手書きカタカナ文字をPCに認識させる(その④)
前回の記事で作成した手書きカタカナ文字「アイウエオ」の学習モデルを、My手書き答案採点プログラムで利用できるようにした。自動採点用のGUIを作成して、実際の手書き文字をどの程度正しく認識できるか検証。ついでに、ふと思い立って、「〇」記号と「×」記号の学習モデルも作成。こちらについても、正しく認識できるかどうか、実験してみた。結果は「アイウエオ」、「〇×」とも100%正しく認識することはできなかったが、よく考えれば、リアルな文字認識にチャレンジするのは今回が初めて。ここまでが長かったので、自分的には終了感満載だったけど、ここからが本当のチャレンジの始まりなんだ・・・と気づく。これまでにやってきたことは、言わば準備作業。現段階で、僕の「自動採点」は、採点作業の「補助」くらいには、使えるんじゃないか・・・と。
1.それは「イ」じゃないんですけど・・・問題への対応を考える
2.プログラムに自動採点のGUIを追加
3.自動採点を実行!(その1)
4.自動採点を実行!(その2)
5.〇×記号の学習モデルを作成
6.〇×記号の解答も自動採点
7.FormCreateでPythonEngineを初期化
8.まとめ
9.お願いとお断り
1.それは「イ」じゃないんですけど・・・問題への対応を考える
まずは、前回の記事で最後に紹介した「問題」への対応から。
前回は、学習モデルの性能を確認するため、PCの画面にマウスで描いたカタカナ文字をLobeで作成したMy学習モデルが「どの程度正しく認識できるか」を試すプログラムをDelphiで作成して検証(文字認識部分は内部に埋め込んだPythonスクリプトで実行)。
あまりにもGoooooooooooooooooooooooooooooooooood!な結果に、この結果にたどり着くまでの長かった道のりを思い出し、本人涙ぐむシーンもあったが・・・、スキャナーでスキャンした画像にみられるシミや汚れへの反応をみるため、試しに画面をワンクリックして「点」を入力し、それを認識させてみたところ・・・
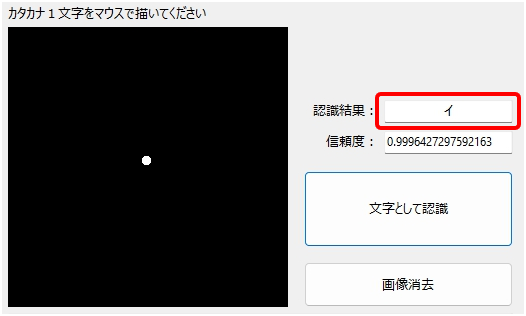
このあまりにも楽しい結果に、今度は涙ぐむほど大笑い。さすがMy学習モデル。夏休みの自由研究レベルをしっかりと維持しています・・・。
で、どう対策したか?
さすがにこのままでは実戦に投入できないので、文字画像に「大津の二値化」を適用した後、OpenCVのcountNonZero()関数を利用して、全ピクセルのうち、値が0(=黒)でないピクセルの合計を求め、画像中の白黒の面積を計算。イロイロ、テストした結果、上記の画像で白面積(=文字面積)が1.5%より大きい画像を「文字情報あり」と判断して、輪郭検出するようスクリプトを修正。これで、この問題は無事クリア☆
# 読み込んだイメージにOpenCVのcountNonZero関数を適用、白面積を計算。
wPixels = cv2.countNonZero(img)※ 上の画像では、文字が「白」なので白面積を計算している。
2.プログラムに自動採点のGUIを追加
My手書き答案採点プログラムに自動採点のGUIを付け加えるにあたり、プログラムの64ビット化(プログラムに同梱したembeddable PythonにインストールしたTensorFlowは64ビット版しか存在しないため)と、解答欄矩形の自動検出機能の実装で不要になったGUIの整理を行った。で、空いたスペースに自動採点のGUIを作成。
操作パネルのGUIを32ビットバージョンから、次のように変更。準備段階でしか使わなかった部品があらかた消えて、(自分的には)画面がかなり「すっきり」した気が。
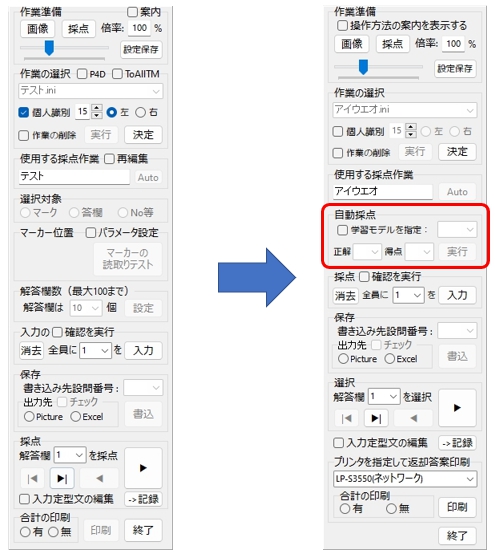
3.自動採点を実行!(その1)
