画像の中の文字列から最初の一文字を取得する
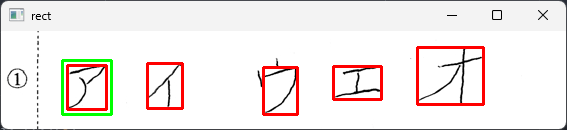
最終的な目標は、カタカナ1文字で解答が書かれた解答欄の『自動採点』。
これを実現するには、まず、解答欄画像からカタカナを探して、それを切り抜き、それが何という文字なのかを判定しなければならない。これは、そのチャレンジの第一歩。
記事(内容)は最初Pythonですが、最終的にPythonのスクリプトは、Object Pascal に埋め込んで内部的に呼び出して利用するので、やがてDelphiに変わります・・・
1.手書き文字は認識できない?
2.文字の位置座標を取得するには?(その①)
3.文字の位置座標を取得するには?(その②)
4.まとめ
5.お願いとお断り
1.手書き文字は認識できない?
本当は、手書きの日本語でも、英語でも、数字でも、とにかく解答欄に書いてある内容を自由自在に読み取ってデータ化し、採点等、様々な目的に利用したいのだが、残念ながらそれはできない。
「それは無理・できるわけない」と思っていることこそ、本当にチャレンジし甲斐のある課題だと、いつも思うし、実際、過去5年間にやってきたことはいつも「できない」を「できる」に変えることへの挑戦だった。
上司に言われて作ったICカードを利用した出退勤の記録を管理するプログラムや、ほとんど自分のために作ったマークシートリーダー、それから、喜んでくれる人が多そうだから書いた(自分では絶対に使わないけど)手書き答案の採点プログラム・・・。「できない」を「できる」に変えて行く、その過程がたまらなくおもしろいことを、僕は知ってる。
しかし、記述式の解答欄を自由自在に読み取って自動採点することは、現時点では絶対に不可能だし、チャレンジしてもハードルが高すぎて、間違いなく途中で挫折する。それはやるまでもなく実現不可能な夢だと自分でもわかる。でも、カタカナ1文字を読み取って、その正誤を判定することならできるんじゃないか? そう思う僕がいる。
確か・・・4年前に、マウスでドラッグして画面に描いた(手書き)数字が0~9のいずれかを判定するプログラムを作成したことがあった。あれから4年経ってるから、認識技術も格段に進歩しているじゃないかって、期待する気持ちもある。
OCRを使った文字認識について、ここ数日間かけて調べたり、実際にプログラムを写経して動かしてみてわかったことは・・・『手書き文字の認識は難しい』ってこと。
『Python 文字認識』のようなキーワードで検索すると、PyOCRとTesseractを使った例が読み切れないほどヒットする。解答欄に見立てた画像を用意して、実際に試してみた・・・。
# PyOCRとTesseractを使用して手書き文字画像を認識
import os
import sys
from PIL import Image
import pyocr
tesseract_path = "C:\Program Files\Tesseract-OCR"
if tesseract_path not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += os.pathsep + tesseract_path
tools = pyocr.get_available_tools()
if len(tools) == 0:
sys.exit(1)
else:
tool = tools[0]
img = Image.open("Image/画像ファイル名.jpg")
# デフォルト設定
builder = pyocr.builders.TextBuilder(tesseract_layout=3)
result = tool.image_to_string(img,lang="jpn",builder=builder)
print(result)

# 結果
ss アイ ウェ オ
[Finished in 1.953s]①は ss に、デフォルト設定の tesseract_layout=3 で、エ は ェ として認識された。他のパラメータ設定ではどうだろうか? 次々と変更して試すことにする。結果は、次の通り・・・
# テキストの単一ブロックと仮定して認識
builder = pyocr.builders.TextBuilder(tesseract_layout=6)# 結果
ss アイ ウェ オ
[Finished in 1.959s]変化なし!
# 画像を1行の文字列として認識
builder = pyocr.builders.TextBuilder(tesseract_layout=7)# 結果
ss アイ ウェ オ
[Finished in 0.423s]これも変化なし!
# 文字が散らばっているテキストとして認識
builder = pyocr.builders.TextBuilder(tesseract_layout=11)# 結果
oe アイ ウェ イオ
[Finished in 0.419s]上記のテストが最も上手く認識できた例で、他にも複数の手書き文字を試したが、この例ほど正しく認識することは出来なかった。いちばん上手く認識できた例でも、完全ではないことから、誰もが容易に、かつ無償で利用できる環境での手書き文字認識には、まだ難しい部分があるようだ。
追記 正しく認識できなかった例
例えば、次の画像。比較的よく認識できた上の例と、それほど違いはないと思うのだが・・・

