定されている前提があるからで、これが機械の場合、平均点の前提条件は言うまでもなく100点。なので、1割以上確実に間違える自動採点プログラムは・・・
誰も誉めてくれませんし、使いたくもありません!
これが小学校の夏休みの自由研究なら、校内発表で誇らしげに発表し、感動の伴わない拍手を(3秒くらい)してもらえたカモ・・・しれませんが。
ここまでに要した時間は、ほぼ1か月。実に様々なことを新しく学び、発見し、悩み、時に喜びもありましたが、最終的に、自分自身の感触として「この方法ではダメなんだ」とはっきり悟りました。手書き文字の自動採点という目標を実現できる、別の方法を探すことにします。
あきらめない限り、もしかしたら夢は・・・ 実現できるかもしれませんから。
4.まとめ
残念ながら、ここに記載した方法では、手書きカタカナ文字画像を100%正しく読み取ることはできなかった。学習モデル作成時にトレーニング用データとして使用する手書きカタカナ画像の量を変化(ETL文字データベースに収められた画像+自分で集めた文字画像ア~オ各文字650個をベースに、これを様々に水増しして使用)させたり、学習モデルを作成するスクリプトの各種パラメータ設定を様々に変更して実験したが、実際の手書きカタカナ文字に対するMy学習モデルの正解率は最高で91%であった。
※ 実験で使用した手書きカタカナ文字は全て幅64ドット、高さ63ドットの矩形内にほぼ収まるように、元画像から切り抜いてデータ化する際に拡大・縮小処理を行っている。
5.お願いとお断り
この記事で使用した手書き文字は、使用の承諾を得た家族及び自分自身で書いたものです。使用に許諾が必要と思われる第三者の書いた手書き文字は一切使用しておりません。また、本記事内で紹介させていただいた実験結果は、あくまでも私自身が用意した文字データに対してのものであり、別データで実験した場合、同様の結果が得られることを保証するものではありません。
このサイトの内容を利用される場合は、自己責任でお願いします。記載した内容を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。