久しぶりに、上のキーワードで Google 検索して、びっくり しました。
なんと! 検索結果の・・・ いちばん上に! ・・・ 僕のプログラムが、表示されてる・・・
(⊙_⊙)
正直。うれしいより先に
やばい!
・・・と、思いました。
( 何ページ目くらいに表示されるのかなー☆ )
本当に、それが、これまでに何度も、何回も繰り返した、僕の blog を Google 検索する時の想い。
( 誰か、見てくれないかなー。読んでもらえたら、うれしいなー☆ )
だから、3ページ目くらいに記事があると、「うん。うん。」って、安心してた・・・。
blog を書くこと自体が、自分の存在確認の行為に他ならないのだけれど・・・
これは本当に思い上がりとか、謙遜とか、そのどちらでもなく・・・
普通に考えて・・・
僕の blog とプログラムが
Google の検索結果で
トップに表示されるわけがない。
どう考えても、それが僕のいる世界の「本当」・・・のはず、なのに ・・・
突然! 目の前に表示された「画面」という現実を、それでもなお、信じられない気持ちで、眺めつつ。
夢なら覚めないでほしい
そう思ったのも、また、事実です。
この2年間の日々は、色々な意味で、ほんとうに、本当に、苦しかった・・・。
人の立場の違いは、その評価をも、真逆に変える。
あの日、拍手で歓迎されたプログラムが、ただのゴミ以下になる・・・
僕は、そのほんとうを・・・ 確かに、この目で、見ました。
失意のどん底にある僕を支えてくださった多くの方々に、心から感謝申し上げます。
だから、Google 先生の、僕の blog とプログラムへの評価は、世の中が僕の夢を応援してくれている証明のように思えて、「やばい」と思ったのは本当ですが、やはり、とても、うれしかったのです。
で、問題は「やばい」と感じた理由・・・ そう、今回の記事を書く きっかけ です。
2年前、同僚の要請に応えるかたちで、手書き答案をスキャンして得た画像から個々の解答欄画像を切り出して一括採点し、採点記号その他を付加して元の画像に書き戻すデジタル採点プログラムの最初のバージョンを書き、「表形式」の解答欄を読み取って処理するので「Answer Column Reader = AC_Reader」と名付けたのですが・・・
その時点で、プロの書いたデジタル採点システムにあって、僕のプログラムにないもの・・・
そう「○・×」、「ア・イ・ウ・エ・オ」、「A・B・C」、「1・2・3」みたいな記号・文字または数字1字の解答であれば自動採点できる機能を僕のプログラムにも搭載したいと、僕はごく自然な流れで考えたのです。
当時、年末・年始の休暇を含めて、ほぼ2か月間、手書き文字の認識に没頭した記憶があります。
その記録は当 blog の過去記事にある通りです。
いずれも、他人様の実験結果を、ただ真似しただけの、読むに値しない記事ですが・・・
生成 AI なんてまだなかったあの頃・・・(知らないところで、それは・・・ ほぼ出来上がりつつあったのだろうけれど・・・。 そう、考えると同時期にレベルの差はあれど、まったく同じ研究をやったと言うことで、たまらなく誇らしいような、いや、それはただの偶然の一致で・・・ 一方は AI というカタチで見事にモノになり、僕のは無駄な努力で終わり・・・もし、プログラムが当時のまま、今後進化しないのであれば・・・ みたいな複雑な気持ちではありますが )、いずれにしても、その時、僕は Google 先生を頼りに『 機械学習の真似事 』を行い、右も、左も、わからないまま、結局 keras や Lobe のお近づきになれたよーな・・・ なれなかったよーな・・・
日々を過ごしたことだけは、事実。( 2022年、春 )
で、結論だけ言うと、お遊び程度に使える自動採点機能を搭載したプログラムが書けました。・・・ただ、書けたことは書けたのですが、使用したライブラリが TensorFlow で、これには 32 ビット版がなく、仕方がないからプログラムは無理して 64 ビット化して作成。
その結果、 AC_Reader に同梱して使うその他のプログラム( My マークシートリーダー = MS_Reader.exe 等)が 32 ビット版であること、つまり、内部で共通に呼び出して使っている Embeddable Python も 32 ビット版であることから、 AC_Reader と My マークシートリーダーとが共存するには Embeddable Python を共用しなければならないというところが大問題に。結局、64 ビット版の AC_Reader は使用を断念。版を 32 ビットに戻すと同時に、64 ビット版の AC_Reader に搭載した自動採点機能は、32 ビット版で泣く泣く削除。
あれから2年間。AC_Reader は、ほぼ、放置状態。
(表計算ソフトを使わずに、成績一覧表を出力できるようにする等、採点に伴う作業を軽減できるよう、付属的なプログラムを新たに作成すると言った、おまけ的な面で多少の改善は加えましたが、手書き答案の採点という、本業面での進化は、よく使う機能を集めてフローティングパネル化した程度)
そう、せっかく Google 先生が評価してくれたのに、プログラム本体が2年間まったく進化していないことが、心から「やばい」と感じた理由なのです。
苦しかった、この2年間を、その理由にしてはいけないのですが・・・
それでも、僕を支えてくださった方々の要望には、何としても応えたいという思いがあり・・・
必死の思いで、過去記事「組み合わせ採点を実現したい!」に書いた内容を組み込んだ答案返却用答案(?)を作成・印刷する新しいプログラムを書き、採点現場での実地テストを無事終え、そちらを「ReportCard_2025」として公開すべく、準備を進めていたのですが、先に書いた検索結果を目の当たりにして、こちらをいったん中止。
AC_Reader を2年ぶりに進化させることに決めました。
内容はもちろん、自動採点機能の搭載です。
【もくじ】
1.32ビット版で自動採点機能を搭載できないか?