(1)学習モデルを指定
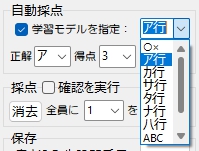
選択肢だけは、たくさん用意してあるけど、現在利用できるのは「○×」と「ア行」のみ。(「カ行」以降は、もしかしたら永遠に利用できないカモ・・・)
自前で機械学習の訓練用データを作成するのは、本当に、本当に、本当に、すーぱーたいへん! 答案をスキャンした画像から、文字画像の切り抜き&クリーニング作業を、またン千枚もやるかと思うと・・・。
ポキッ あっ! 心の折れた音が。
(2)正解ラベルを指定
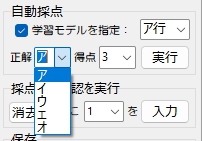
設問ごとに、正解ラベルを選択。学習モデルの識別結果と、ここで選択指定した正解ラベルを比較して、〇・× を判定。で、得点欄に入力(選択)した値を採点記号とともに解答欄の指定位置に表示する。プログラム起動後、初回の実行時にはPython Engineの初期化に数秒かかるが、2回目以降、採点自体は35枚を1秒程度で処理できた☆ だから処理時間に起因するストレスはまったく感じない。Python Engineの初期化だけ、あとで何とかしよう・・・。
(3)自動採点を実行

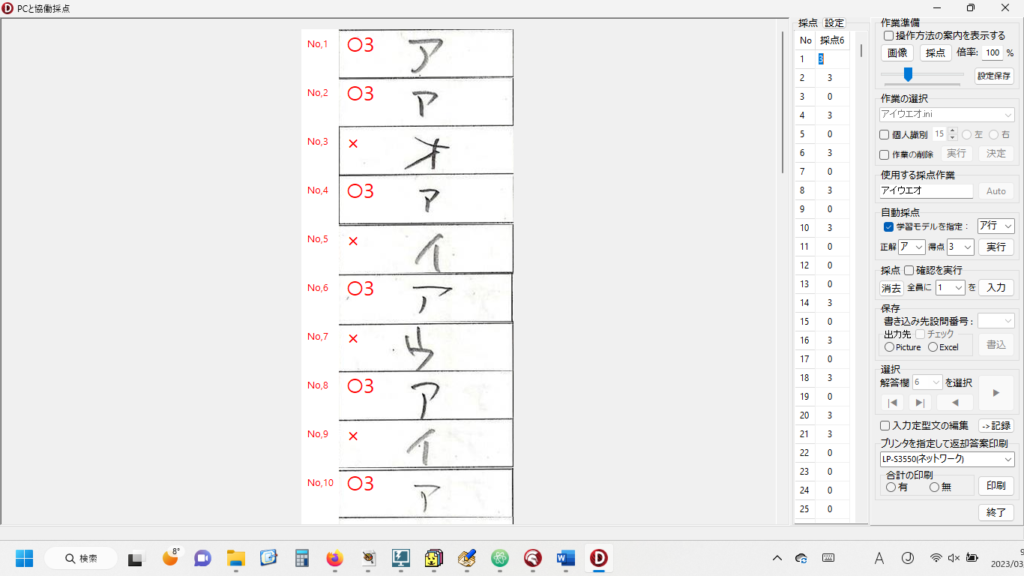
「アイウエオ」の文字データは、集めたサンプルに似せて全部自分で手書きしたもの。文字の大小、濃淡、線の太さ等なるべく不揃いになるようにした(つもり)。解答用紙は新品はもったいないので、職場にあった反故紙の裏面に解答欄を印刷して利用。ホントは、もっとたくさん作成するつもりだったんだけど、35枚書いたところでなんか用事が入り、もうその後は作業を再開する気が失せて、作業を放棄。そのような理由から、とりあえず35枚で実験することに。
ウソ偽りのない採点結果の一例は、次の通り(「ア」を正解とした場合)。

自動採点へのチャレンジを始めたのは2022年の12月下旬だから、ここにたどり着くまでに2ヵ月かかっている・・・。途中、(もはや、これまで)みたいなシーンも何度かあったけど、そのたびに『誰も待ってないけど、オレはやるぞ』と自分自身を叱咤激励。
「オレはやるぞ」と言えば・・・
高校生だった頃、芸術選択はめったにない「工芸」で、すごく楽しくて・・・。焼き物の時間に、みんなは指示された通り、湯飲みとか作ってたけど、僕は「オレはやるぞ!」って文字を刻んだ粘土板(看板)を岩石風の土台に張り付けた、何の役にも立たないモニュメントを製作して、大満足。先生は笑いながらも、僕の作品(?)を炉のすみっこに入れて焼いてくださった。高校生活、最高だったなー☆
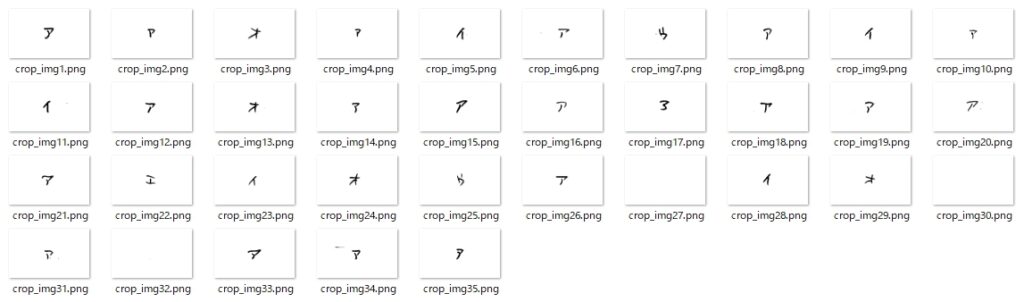
解答欄画像の切り抜きとは別に、プログラム内部では(罫線の影響を排除して)、個々の解答欄画像中の文字をOpenCVの輪郭検出で探し出し、幅64×高さ63で切り抜いて、次に示すような画像データを作成している。

なんで「イ」だけ「字の一部分だけが取得」されてるのか、そこは???なんだけど、その他の文字は、比較的よく検出できているのではないか・・・と思うのですが、いかがでしょう?
輪郭検出のスクリプトは、次のサイトに紹介されていたものを参考に、罫線が入らないようにするなど、様々に工夫を加えて作成。(このスクリプトの作者の方に、心から厚く御礼申し上げます)
https://www.12-technology.com/2021/11/aiocrocretlcdb.html
実際にキカイがどんな画像を見ているのか、気になったので調べてみると・・・

そのうちの1枚を拡大してみたところ。
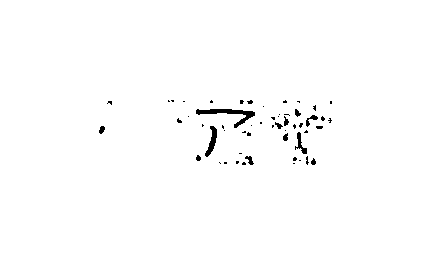
この二値化の処理には、また別のWebサイトにあった次のコードを当てたんだけど・・・