# デフォルト設定
builder = pyocr.builders.TextBuilder(tesseract_layout=3)# 結果
Y ィ ウエ オォ
[Finished in 2.258s]デフォルト設定の3では、ア が Y となってしまった。イ も小さな ィ になっている。それから、オはなぜ、オとォになるのだろう?
# テキストの単一ブロックと仮定して認識
builder = pyocr.builders.TextBuilder(tesseract_layout=6)# 結果
oe マイ ウエ オ
[Finished in 0.435s]6だと、①は oe に、ア は マ と認識された。残りは正解。
# 画像を1行の文字列として認識
builder = pyocr.builders.TextBuilder(tesseract_layout=7)# 結果
o アマ アイウエオ
[Finished in 1.966s]7では、① が o 、その後ろの アマ はどこからやってきたんだろう?
# 文字が散らばっているテキストとして認識
builder = pyocr.builders.TextBuilder(tesseract_layout=11)# 結果
Y ィ ウエ オォ
[Finished in 0.44s]11では、デフォルト設定と同じ結果になった。
ただ、PyOCRとTesseractの名誉のために、これは重要なことだと思うので掲載。認識する対象画像が手書き文字でなければ、必要かつ十分な素晴らしい性能を発揮する。
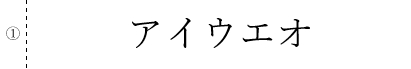
# テキストの単一ブロックと仮定して認識
builder = pyocr.builders.TextBuilder(tesseract_layout=6)# 結果
1 アイ ウエ オ
[Finished in 2.254s]①は「(半角の)1」として読み取り、あとは正解。「文字」でなく、「画像」から文字の部分を判別し、しかも、その個々の文字を見分けているのですから、素直にすごいです!
# 文字が散らばっているテキストとして認識
builder = pyocr.builders.TextBuilder(tesseract_layout=11)# 結果
アイ ウエ オ
[Finished in 2.419s]①は認識せず。あとは正解。では、Fontを変更すると・・・?
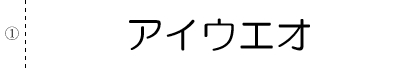
# テキストの単一ブロックと仮定して認識
builder = pyocr.builders.TextBuilder(tesseract_layout=6)# 結果
"アイウエオ
[Finished in 0.36s]①が ” に変わった? でも、あとは正解。
# 文字が散らばっているテキストとして認識
builder = pyocr.builders.TextBuilder(tesseract_layout=11)# 結果
アイ ウエ オ
[Finished in 2.376s]①は認識されない。あとは正解。さらに、別のFontでは・・・?
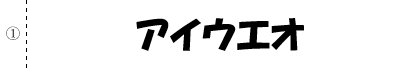
# テキストの単一ブロックと仮定して認識
builder = pyocr.builders.TextBuilder(tesseract_layout=6)# 結果
アイ ウエ オ
[Finished in 0.779s]# 文字が散らばっているテキストとして認識
builder = pyocr.builders.TextBuilder(tesseract_layout=11)# 結果
アイ ウツ ウエ オ
[Finished in 1.944s]なんだか、むせてるような雰囲気を感じますが。元気? だいじょうぶ?
これから作成する自動採点プログラムで使用する解答欄画像には、設問番号や解答方法の指示が必ず含まれる予定なので、OCRを利用した手書き文字認識をそのまま読み取りに使用するのは少し難しそうだ。どうにかして、①などの設問番号への反応を読み取り結果から除外する方策を考えなければならない。
あと、認識結果のところどころにスペースが入るのは仕様なのか?(この点、不勉強で、よくわかりません)、まぁ、スペースは置換して取り除けばそれでOKだから気にしなくてもいいけど。
いずれにしても「手書きでない文字画像の認識」であれば、現在のOCR(光学的文字認識)は十分、実用になるレベルに達しているのは間違いない。これを無償で提供してもらえることに対し、プログラムの作成者と提供の仕事に関わった人々へ心から感謝。
2.文字の位置座標を取得するには?(その①)
次に考えたことは、手書き文字そのものを完全に認識(読み取って判別すること)は難しくても、「文字の位置」であれば座標というかたちで取得できるのではないか? ということ。僕の場合、そこに文字列があったとしても、最初の一文字だけ座標が取得できればOKなので、そこを重要視してテストを実行。
調べてみると、pyocrはbuilderというオプション部分の設定を変更することで、様々な読み取り形式を指定できるようだ。
※ pyocr のライセンスは GPL v3 なので、個人がローカルな環境で「使用」するだけであればソースコードの公開義務等は発生しないが、複製や改変、頒布は「利用」にあたり、ソースコードの公開義務等が発生することに十分留意する必要がある。
【builderに指定可能なオプション】(省略した場合はTextBuilderになる)
1.TextBuilder 文字列を認識
2.WordBoxBuilder 単語単位で文字認識
3.LineBoxBuilder 行単位で文字認識
4.DigitBuilder 数字 / 記号を認識
5.DigitLineBoxBuilder 数字 / 記号を認識
注意:DigitBuilderおよびDigitLineBoxBuilderは認識対象を数字に限定してTesseractを動作させる。ただし、新しい認識エンジン(Tesseract4.0系)では動作しない。このオプションで、座標を取得するために利用できそうなのは、「2」と「3」だ。WordBoxBuilderが認識するのが「文字」ではなく、「単語」という部分がちょっと気になったが、「アイウエオ」は単語ではなく、「単なる文字列」だと思うので、どうなるか、ちょっと実験してみた。ア と イ と ウ と エ と オ を全部、別々の単語として認識してくれるとうれしいのだけれど。字と字の距離も離れているし・・・