2.Tesseract-OCR を使う
3.scikit_learnを使う
(1) Embeddable Python へのインストール
(2) 学習モデルを作成して認識テスト
4.とんでもない認識結果に驚愕する
5.まとめ
6.お願いとお断り
1.32ビット版で自動採点機能を搭載できないか?
Delphi もバージョン 12.3 では「 RAD Studio 12 ( 64-bit Initial Release ) 」がついに登場。機械学習の現場でも 64 ビット化はさらに加速しつつあり、今更、32 ビットにこだわる必要などないと自分でも思うし、64ビット化の流れに反対する気持ちなどまったくないのですが・・・
ただ、これまでに書いてきたプログラムをすべて64ビット化するのは大変だし、その前に、32 ビット版に今すぐできる改良があるなら、それを行えば、より良いものをユーザーに提供できる可能性が 32 ビット版のプログラムにも、まだ残されている気がして・・・
「 より良いもの 」・・・ それこそが 32 ビット版 AC_Reader への自動採点機能の搭載だと思いました。
あれから2年経過して、手書き文字認識や機械学習のプログラム自体も相当進化しているのではないかと考え、まず、思い出したのは Tesseract-OCR です。
2.Tesseract-OCR を使う
他にも思い出せるモノはたくさんあったんだけど、機械学習系は手書き文字の認識の前に、大量のデータを集めてトレーニングして・・・ といった学習(の手間)が必要なので、そういった手間のいらないところから搭載の可否を探ろうと思ったわけです。「寄らば大樹の陰・・・」みたいな。
手書き文字でない、既存の TrueType 日本語フォントに対してなら、Tesseract-OCR がどれほど素晴らしい性能を発揮するか、それは2年前に目の当たりにしています。ただ、残念ながら、手書き文字の認識といった部分では、2年前はお世辞にも良好とは言えなかったと記憶しています。
早速、最新版(?)をダウンロード( tesseract-ocr-w32-setup-v5.3.0.20221214.exe :これより新しい 32 bit版は探せなかった)して、実験してみました。日付が、ちょっと古いのが気になりましたが。もしかして、2年前もコレで実験した? みたいな感が・・・。
手書き文字は、次のような実験用サンプルを700個(すべて「ア」の画像)ほど用意。

実験に使った Python スクリプトは、コレ!