thresh =
cv2.adaptiveThreshold(blur,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2)これは「濃淡の大きな画像に対しては大変有効な処理」のようだけれど、僕の用意した文字画像の処理には向かなかったようで、そこで、ここは思い切って次のように変更。
threshold = 220
ret, thresh = cv2.threshold(blur, threshold, 255, cv2.THRESH_BINARY)上記のように変更した結果、キカイが処理の途中で見ている画像は・・・
さっき拡大した画像は・・・
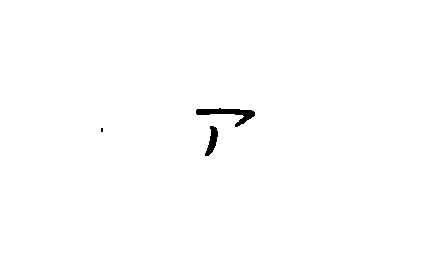
左の方に、小さなシミがまだ残っているけど、これは次のようにして輪郭として検出しないように設定。
contours = cv2.findContours(thresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
num = len(contours)
mylist = np.zeros((num, 4))
i = 0
# red = (0, 0, 255)
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# 高さが小さい場合は無視(ここを調整すれば設問番号を無視できる)
#if h < '+cmbStrHeight.Text+': <- Delphi埋め込み用
if h < 30:
mylist[i][0] = 0
mylist[i][1] = 0
mylist[i][2] = 0
mylist[i][3] = 0
else:
mylist[i][0] = x
mylist[i][1] = y
mylist[i][2] = x + w
mylist[i][3] = y + h
#cv2.rectangle(img, (x, y), (x+w, y+h), red, 2)
i += 1まとめとしては(自分的には)、「ア」のみについて見れば、この設問20問のうち、15問正解で正解率は75%と決して高くはないけれど、「ア」以外のデータはちゃんと見分けているから、ほんとに満足。悔しい気持ちとか、全然、湧いてこない。2022年末のチャレンジで正解率91%だった時は、もう口惜しさの塊みたいになってたのに。なんで全然悔しくないんだろー? 人間ってほんと不思議。
まぁ、これに「自動採点」と銘打って、誰かに販売してお金もらったら完全な詐欺だと思うけど、『発展途上の自動採点モード付き手書き答案採点補助プログラムです。こんなんでも、もし、よかったら、使ってくださいねー! 』・・・というスタンスで仲間にタダでプレゼントする分には(合計点自動計算機能や返却用答案印刷機能等、採点プログラムとしての必須機能が完全に動作すれば)何の問題もないかと・・・。
さらに自動採点と言いながらも、採点の最後にヒトのチェックが必ず必要なのは言うまでもないので、その時、キカイが間違えた5問については、ヒトが「違うよー☆」ってやさしく訂正してあげれば、それこそヒトとキカイの美しい協働・・・じゃないのかなー☆☆☆
いいえ。
そういうのを世間一般には
「言い訳」と言います。
ってか、ここまでは全部、自動採点の準備作業で、ここからが本質的には「始まり」・・・なんだけど、自分的には、かなりヘトヘトになって終了感満載・・・
もしかして、ぼくは、とほーもないことにチャレンジしているのではないか? と、コトここに至って初めて気づく・・・
だって、「アイウエオ」と「〇×」のたった7つPCに教えるのに2ヵ月かかったんだよ。「点くのが遅い蛍光灯のようなお子さんですね」と担任の先生に評された(母親談)という、小学校低学年の児童生徒だったぼくでも、アイウエオくらいは半日で覚えたぞ・・・。