import sys
import os
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import numpy as np
import pyocr
img = Image.open(r".\img\画像ファイル名.jpg")
#tool = pyocr.get_available_tools()[0]
tesseract_path = "C:\Program Files\Tesseract-OCR"
if tesseract_path not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += os.pathsep + tesseract_path
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("OCRエンジンが指定されていません")
sys.exit(1)
else:
tool = tools[0]
builder = pyocr.builders.WordBoxBuilder(tesseract_layout=6)
boxies = tool.image_to_string(img, lang="jpn", builder=builder)
draw = ImageDraw.Draw(img)
for box in boxies:
text = box.content
pos = box.position
draw.rectangle(pos, fill=None, outline=(255, 0, 0))
print(pos)
img.save(r".\img\out.jpg")
結果は・・・

# 出力された座標
((6, 0), (82, 98))
((67, 32), (181, 77))
((271, 27), (379, 82))
((417, 17), (481, 72))
[Finished in 3.125s]WordBoxBuilderで最初の一文字の座標を取得するという目的の実現は困難なようだ。「使い方の方向性が間違ってる」と、作成者の方には叱られそう・・・。その通りです。すみません。
では、LineBoxBuilder の方はどうだろうか?
# builderオプションの設定を変更
# builder = pyocr.builders.WordBoxBuilder(tesseract_layout=6)
builder = pyocr.builders.LineBoxBuilder(tesseract_layout=6)
左x座標の起点が①の左にあるのは理解できるが、左y座標はどのようにして決めているのだろう? 左y座標は、点線の上限のようにも見えるが・・・。右x座標はオの右端だと思うが、右y座標はなぜ画像の外に・・・? もしかして、画像中の点線と何か、関係がある?
残念ながら、LineBoxBuilder も手書き文字一文字めの座標を取得する用途には向かないようだ。誤解のないように言っておくが、これは各Builderオプションが「使えない」という意味ではない。Builderは正しく機能している。僕の使い方=「手書き文字への適応」が「間違っている」ということに他ならない。
Builderオプションの名誉のため、手書きでない画像の①と点線を消して、WordBoxBuilder をもう一度実行して見ると・・・

使用目的によっては、日本語の単語をどの程度認識するか? その認識率が問題になりそうだが、文字や文字列の座標は間違いなく取得できる。すばらしい性能だ。
LineBoxBuilder では・・・