画像から抽出する文字は「アイウエオ」の中の1字。画像が「ア」であると判定すれば「ア」を出力、「アイウエオ」のいずれでもない(=判定不能である)場合は「N」を出力する。
import cv2
import pytesseract
import re
import os
# Tesseract-OCRのパス設定
pytesseract.pytesseract.tesseract_cmd = r"C:\Python39-32\Tesseract-OCR\tesseract.exe"
def preprocess_image(image_path):
""" 画像を前処理してOCRに適した状態にする """
# グレースケール化
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 二値化
_, binary = cv2.threshold(image, 128, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
return binary
def extract_katakana(image):
""" OCRでカタカナを認識する """
custom_oem_psm = "--oem 3 --psm 10 -l jpn"
text = pytesseract.image_to_string(image, config=custom_oem_psm)
# カタカナ1文字のみを抽出
# match = re.search(r'[アイウエオ]', text)
return match.group(0) if match else "N"
def process_images_in_folder(folder_path):
""" 指定フォルダ内のすべての画像を処理 """
image_extensions = (".png", ".jpg", ".jpeg", ".bmp", ".tif", ".tiff")
for filename in os.listdir(folder_path):
# 画像ファイルのみ処理
if filename.lower().endswith(image_extensions):
image_path = os.path.join(folder_path, filename)
processed_image = preprocess_image(image_path)
result = extract_katakana(processed_image)
print(f"{filename}: OCR結果 -> {result}")
if __name__ == "__main__":
# 画像が入っているフォルダのパス
folder_path = "Images_Tegaki\img1_a"
process_images_in_folder(folder_path)
結果は次の通り。

「N」はともかく、なんで「イ」があるのかなー?
全体の集計では・・・
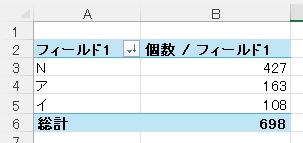
正解率は 23.3 % ・・・
ただ、「ウ・エ・オ」はありませんでした。そこで・・・
match = re.search(r'[ア]', text)「ア」1文字で勝負してみました。結果はまったく同じでありました!
よくよく考えれば、同じ文字認識アルゴリズムで「ア」を判定しているのですから、これは当然です。
64 bit バージョンの方は最新版が「最近の日付」でしたから、これより良い結果が得られる可能性があるような気がしますが、僕が使いたい 32 bit バージョンに限っての話をしていますので、この時点で手書き文字の認識に Tesseract-OCR の 32 bit バージョンを使用するか、否か、という問題は、はっきり「 否 」と答えが出ました。
過去の記事にも書きましたが、これは「手書き文字の認識(それも「ア」1文字)」に限った話であり、他のカタカナ文字については実験もしておりませんし、これを持って、Tesseract-OCR 32 bit バージョンの総合的な「手書き文字」を認識する性能を否定する意図はまったくありません。
日本語 TrueType フォントの書体であれば、Tesseract-OCR は十分実用的な精度で文書をテキスト化してくれる素晴らしいプログラムです!!
3.scikit_learnを使う
(1) Embeddable Python へのインストール
次に思い出したのが keras だったのですが、2年前の実験における手書きカタカナ文字「アイウエオ」の認識率は 95 ~ 97 %程度(文字によって差がある)で、これ以上はどう頑張ってもダメだった記憶が同時に蘇り・・・
AI に聞いてみると、「 keras も進化してます!」とのことでしたが、ここで、ふと、思い立ち、
「 32 bit で動作するプログラムで、手書き文字認識が可能な Python で動作するオープンソースの機械学習ライブラリは何?」と尋ねてみると・・・
scikit-learn です!
・・・との答えがトップに表示されました。
( scikit-learn ・・・ )
scikit-learn は2年前にも試していません。名前は聴いたことがあったような気がしますが・・・
AI の説明には、心揺さぶられるような文言が並び!!!
曰く、軽量で依存が少ない。
曰く、古いマシンでも動作しやすい。
さらに・・・
「SVM(サポートベクターマシン)などでの文字認識は、軽量で精度も悪くないです。」
とのこと。
サポートベクターマシンってのが、よくわからなかったので、さらに質問して見ると・・・
「サポートベクターマシン(SVM:Support Vector Machine)」は、分類や回帰に使える機械学習のアルゴリズムの一種で、scikit-learn が得意なことは、「はっきりと分けられる2つのクラス分類」であるとのこと。まさに「手書き文字認識」のためにあるようなライブラリ。何で2年前、scikit-learn を試さなかったのか・・・。後悔先に立たず。試さなかった事実は事実。それは認めるしかありません。でも、今、僕は、まだ、生きていて、あの頃は読めなかった AI のアドバイスを、今、読んでる・・・
「他のライブラリにほぼ依存せず、古いPCでも動き、軽量で、精度も悪くない。」
だんだん、だんだん、生成 AI の言うことを信じて、動かしてみたい気になってきました☆
※ ちなみに「回帰」もわからなかったので調べて見ると、「 回帰(Regression)」は、予測したい結果が “数値” のときに使う機械学習の手法であるとのこと。「分類(Classification)とセットでよく出てくる」言葉なんだそうです。確かに、どこかで何度も目にしたことがあるような・・・。今、僕がやりたいのは「分類(Classification)」の方ですが、大変、勉強になりました!!