あぁ カー カー キクケコ
サシスセソー
まだ いっぱい あるー☆
4.自動採点を実行!(その2)
文字や記号が印刷された解答欄への対応も、実際問題としては必須。
例えば、次のような画像。

上に示したスクリプトがうまく動作してくれるとイイのだけれど。そう思いながら祈るような気持ちで、上の画像の設問に対して自動採点を実行・・・(正解ラベルは「エ」)。

で、結果は?
なんと100%正解。もしかして、夏休みの自由研究レベルじゃなかった?
予想外の成果に、僕はもう、大満足☆
スキャナーで読み込む際の縮小率とかの問題は未検証だけど、9ポイント程度の大きさで設問番号等は印刷してもらえば、だいたいOKのようだ。手書き文字が小さすぎる場合はどうしようもないけれど、それは事前に「ちいさな文字で解答してはいけません!」と案内しておけば、ある程度は防げるハズ。それでも、ちいさな文字で書くヒトは「チャレンジャー」と見なして・・・
5.〇×記号の学習モデルを作成
2月末、自動採点のGUIを作成しようと、いつもの通り、午前2時に起きて(ジジィは朝が好き / でも出勤はいちばん遅い)「さぁ、やるか」と思った時、なぜか前の晩、眠るときにふと、〇×記号の自動採点用の学習モデルならすぐ作れるんじゃないか・・・と思ったことを思い出し、GUI作りは後回しにして、朝までの4時間で〇×記号の学習モデルを作成することに、当日第1部の予定を変更。
「〇」記号は、ETLデータベースにあったような気がしたので、まずはこちらから。
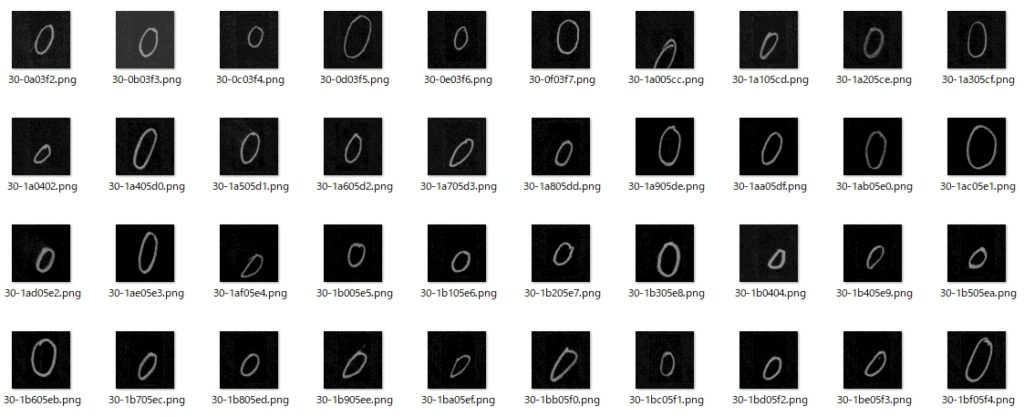
解凍? してあったETL文字データベースの文字・記号が入ったフォルダを一つずつ開けて内容を確認。「48」のフォルダ内に目的の画像を発見。これが1423枚もあれば、訓練用データとしては十分だろうと思い、このデータを機械学習用に加工。
まず、すべてのファイルが連番になるよう、リネーム。
import os
import glob
path = r".\(Pathを指定)\maru"
files = glob.glob(path + '/*')
files = glob.glob(path + '/*')
for i, f in enumerate(files):
# すべてのファイルを連番でリネームする
os.rename(f, os.path.join(path, "maru"+'{0:04d}'.format(i) + '.png'))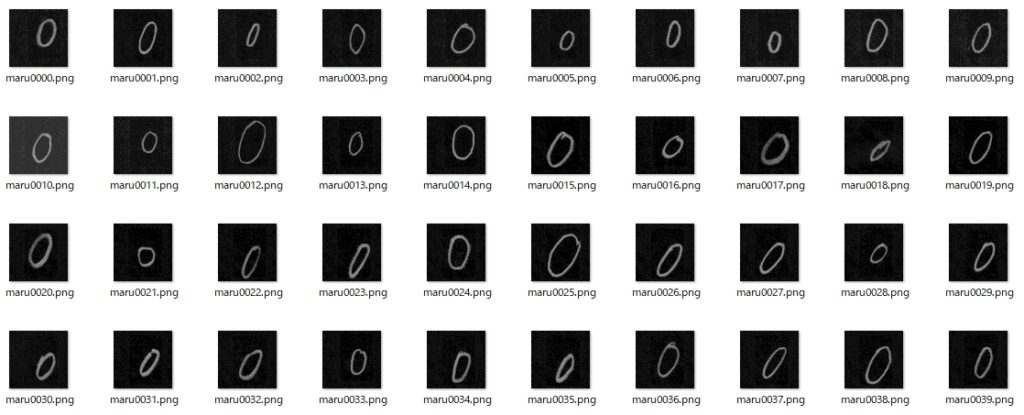
次に「輝度反転」。
# 輝度反転
from PIL import Image
import numpy as np
from matplotlib import pylab as plt
for i in range(1423):
# 画像の読み込み
im = np.array(Image.open(r".\(Pathを指定)\maru"+r"\maru"+"{0:04d}".format(i) + ".png").convert("L"))
# 読み込んだ画像は、uint8型なので 0~255 の値をとる
# 輝度反転するためには、入力画像の画素値を 255 から引く
im = 255 - im[:,:]
print(im.shape, im.dtype)
#保存
Image.fromarray(im).save(r".\(Pathを指定)\maru"+r"\r_maru"+"{0:04d}".format(i) + ".png")
さらに、二値化する。
もしかしたら、上の輝度を反転させた画像のまま、機械学習を実行してもいいのかも? とチラっと思ったが、一度、最も極端な方向(=二値化で白黒にする)に振ってみて実験し、その結果を見てから判断することに決めて、二値化を実行。