こちらはさらにすばらしい。手書きでない画像であれば、行単位での文字列の認識・切り出し用途に十分使えそうだ。要は、万能選手的な働き方はその性格上できないので、適材適所な使い方をすれば、大変優秀な働きを示してくれるということを、使う側が十分認識して、Toolがその性能を100%発揮できる場面を提供してあげることが大切なのだ。
3.文字の位置座標を取得するには?(その②)
では、手書き文字の最初の一文字目の座標を取得するにはどうしたらいいのか?
いちばんのヒントを与えてくれたのは、次のWebサイト様で紹介されていた画像内の数字を連続して認識するスクリプト。
https://ailog.site/2019/08/17/ocr1/
上記Webサイト様で紹介されているScriptをそのまま実行しようとすると、次のようなエラーメッセージが表示されることがあるようだ。これは、OpenCVの仕様変更のため?
# 表示されたエラーメッセージ
Traceback (most recent call last):
File "X:\XXX\Sample.py", line XX, in <module>
x, y, w, h = cv2.boundingRect(cnt)
cv2.error: OpenCV(4.5.5) X:\a\opencv-python\opencv-python\opencv\modules\imgproc\src\shapedescr.cpp:874: error: (-215:Assertion failed) npoints >= 0 && (depth == CV_32F || depth == CV_32S) in function 'cv::pointSetBoundingRect'
[Finished in 2.412s]エラーの修正方法は、次の通り(赤字部分の[1] を [0] に修正)。また、状況によっては、いちばん外側の輪郭だけを検出するように、RETR_LIST を RETR_EXTERNAL に修正しておいた方がよいとのこと。
#contours = cv2.findContours(
# thresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[1]
# エラーが出なくなるように修正
#contours = cv2.findContours(
# thresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
# 領域の一番外側だけを検出するように修正
contours = cv2.findContours(
thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]紹介記事にあったスクリプトを元にして、解答欄の画像にある文字列から最初の一文字目の文字を取得するスクリプトを書いた。処理の流れとスクリプトは次の通り。
- 検出した輪郭矩形の数だけ、その位置座標を二次元配列に取得(高さが小さすぎる輪郭は座標をゼロにしてないものとする)。
- 横書き答案の場合はx座標の小さなものから昇順に、縦書き答案の場合はy座標の小さなものから昇順に並べ替えを行う処理を追加し、文字列の最初の一文字目の座標を取得。
- さらにこれを囲む輪郭矩形の大きさを少し大きく補正して、一文字目の文字だけを切り出して保存する。
# 画像の中の文字を検出して、最初の一文字の画像を保存するScript
import sys
import numpy as np
import cv2
from PIL import Image
# 画像の読み込み(Pathとファイル名に日本語があるとエラーになる)
#im = cv2.imread(r".\img\numbers.png")
# 画像の読み込み(pillowで日本語に対応)
file_path = r".\img\Sample.jpg"
pil_img = Image.open(file_path)
# PillowからNumPyへ変換
img = np.array(pil_img)
# グレイスケールに変換
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# ぼかし処理(シミ抜き)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
# 二値化
thresh = cv2.adaptiveThreshold(blur, 255, 1, 1, 11, 2)
# 輪郭を抽出
contours = cv2.findContours(
thresh, cv2.cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
# 検出した輪郭の数
num = len(contours)
# 表示して確認
print(len(contours))
# 二次元配列を作成して初期化
mylist = np.zeros((num, 4))
# 配列の要素番号を指定する変数(初期化)
i = 0
# 描画色は赤を指定
red = (0, 0, 255)
# 抽出した領域を繰り返し処理する
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
if h < 30: # 高さが小さい場合は検出しない
# (ここを調整すれば設問番号や指示内容を無視できる)
mylist[i][0] = 0
mylist[i][1] = 0
mylist[i][2] = 0
mylist[i][3] = 0
else:
mylist[i][0] = x
mylist[i][1] = y
mylist[i][2] = x + w
mylist[i][3] = y + h
cv2.rectangle(img, (x, y), (x+w, y+h), red, 2)
# 最後の出力がいちばん手前の矩形の座標というのは勝手な思い込み
# 最初の一文字目の座標を確認するために取得した座標を表示
print(str(x)+", "+str(y)+", "+str(x+w)+", "+str(y+h))
i += 1
# 配列を並べ替え(キー列は0:x1、1:y1・昇順)
pw, ph = pil_img.size
if pw > ph:
# 横書きと判断
mylist_sort = mylist[np.argsort(mylist[:, 0])]
else:
# 縦書きと判断
mylist_sort = mylist[np.argsort(mylist[:, 1])]
# 表示して確認
print(mylist_sort)
# 緑色を指定
green = (0,255,0)
# 輪郭枠の大きさを微調整するための変数
intTweak = 5
# 最も左の文字を緑の枠で囲んで示す
for i in range(num):
if mylist_sort[i][0] != 0:
x1=int(mylist_sort[i][0]-intTweak)
y1=int(mylist_sort[i][1]-intTweak)
x2=int(mylist_sort[i][2]+intTweak)
y2=int(mylist_sort[i][3]+intTweak)
print(str(x1)+", "+str(y1)+", "+str(x2)+", "+str(y2))
cv2.rectangle(img, (x1,y1), (x2, y2), green, 2)
break
# 輪郭枠付きの画像を保存
cv2.imwrite(r".\img\result.png", img)
# 最初の一文字を切り抜き
img_crop = pil_img.crop((x1,y1,x2,y2))
# 最初の一文字を保存
img_crop.save(r".\img\crop.jpg")
# 表示
cv2.imshow('rect', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
【実行結果】
【検出した輪郭の数】
23
【最初の一文字目の座標を確認するために取得した座標を表示】
262, 36, 296, 83
332, 35, 380, 68
66, 34, 105, 78 <- これがほしかった座標!
146, 32, 181, 77
416, 16, 482, 73
【並べ替えを実行した後の二次元配列の内容】
[[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 66. 34. 105. 78.]
[146. 32. 181. 77.]
[262. 36. 296. 83.]
[332. 35. 380. 68.]
[416. 16. 482. 73.]]
【少し輪郭矩形を大きくした切り抜き用の座標】
61, 29, 110, 83
[Finished in 11.51s]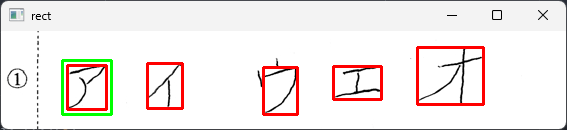