とりあえず、scikit-learn を入手して、それをインストールしなければ話は始まらない。
scikit-learn をインストールする予定の Embeddable Python を入れた Python39-32 フォルダをデジタル採点関係のプログラムを保存しているフォルダから、C:¥へコピーする。
ちなみに Python39-32 の 39 は Python のバージョン、32 は 32 bit 版という意味です。
なんでそんなことをしたかというと、Pathを短くするため。Python関連のプログラムをいじる時は、コマンドプロンプトで作業するのでPathが出来るだけ短い方が作業しやすいのです。
そうしておいて、AI の力を借りて、scikit-learn の 32 bit 版を探します。(実際にはここでかなりの時間を loss しているのですが)その結果わかったことは「通常の pip install scikit-learn でのインストールは 32ビット環境では失敗することが多い」ということ。なので、より確実にインストール可能なWindows用ホイールファイル(=拡張子が whl のファイル)を探すことにしました。
【参考】Windows用ホイールファイル(.whl)
Pythonで使用されるパッケージ形式のひとつ。Pythonのライブラリやモジュールを効率的にインストールできるファイルで、次の特徴がある。
・事前にビルドされたパッケージなので、必要なコードや依存関係がすべて含まれている。
・ソースコードをビルドする必要がないため、Windows 環境でのインストールが簡単になる。
・pip でインストールできる。
例: pip install scikit_learn-0.24.2-cp39-cp39-win32.whl予想通り、世の中は 64 bit 版へ移行しつつあり、scikit-learn の 32 bit 版の最新版は「2021年4月28日」の日付がある「scikit_learn-0.24.2-cp39-cp39-win32.whl」のようです(違うかもしれません)。
以下、実際に僕が行ったインストール作業の様子です。
cp39 だから Python3.9.X に対応しており、win32 だから 32 bit 対応版であることがわかります。検索したらいちばん上に「 Pypl 」の「 scikit-learn 0.24.2 」が表示されました。リンクをたどって、https://pypi.org/project/scikit-learn/0.24.2/ へ行き、さらにページの左側にある「ファイルをダウンロード」をクリックしてダウンロードページへ行き、Built Distributions の上から2番目に目的の「scikit_learn-0.24.2-cp39-cp39-win32.whl」を発見。これをダウンロードして、Python39-32 フォルダへコピー。
コマンドプロンプトを起動していちばん最初に行うことは、この場合、pip のアップデートです。Embeddable Python に Numpy や OpenCV をインストールした時、Embeddable Python で pip を使う方法の詳細なメモを残しておいたので、それを見ながら作業を進めます。
C:\>cd Python39-32
C:\Python39-32>python -m pip install --upgrade pip
Requirement already satisfied: pip in c:\python39-32\lib\site-packages (22.3.1)
Collecting pip
Using cached pip-25.0.1-py3-none-any.whl (1.8 MB)
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 22.3.1
Uninstalling pip-22.3.1:
Successfully uninstalled pip-22.3.1
WARNING: The scripts pip.exe, pip3.9.exe and pip3.exe are installed in 'C:\Python39-32\Scripts' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed pip-25.0.1僕のはもう設定してあるから、次の作業は不要だけれど、必要な方がいるかもしれないので参考までに書くと・・・ まずは、Embeddable Python で pip を使えるようにする方法。
デフォルトの python.exe では import site が無効になっているため、外部ライブラリをインポートできない。
解決策: python._pth を編集する
python._pth(python.exe と同じフォルダにある)を開く
#import site のコメントアウトを解除(# を削除)
# python36.zip
# ./DLLs
# ./Lib
# ./Lib/site-packages
import site # ← コメントアウトを外す
# Uncomment to run site.main() automaticallyさらに、pip を有効化するために次の作業も行う。
pip は Embeddable Python には入っていないので、次の方法で pip を使えるようにする。
(1) get-pip.py をダウンロード
get-pip.py を 公式サイト(https://bootstrap.pypa.io/get-pip.py)からダウンロード
C:\Python39-32(僕の場合) に配置
(2) pip をインストール
C:\Python39-32\python.exe get-pip.py
(3) pip でライブラリをインストール
C:\Python39-32\python.exe -m pip install requestsあと、環境変数を設定するには・・・
set PYTHONHOME=C:\Python39-32
set PYTHONPATH=C:\Python39-32\Lib
C:\Python-Embed\python.exe XXX.py # <-Pythonスクリプトの実行ここまで行えば、pip が使えるので、ダウンロードした scikit_learn-0.24.2-cp39-cp39-win32.whl のインストールが可能になる。
後で Python スクリプトも実行するので、環境変数の設定も行いつつ・・・
C:\Python39-32>set PYTHONHOME=C:\Python39-32
C:\Python39-32>set PYTHONPATH=C:\Python39-32\Lib
C:\Python39-32>set PYTHONPATH=C:\Python39-32\Scripts # <-効いてない気がするが・・・ただ、ここでいきなり scikit_learn をインストールしようとすると失敗します。
C:\Python39-32>python.exe -m pip install C:\Python39-32\scikit_learn-0.24.2-cp39-cp39-win32.whl
Processing c:\python39-32\scikit_learn-0.24.2-cp39-cp39-win32.whl