import cv2
import os
import glob
path = r".\(Pathを指定)\maru_nichika"
files = glob.glob(path + '/*')
for f in files:
# 読み込み
im = cv2.imread(f)
# グレースケールに変換
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
# 大津の二値化
th, im_gray_th_otsu = cv2.threshold(im_gray, 0, 255, cv2.THRESH_OTSU)
# 書き込み
cv2.imwrite(f, im_gray_th_otsu)
二値化した画像中に訓練用データとして不適切な画像がないか、念のため、チェックしたところ、いくつかの不適切なデータを発見したため、それらは削除した。


これで「〇」記号の訓練用データは完成。次は「×」記号。
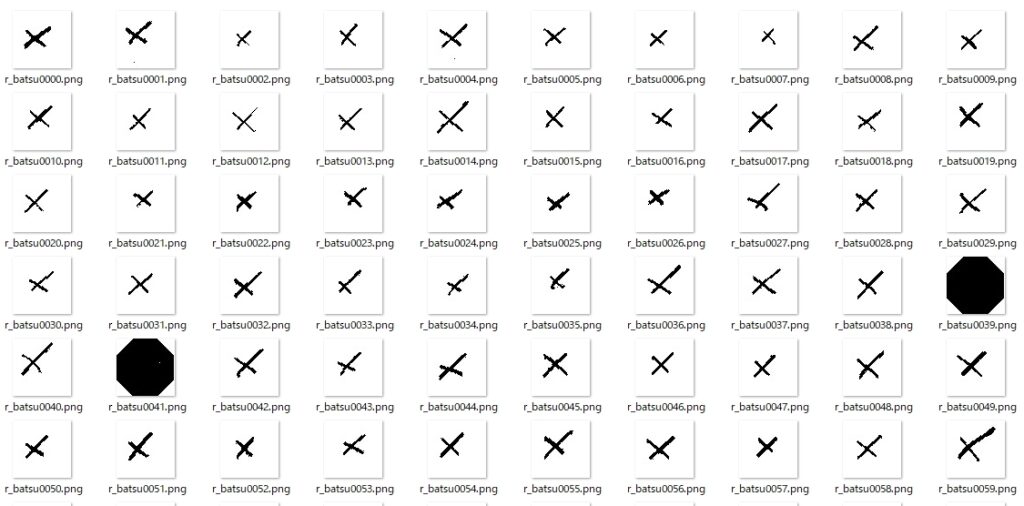
残念ながら、「×」記号のデータはETL文字データベースにはないようだ・・・。しかし、代替できそうなデータを「43」のフォルダに発見。それは「+」記号。これを45度ほど右か左へ回転させてあげれば、「×」に見えるんじゃないか? と・・・。

画像の回転スクリプトは・・・
from PIL import Image
import os
import glob
path = r".\(Pathを指定)\batsu"
files = glob.glob(path + '/*')
for f in files:
# ファイルを開く
im = Image.open(f)
# 回転
im_rotate = im.rotate(45)
# グレースケールへ変換
img_gray = im_rotate.convert("L")
# 画像のファイル保存
img_gray.save(f)
普通の「×」記号は、「\」が短くて、「/」が長い。上の画像は、ことごとくそれが逆だから違和感を覚えるんだと気づき、さらに90度回転させる。

で、「〇」記号と同様に、リネーム & 輝度反転させて、二値化。
次は、Lobeで機械学習を実行。「〇:maru」と「×:batsu」だから「mb」という名前のフォルダを作成。「〇」記号はフォルダ名を半角数字の「0:ゼロ」、「×」記号はフォルダ名を半角数字の「1」に設定(認識結果の正解ラベルが 0 or 1 で返るようにするため)。
データが準備できたので、Lobeを起動。機械学習を実行。最終的に用意できた訓練データは「〇」記号が「1406」、「×」記号が「1323」。ここまで、なんだ・かんだで3時間半。さらに待つこと30分。東の空が明るくなる頃、ついに「〇×」記号の学習モデルが完成した。シャワーを浴びて出勤。さぁ 今日も第2部の始まりだー☆
6.〇×記号の解答も自動採点
プログラムの中では、次のようにして、採点対象を切り替えている。
strScrList.Add(' if 黒の面積 > 1.5:'); # 白->黒へ訂正(20230306)
・・・画像ファイルへのPathを設定等・・・
strScrList.Add(' if os.path.isfile(img):');
・・・画像ファイルを開く・・・
if cmbAS.Text='○×' then
begin
strScrList.Add(' if outputs["label"] == "0":');
strScrList.Add(' var1.Value = str("○") + "," + ・・・
strScrList.Add(' elif outputs["label"] == "1":');