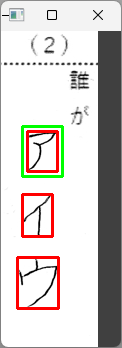
追記 読み取りに失敗(?)した例
文字の一部が「切れている・つながっていない」場合、読み取りに失敗(?)してしまうことがあるようだ(ヒトは、その期待に反している結果を「失敗」と感じてしまうが、キカイ的には間違いなく正確に輪郭を検出している)。だから、これも僕が運用方法を間違えているだけと言えなくもない。例えば、次の画像で試すと・・・


高さの閾値をゼロにして、プログラムが正しく動作していることを確認する。

この読み取り方法での(自分的に工夫はしたが)限界がこの辺りにあることがわかったので、運用する際はこれを「読み取りエラー」として処理し、ヒトが目視で確認するように案内することに決め、これ以上、この問題には深入りしないことにする。確かに「自動採点が目標」なんだけど、最終的にはヒトの確認作業が必ず必要。機械と協働するのだからお互いが気持ちよく働ければいいのだ・・・と、自分自身に言い聞かせて、先へ進む。
(追記ここまで_20221231)
スクリプトを書いていて、すごくうれしくなったのは、解答欄に欠かせない設問番号や指示内容を小さめに作成(印刷)すれば、高さの閾値を用いて、その存在を無視できること。これを発見した時は、もう小躍りしたいほど、うれしかった!
1回の計算に必要な時間が長いような気もするが、Loopを作って複数の解答欄画像を連続して処理して見ると2回目からは初期化が必要なくなるためか、計算時間はグンと短くなった。
次の課題は、切り出して保存したカタカナ画像の文字が何であるかを判定するスクリプトを完成させること。4年ぶりにチャレンジする機械学習だが、この4年間でどれくらい進化したのだろう? 4年前はMNISTデータベースを活用して手書き数字を認識・判定する方法を学んだが、今回のターゲットは言語的にはマイナーすぎるカタカナ・・・
もし、この夢が実現できてもプログラムを商品化するつもりなどまったくないので、研究用に無料で利用できるカタカナデータベースがどこかにあるとよいのだが。
4.まとめ
(1)画像内の手書き文字をOCRで完全に認識させるのは、現段階では難しい。
(2)OpenCVの輪郭検出を用いれば画像内の文字位置の座標を取得可能。
(3)座標から文字の輪郭矩形を切り出して保存。機械学習で文字種を判定する。
5.お願いとお断り
このサイトの内容を利用される場合は、自己責任でお願いします。記載した内容を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。