Requirement already satisfied: numpy>=1.13.3 in c:\python39-32\lib\site-packages (from scikit-learn==0.24.2) (1.21.5)
Collecting scipy>=0.19.1 (from scikit-learn==0.24.2)
Using cached scipy-1.13.1.tar.gz (57.2 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
ERROR: Exception:
Traceback (most recent call last):
File "C:\Python39-32\lib\site-packages\pip\_internal\cli\base_command.py", line 106, in _run_wrapper
status = _inner_run()
File "C:\Python39-32\lib\site-packages\pip\_internal\cli\base_command.py", line 97, in _inner_run
return self.run(options, args)
File "C:\Python39-32\lib\site-packages\pip\_internal\cli\req_command.py", line 67, in wrapper
return func(self, options, args)
File "C:\Python39-32\lib\site-packages\pip\_internal\commands\install.py", line 386, in run
requirement_set = resolver.resolve(
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\resolver.py", line 95, in resolve
result = self._result = resolver.resolve(
File "C:\Python39-32\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 546, in resolve
state = resolution.resolve(requirements, max_rounds=max_rounds)
File "C:\Python39-32\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 427, in resolve
failure_causes = self._attempt_to_pin_criterion(name)
File "C:\Python39-32\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 239, in _attempt_to_pin_criterion
criteria = self._get_updated_criteria(candidate)
File "C:\Python39-32\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 230, in _get_updated_criteria
self._add_to_criteria(criteria, requirement, parent=candidate)
File "C:\Python39-32\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 173, in _add_to_criteria
if not criterion.candidates:
File "C:\Python39-32\lib\site-packages\pip\_vendor\resolvelib\structs.py", line 156, in __bool__
return bool(self._sequence)
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\found_candidates.py", line 174, in __bool__
return any(self)
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\found_candidates.py", line 162, in <genexpr>
return (c for c in iterator if id(c) not in self._incompatible_ids)
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\found_candidates.py", line 53, in _iter_built
candidate = func()
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\factory.py", line 187, in _make_candidate_from_link
base: Optional[BaseCandidate] = self._make_base_candidate_from_link(
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\factory.py", line 233, in _make_base_candidate_from_link
self._link_candidate_cache[link] = LinkCandidate(
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\candidates.py", line 304, in __init__
super().__init__(
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\candidates.py", line 159, in __init__
self.dist = self._prepare()
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\candidates.py", line 236, in _prepare
dist = self._prepare_distribution()
File "C:\Python39-32\lib\site-packages\pip\_internal\resolution\resolvelib\candidates.py", line 315, in _prepare_distribution
return preparer.prepare_linked_requirement(self._ireq, parallel_builds=True)
File "C:\Python39-32\lib\site-packages\pip\_internal\operations\prepare.py", line 527, in prepare_linked_requirement