strScrList.Add(' var1.Value = str("×") + "," + ・・・
strScrList.Add(' else:');
strScrList.Add(' var1.Value = str("Unrecognizable")');
strScrList.Add(' else:');
strScrList.Add(' var1.Value = str("Could not find image file")');
strScrList.Add(' else:');
strScrList.Add(' var1.Value = str("XXX")');
end;
if cmbAS.Text='ア行' then
begin
strScrList.Add(' if outputs["label"] == "0":');
strScrList.Add(' var1.Value = str("ア") + "," + ・・・
strScrList.Add(' elif outputs["label"] == "1":');
strScrList.Add(' var1.Value = str("イ") + "," + ・・・
strScrList.Add(' elif outputs["label"] == "2":');
strScrList.Add(' var1.Value = str("ウ") + "," + ・・・
strScrList.Add(' elif outputs["label"] == "3":');
strScrList.Add(' var1.Value = str("エ") + "," + ・・・
strScrList.Add(' elif outputs["label"] == "4":');
strScrList.Add(' var1.Value = str("オ") + "," + ・・・
strScrList.Add(' else:');
strScrList.Add(' var1.Value = str("Unrecognizable")');
strScrList.Add(' else:');
strScrList.Add(' var1.Value = str("Could not find image file")');
strScrList.Add(' else:');
strScrList.Add(' var1.Value = str("XXX")');
end;正解を「〇」記号として、自動採点してみた結果は・・・
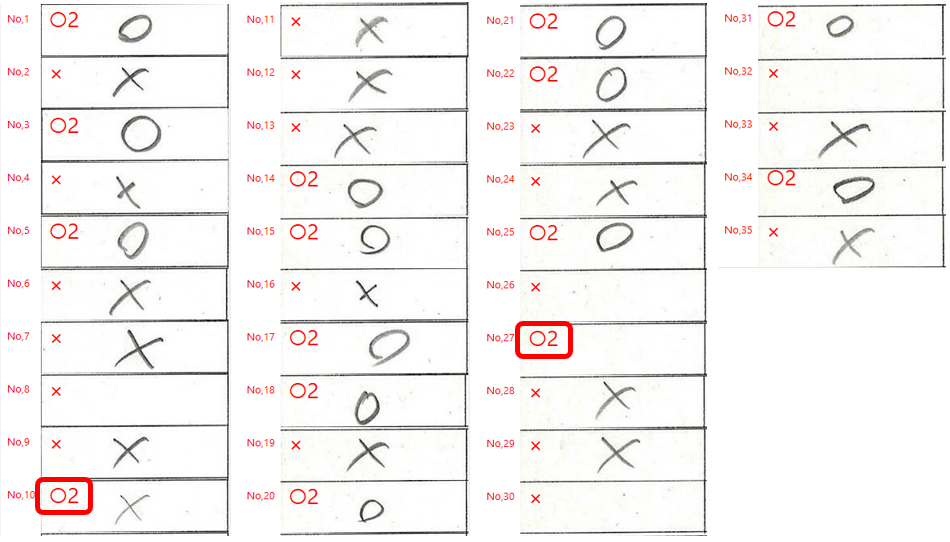
空欄であるにもかかわらず、正解となっている画像をよく調べてみると・・・
高さが30未満である場合は、輪郭検出しない設定のはずなんだが・・・。他には何にも見つけられないので、原因はコレしか考えられない。いったいナニがどうなっているんだろう??? 結局、コレは謎のままに。
同じデータに対して、正解を「×」記号として自動採点すると・・・

10個目のデータの切り抜き画像を調べてみると・・・

どうやら元画像の「色が薄い」 or 「画像の線が太い」と問題が発生する傾向が強い気がしてきた。僕はこの実験に「えんぴつ」を使ったが、普通、試験時解答に使うのはシャーペンだから線が太くなることはあまり考えられない、むしろ、なるべく濃く書くことを注意事項に入れるべきかもしれない。なお、幅が狭くなっているように見えるのは、画像を強制的に幅64×高さ63にリサイズしているためだ。
「アイウエオ」同様、「〇×」記号の自動採点も残念ながらヒトの最終チェックがどうしても必要だという結果になった。が、こちらも「採点補助」程度には使えるぞ。
7.FormCreateでPythonEngineを初期化
