今回ご紹介するプログラムで、自動採点できるかもしれない(?)手書き答案の解答は・・・
カタカナ「ア・イ・ウ・エ・オ」のいずれか1文字、それから
数字の「1・2・3・4・5」のいずれか1つ、そして
記号の「〇 ・ × 」のどちらかです。
この・・・ わずか 12 個の、文字・数字・記号に限定したお話ですが、僕が行ったテストでは各種パラメータの微調整を行うことなく、デフォルト設定のまま、テストデータ(少ないですが)をほぼ正しく推論できました。※ 制作の最終段階での検証結果です。
「自己責任・サポート無し」という条件付きですが、もし、よかったら、お試しください。
どなたにもお待ちいただいておりませんが、2年ぶりにバージョンアップした解答欄リーダーです。
【もくじ】
0.注意事項
1.論より証拠
2.自動採点機能の使い方
3.推論用画像データの確認
4.プログラムのダウンロード
5.お願いとお断り
追記(20260401)
ここで紹介している自動採点機能は搭載しておりませんが、より進化した手書き答案採点機能も搭載したマークシートリーダーを制作しました。自己責任のもと、完全無料でお使いいただけますが、動作保証・サポート等は一切ありません。それでもよろしければお試しください。
【注意事項】
初回の自動採点実行時にPCがフリーズしたような状態になることがあります(正しく動作している状態であっても、Python Engine の初期化には数秒を要します)。特に、ダウンロードした Zip ファイルを展開(解凍)した直後の初めての実行時や、インターネット接続が切れた状態で使用した場合、この初期化作業にかなりの時間を要する場合があることを実際に確認しました(常に、この現象が起きるわけではありません)。この現象発生時に、内部的に呼び出して実行している組み込み Python 環境はエラーメッセージを出しません。つまり、プログラムは単に PythonEngine の初期化等、何らかの作業の完了を待つ「待機状態」であることは明らかなのです・・・ が、「プログラムで使用しているどのライブラリがこの待機状態を作り出しているのか」という、はっきりした原因の特定まで現在至っておりません。
この現象は、自動採点実行時、最初の1回に限って発生します。2回目以降は、採点終了まで滞りなく(素人が作ったプログラムなので実行速度は遅いですが)動作すると思います。
お試しいただける方には、たいへん申し訳ありませんが、そのような現象が発生することをご理解いただいた上で、ご試用いただけますよう、伏してお願い申し上げます。
【追記_20250823】
上記の現象について調査した結果、これは「 Windows Defender や McAfee などの Anti-Virus Software または Antivirus Software : AV による『未知バイナリの初回スキャン』により発生している可能性が極めて高い」ことがわかりました。
このプログラムでは、内部的に(バックグラウンドで)PythonForDelphi(P4D)を通じて Python 環境を利用し、自動採点処理を実行しています。ですので、自動採点実行時には、cv2.pyd や numpy 及び scikit-image の HOG や LBP に関連する pyd ( Python Dynamic Module の略= Python の拡張モジュール)が必ず読み込まれます(これらの pyd ファイルは、内部的には ネイティブ DLL と同等に扱われるようです)。
AV は「初めて見る未知の DLL」をロードしようとした時に、ファイル全体をディスクから読み込み、サンドボックス(外部と隔離された仮想環境:ITやセキュリティの分野では、主に怪しいプログラムを安全に試すための実験室として使われる)や、クラウドサービスに投げて解析(インターネット接続が出来ない環境である場合には、一定時間のタイムアウトを設け、その後ローカル判定にフォールバックする:なのでインターネット接続環境がないPCで実行してもいつまでもフリーズしたような状態が続くわけではない → 待機時間は Windows Defender の場合、既定で数秒~数十秒程度)し、ハッシュをキャッシュに登録という処理を行うため、この「初回スキャン」が終わるまで、DLL ロードは OS レベルでブロックされてしまい、アプリケーション側から見ると フリーズ、すなわち「固まった」ようにしか見えない状態になるわけです。一度、このスキャンを通過すれば「このファイルは安全」とキャッシュされるので、以後は高速にロードできるようになります。
自動採点の初回実行時のみ PC がフリーズしたようになり、2回目以降は何の問題もなかったかのように動作するのは、このスキャンが実行されている証拠だと思われます(このスキャンが実行されていることを直接確認する方法はないようです: AV が検査状態を外部に直接公開すると、逆にマルウェアに悪用される可能性が高まるため)。
さらに「実行形式ファイルを別の場所にコピーすると再びフリーズする」のは、 AV によっては ファイルパスや場所ごとにキャッシュが分かれるためです(同じファイルでもデスクトップに置いたら「未知扱い」になる)。
この問題への対策として、セキュリティソフトを無効化するのは論外ですし、また、それが真の原因とわかったわけではなく、現段階ではその可能性が極めて高いと思われるということなので、次の実験を試行して、結果を後日、こちらに記載させていただきます。
(1)「ウォームアップ import」をアプリ起動時にバックグラウンドで実行。
(2)バックグラウンドスレッドで AV スキャンを監視し、UI に進捗状況を表示。
(追記_20250823 ここまで)
【追記_20250825】
ここで紹介している AC_Reader をはじめ、この Blog の過去記事に掲載したアプリケーションはすべてディスプレイ解像度が 1366 × 768 の環境で実行することを前提として開発しています。高解像度ディスプレイで実行される場合、次のリンク先の記事にあります「高 DPI 設定の変更」を行ってから実行していただけますようお願い申し上げます。
(追記_20250825 ここまで)
【追記_20250826】