return self._prepare_linked_requirement(req, parallel_builds)
File "C:\Python39-32\lib\site-packages\pip\_internal\operations\prepare.py", line 642, in _prepare_linked_requirement
dist = _get_prepared_distribution(
File "C:\Python39-32\lib\site-packages\pip\_internal\operations\prepare.py", line 72, in _get_prepared_distribution
abstract_dist.prepare_distribution_metadata(
File "C:\Python39-32\lib\site-packages\pip\_internal\distributions\sdist.py", line 56, in prepare_distribution_metadata
self._install_build_reqs(finder)
File "C:\Python39-32\lib\site-packages\pip\_internal\distributions\sdist.py", line 126, in _install_build_reqs
build_reqs = self._get_build_requires_wheel()
File "C:\Python39-32\lib\site-packages\pip\_internal\distributions\sdist.py", line 103, in _get_build_requires_wheel
return backend.get_requires_for_build_wheel()
File "C:\Python39-32\lib\site-packages\pip\_internal\utils\misc.py", line 702, in get_requires_for_build_wheel
return super().get_requires_for_build_wheel(config_settings=cs)
File "C:\Python39-32\lib\site-packages\pip\_vendor\pyproject_hooks\_impl.py", line 196, in get_requires_for_build_wheel
return self._call_hook(
File "C:\Python39-32\lib\site-packages\pip\_vendor\pyproject_hooks\_impl.py", line 402, in _call_hook
raise BackendUnavailable(
pip._vendor.pyproject_hooks._impl.BackendUnavailable: Cannot import 'mesonpy'最初に コレ を見たときは マジ 泣きたくなりました・・・ T_T
いろいろ調べて見ると、どうやら最後に出てくる MesonPy に原因があるらしいことがわかりました。と、言うのは、scikit_learn と同時にインストールされる scipy には mesonpy というビルドツールが必要で、それが 32ビット環境では動作しないことがエラーの原因とのこと。どうやら MesonPy は 32 bit 版に対応していないようです。じゃあ、どうするかと言うと、最初に scipy を単体でインストールします。
次のサイトにアクセスし、Python 3.9 (32bit) 対応の scipy の .whl をダウンロードします。
https://www.lfd.uci.edu/~gohlke/pythonlibs/#scipy上のサイトに「scipy-1.9.0-cp39-cp39-win32.whl」があったので、これをダウンロードして、Python39-32 フォルダへコピー。で、pip を使ってインストールします。
C:\Python39-32>python.exe -m pip install C:\Python39-32\scipy-1.9.0-cp39-cp39-win32.whl
Processing c:\python39-32\scipy-1.9.0-cp39-cp39-win32.whl
Requirement already satisfied: numpy<1.25.0,>=1.18.5 in c:\python39-32\lib\site-packages (from scipy==1.9.0) (1.21.5)
Installing collected packages: scipy
Successfully installed scipy-1.9.0次に scikit_learn をインストール。
C:\Python39-32>python.exe -m pip install C:\Python39-32\scikit_learn-0.24.2-cp39-cp39-win32.whl
Processing c:\python39-32\scikit_learn-0.24.2-cp39-cp39-win32.whl
Requirement already satisfied: numpy>=1.13.3 in c:\python39-32\lib\site-packages (from scikit-learn==0.24.2) (1.21.5)
Requirement already satisfied: scipy>=0.19.1 in c:\python39-32\lib\site-packages (from scikit-learn==0.24.2) (1.9.0)
Collecting joblib>=0.11 (from scikit-learn==0.24.2)
Downloading joblib-1.4.2-py3-none-any.whl.metadata (5.4 kB)
Collecting threadpoolctl>=2.0.0 (from scikit-learn==0.24.2)
Downloading threadpoolctl-3.6.0-py3-none-any.whl.metadata (13 kB)
Downloading joblib-1.4.2-py3-none-any.whl (301 kB)
Downloading threadpoolctl-3.6.0-py3-none-any.whl (18 kB)
Installing collected packages: threadpoolctl, joblib, scikit-learn
Successfully installed joblib-1.4.2 scikit-learn-0.24.2 threadpoolctl-3.6.0ちょっとたいへんだったけど、これでなんとか、scikit_learn の 32 bit 版が Embeddable Python にインストールできました!!( Python39-32 フォルダのサイズが 335 MB になっちゃったけど、これだけはもうどうにもならない。ちなみに Tesseract-OCR を入れた場合は、その倍くらいになりました!)