何度も実験していると、プログラム起動後、初回の自動採点実行時、Python Engineの初期化に数秒を要するところを何とかしたくなってきた。これは起動後、毎回必ず発生する現象なので、マウスカーソルを待機状態にするとか、そういうレベルで誤魔化せる話ではない。なるべくユーザーの気づかないところで(ソッと)初期化してしまわなくてはならない。
いちばんイイのはプログラム起動時だ。マークシートリーダーを作った時にもこのことが気になったため、スプラッシュ画面を表示して(画像は自前で準備した画像ではなく、Webで販売している画像を購入して使用するという暴挙に出た)、その裏側で初期化作業を行うよう設定。今回も、このやり方を踏襲。
(1)初期化に使う画像をリソースに準備
Python Engineを初期化するには画像が必要なので、専用画像をリソースに準備。
(2)初期化処理を実行
プログラム起動時、FormCreate手続きの中で、次のように初期化処理を実行。
まず、リソースに埋め込んだ初期化用画像ファイルを再生。
//リソースに読み込んだ初期化用ファイルを再生
//ファイルの位置を指定
strFileName:=ExtractFilePath(Application.ExeName)+'imgAuto\tmp\maru.png';
//ファイルの存在を確認
if not FileExists(strFilename) then
begin
//リソースを再生
with TResourceStream.Create(hInstance, 'pngImage_1', RT_RCDATA) do
begin
try
SaveToFile(strFileName);
finally
Free;
end;
end;
end;次に、Python Engineそのものを初期化。
//embPythonの存在の有無を調査
AppDataDir:=ExtractFilePath(Application.ExeName)+'Python39-64';
if DirectoryExists(AppDataDir) then
begin
//フォルダが存在したときの処理
PythonEngine1.AutoLoad := True;
PythonEngine1.IO := PythonGUIInputOutput1;
PythonEngine1.DllPath := AppDataDir;
PythonEngine1.SetPythonHome(PythonEngine1.DllPath);
PythonEngine1.LoadDll;
//PythonDelphiVar1のOnSeDataイベントを利用する
PythonDelphiVar1.Engine := PythonEngine1;
PythonDelphiVar1.VarName := AnsiString('var1');
//初期化
PythonEngine1.Py_Initialize;
end else begin
//MessageDlg('Python実行環境が見つかりません!',mtInformation,[mbOk], 0);
PythonEngine1.AutoLoad := False;
end;最後に初期化用画像を読み込んで、1回だけ自動採点を実行する。
//スプラッシュ画面を表示してPython Engineを初期化
try
theSplashForm.Show;
theSplashForm.Refresh
//Scriptを入れるStringList
strScrList := TStringList.Create;
//結果を保存するStringList
strAnsList := TStringList.Create;
try
strScrList.Add('import json');