(2) 学習モデルを作成して認識テスト
2年前の手書きカタカナ文字認識チャレンジで使った手書きカタカナ文字の画像ファイルは、壊れたノートパソコンから取り外した SSD を専用ケースに入れて作った外付け SSD ドライブに保存してあります。
その SSD ドライブ内を検索し、テストで使えそうな画像ファイルを探すと、ア・イ・ウ・エ・オの各文字がほぼ 700 字ずつ、フォルダに分類されて保存されているのを見つけることができました。
( あった。コレだ ☆ )
記憶では「水増し」して 3000 文字くらいずつ集めたフォルダもあったはずですが、文字数が増えれば増えるほどコピーに時間がかかります。それに、いきなり 3000 文字を機械学習させて結果が失敗だったら、その後、打つ手がなくなってしまう・・・。だから、とりあえず、この 700 字でテストしてみようと考えました。
2年前は手書きカタカナ文字の収集や整理に膨大な時間を要しましたが、今回は「それがない」から、何の苦労もなく仕事はスイスイ進みます。
scikit_learn の学習モデルを作成するスクリプトに合うよう、画像ファイルを入れたフォルダを準備して学習モデルを作成しました。そのスクリプトがコレです。
import cv2
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test_split
import os
import joblib # モデルの保存と読み込みに使用
from sklearn.svm import SVC # SVMにクラスの重みを追加することで、少数派クラスに対して重みを高く設定
# カタカナのクラス(修正: 「ア」を追加)
CATEGORIES = ["ア", "イ", "ウ", "エ", "オ"]
# Pathの中の日本語に対応
def imread(filename, flags=cv2.IMREAD_GRAYSCALE, dtype=np.uint8):
try:
n = np.fromfile(filename, dtype)
img = cv2.imdecode(n, flags)
return img
except Exception as e:
print(e)
return None
# データセットの準備(28x28 の手書きカタカナ画像)
def load_images_from_folder(folder, categories):
images = []
labels = []
for label, category in enumerate(categories):
path = os.path.join(folder, category) # パスの結合方法を修正
print(f"Processing category: {category}, Path: {path}") # デバッグ用に出力
# ディレクトリが存在するか確認
if not os.path.exists(path):
print(f"Warning: Path does not exist: {path}")
continue
for file in os.listdir(path):
# ファイルが画像であるかどうかを拡張子でチェック
if file.lower().endswith(('.png', '.jpg', '.jpeg')):
file_path = os.path.join(path, file)
# print(f"Trying to load file: {file_path}") # 読み込みファイルのパスを表示
try:
# カタカナを含むパスが問題ないかを確認
# img = cv2.imread(file_path, cv2.IMREAD_GRAYSCALE)
img = imread(file_path)
if img is not None:
img = cv2.resize(img, (28, 28))
images.append(img.flatten()) # 1次元化
labels.append(label)
else:
print(f"Failed to load image: {file_path}")
except Exception as e:
print(f"Error loading {file_path}: {e}")
else:
print(f"Skipping non-image file: {file}")
print(f"Loaded {len(images)} images")
return np.array(images), np.array(labels)
# データ読み込み
X, y = load_images_from_folder(r"C:\Python39-32\Images_tegaki\img_28", CATEGORIES)
X = X / 255.0 # 正規化
# データがロードされていない場合にエラーを出す
if len(X) == 0:
raise ValueError("No images loaded. Please check the image files and paths.")
# 学習とテストの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# SVM モデルの作成と学習
model = svm.SVC(kernel='linear')
model.fit(X_train, y_train)
# SVM モデルの作成と学習(クラスの重みを設定する)
# class_weights = {0: 1, 1: 2, 2: 2, 3: 1, 4: 1} # イとウの重みを増やす
# model = SVC(kernel='linear', class_weight=class_weights)
# model.fit(X_train, y_train)
# モデルを保存する
joblib.dump(model, 'katakana_svm_model.pkl')
print("Model saved as 'katakana_svm_model.pkl'")
# 予測関数
def preprocess_image(image_path):
img = imread(image_path)
h, w = img.shape
# 正方形になるように余白を追加
size = max(h, w)
square_img = np.full((size, size), 255, dtype=np.uint8) # 背景を白に
x_offset = (size - w) // 2
y_offset = (size - h) // 2
square_img[y_offset:y_offset + h, x_offset:x_offset + w] = img
# 28x28 にリサイズ
img_resized = cv2.resize(square_img, (28, 28))
return img_resized.flatten() / 255.0
def predict_character(image_path):
img = preprocess_image(image_path)
model = joblib.load('katakana_svm_model.pkl') # 学習したモデルをロード
label = model.predict([img])[0]
return CATEGORIES[label]
# テスト画像の認識ア
image_path = "katakana_sample_A.jpg"
result = predict_character(image_path)
print(f"認識結果: {result}")
# テスト画像の認識イ
image_path = "katakana_sample_I.jpg"
result = predict_character(image_path)
print(f"認識結果: {result}")
# テスト画像の認識ウ
image_path = "katakana_sample_U.jpg"
result = predict_character(image_path)
print(f"認識結果: {result}")
# テスト画像の認識エ
image_path = "katakana_sample_E.jpg"
result = predict_character(image_path)
print(f"認識結果: {result}")
# テスト画像の認識オ
image_path = "katakana_sample_O.jpg"
result = predict_character(image_path)
print(f"認識結果: {result}")このスクリプトで学習モデルを作成し、最後に別に用意したテスト画像を認識させてみました。

「エ・ウ」は、僕が書いた手書きカタカナ文字。
結果は、とても不思議なことに「ア・エ・オ」は正しく読み取りましたが、「イ・ウ」を間違えてしまって、なんだか Python に混乱が生じているような感じ。
そこで行ったことが学習する際の重み付けの変更。その跡が上のスクリプトの赤字となっています。
で、重み付けを変更して(イ・ウの重みを増加させて)新たに学習モデルを作成し、テストしてみましたが結果は第1回目と同様。「ア・エ・オ」は正しく読み取りますが、「イ・ウ」を間違えてしまいます。
何気なく「アイウエオ」の各文字を保存したフォルダを開けて見て、ようやく原因が判明。なんと「ウ」のフォルダ内に「ウ」はなく、「イ」が溢れかえって・・・
つまり、コピーする際、僕が間違えて・・・
うぎゃ!Zoräth ✷ fel∅, ∞’ka selenïv! ⧖ Trål’xon que!