・・・略(自動採点用のPythonスクリプトをStringListに作成)・・・
//0による浮動小数除算の例外をマスクする
MaskFPUExceptions(True);
//Execute
PythonEngine1.ExecStrings(strScrList);
//先頭に認識した文字が入っている
if GetTokenIndex(strAnsList[0],',',0)='○' then
begin
//ShowMessage('The Python engine is now on standby!');
theSplashForm.StandbyLabel.Font.Color:=clBlue;
theSplashForm.StandbyLabel.Caption:='The P_Engine is now on standby!';
theSplashForm.StandbyLabel.Visible:=True;
Application.ProcessMessages;
//カウントダウン
for j:= 2 downto 1 do
begin
theSplashForm.TimeLabel.Caption:=Format('起動まであと%d秒', [j]);
Application.ProcessMessages;
Sleep(1000);
end;
end else begin
ShowMessage('Unable to initialize python engine!');
MessageDlg('Auto-scoring is not available!'+#13#10+
'Please contact your system administrator.',mtInformation,[mbOk],0);
end;
finally
//StringListの解放
strAnsList.Free;
strScrList.Free;
end;
finally
theSplashForm.Close;
theSplashForm.Destroy;
end;これで「自動採点GroupBox」内の「実行」ボタンをクリックした際の処理が、ほぼ待ち時間なしで行われるようになった。これをやっておくのと、おかないのとでは、プログラムの使用感がまったく異なってくる・・・。上記のプログラムの for j := 2 downto 1 do 部分を「ムダ」だと思う方もいらっしゃるかもしれませんが、「画像の使用権を購入」してまで表示したスプラッシュ画面なので、せめて2秒間だけ!必要以上に長く表示させてください・・・。
8.まとめ
準備に2ヵ月を要したが、なんとか手書きカタカナ文字の自動採点まで到達。結果は自分的には概ね満足できるものであったが、「実用に適するか」という点では、まだまだブラッシュアップが必要。今回の実験で得たことは、学習モデルを適用する「文字画像の切り抜き精度」の重要性。Lobeで作成した学習モデルは間違いなく優秀。その性能を遺憾なく発揮させる「場」を、僕は準備・提供しなければならない。これこそが今後の課題。
あいん つばい どらい
唯 歩めば至る・・・
コトここに至ってようやく・・・
これは、とほーもないチャレンジだと気づいたけれど。
もう行くしか ない 。
僕も、プログラムも、きっともっとよくなれる。
よくなるんだ!
9.お願いとお断り
このサイトの内容を利用される場合は、自己責任でお願いします。ここに記載した内容を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。
本記事内で紹介させていただいた実験結果は、あくまでも私自身が用意した文字データに対してのものであり、別データで実験した場合、同様の結果が得られることを保証するものではありません。