(T▽T;) やっちまったぁ!!
手書きカタカナ文字を正しく分類し直して、再度、機械学習を実行し、学習モデルを作成。
今度は・・・
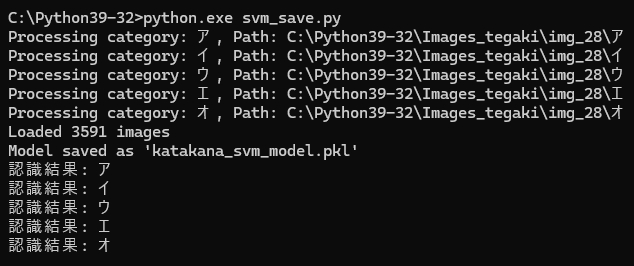
4.とんでもない認識結果に驚愕する
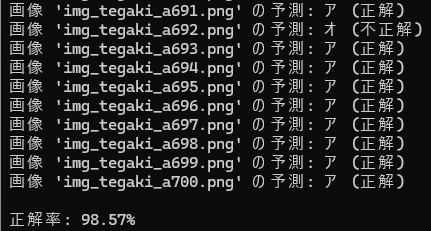
次に、学習用に使った「アイウエオ」各 700 文字で読み取りテストをやってみました。できれば、学習用に使ってない文字がよかったんだけど、残念ながらそれはないので、学習用素材でテストを強行。
各文字の認識率は、次の通り。
まず、「ア」
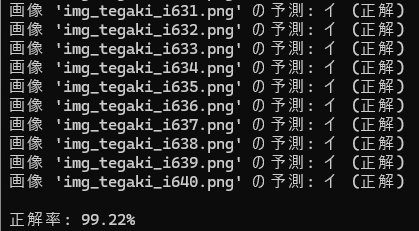
次、「イ」
次、「ウ」
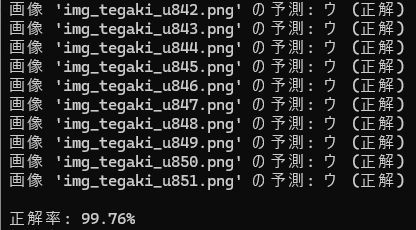
次、「エ」
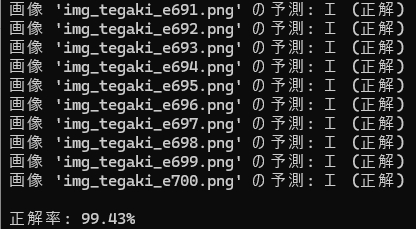
次、「オ」
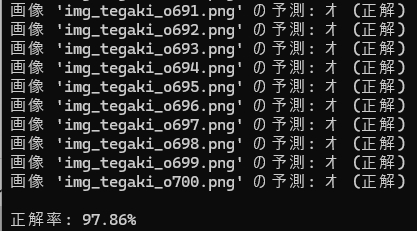
事前に学習に使ってるから、ある意味「不正行為」と言えなくもないんだけど・・・
これなら手書き文字認識に
十分、使えるのでは
ないでしょうか?
さぁ AC_Reader の改造だ!
5.まとめ
・scikit-learn で作成した学習モデルは、宝物になりそうだ☆☆☆
6.お願いとお断り
このサイトの内容を利用される場合は、自己責任でお願いします。記載した内容(プログラムを含む)を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。