ユーザー体験を少しでも向上させるべく、以下の順番で AV のスキャンによる待機状態の改善を目標にプログラムの見直しを図りました。
(1)「ウォームアップ import」をアプリ起動時にバックグラウンドで実行。
(2)バックグラウンドスレッドで AV スキャンを監視し、UI に進捗状況を表示。
(1)については、まず、バックグラウンドで実行はやめることにしました。理由は、バックグラウンドで実行してしまうと、AV のスキャンが完了しないうちにメインスレッド側で Python モジュールが使われてしまう可能性があることに気づいたためです。そこで、スキャン対象となる .pyd ファイルをアプリケーション起動時に全て読み込み、スプラッシュフォームの表示中にAnti-Virus Software による『未知バイナリの初回スキャン』を強制的に実行、この処理が確実に完了するまで待機して、安心安全な状態でアプリケーションを実行し、かつ自動採点機能等 Python のモジュールを使用中に発生する待機状態が極力短くなるよう、プログラムを修正しました。コードは以下の通りです。
procedure TFormCollaboration.LoadAllPythonModules;
var
PyCode: TStringList;
begin
PyCode := TStringList.Create;
try
//スキャン対象となるモジュール
PyCode.Add('import cv2');
PyCode.Add('import numpy');
PyCode.Add('from skimage.feature import hog, local_binary_pattern');
//その他 Python モジュール
//スキャン対象ではないモジュールも読み込んでおく
//初期化の待機時間短縮やエラー回避のため preload
PyCode.Add('import os');
PyCode.Add('import glob');
PyCode.Add('import re');
PyCode.Add('import joblib');
// 実行
PythonEngine1.ExecStrings(PyCode);
finally
PyCode.Free;
end;
end;procedure TFormCollaboration.FormCreate(Sender: TObject);
var
・・・ 省略 ・・・
begin
//embPythonの存在の有無を調査(条件コンパイル)
{$IFDEF WIN32}
//32bit環境での処理
AppDataDir:=ExtractFilePath(Application.ExeName)+'Python39-32';
{$ELSE}
//64bit環境での処理
AppDataDir:=ExtractFilePath(Application.ExeName)+'Python39-64';
{$ENDIF}
if DirectoryExists(AppDataDir) then
begin
//フォルダが存在したときの処理
PythonEngine1.AutoLoad:=True;
PythonEngine1.IO:=PythonGUIInputOutput1;
PythonEngine1.DllPath:=AppDataDir;
PythonEngine1.SetPythonHome(PythonEngine1.DllPath);
PythonEngine1.LoadDll;
//PythonDelphiVar1のOnSeDataイベントを利用する
PythonDelphiVar1.Engine:=PythonEngine1;
PythonDelphiVar1.VarName:=AnsiString('var1');
//初期化
PythonEngine1.Py_Initialize;
end else begin
PythonEngine1.AutoLoad:=False;
end;
//Splashフォームを表示
theSplashForm:=TSplashForm.Create(Application);
try
theSplashForm.Show;
theSplashForm.Refresh;
theSplashForm.TimeLabel.Caption :=
'ライブラリをロード中...(スキャンにより数分かかる場合があります)';
theSplashForm.Update;
Sleep(1500);
LoadAllPythonModules; //Pythonのモジュールを読み込み
theSplashForm.TimeLabel.Caption := '準備が整いました!';
theSplashForm.Update;
Sleep(500);
FadeOutForm(theSplashForm);
theSplashForm.Close;
finally
theSplashForm.Free;
end;
・・・ 省略 ・・・
end;上記コードを実行した結果、初回起動時、私の環境では約2分5秒間 PC が待機状態になりました。また、自動採点機能の初回使用時は、私の環境では 15 秒間待機状態が続きました。2回目のアプリケーション起動時、自動採点実行時は、いずれも待機時間は大幅に短縮され、ほとんど気にならないレベル(個人差はあると思いますが)になりました。
(2)について
(1)ではユーザーへの案内が「’ライブラリをロード中…(スキャンにより数分かかる場合があります)’」のみとなってしまい、処理の経過状況がうまく伝わらない可能性があると考え、当初、別スレッドで AV スキャンを監視し、UI (theSplashForm.TimeLabel.Caption)に進捗状況を表示できないかと考えました。そこで、.pyd ファイル(=Python モジュール)のロードと同時に監視を自動で開始し、スキャンが収束するまで待機するユーティリティ関数を作成してみたのですが、PC の環境によりインストールされている AV は異なっていて当然ですので、この AV プロセスをどうすれば確実に取得できるかという部分が、まず大きな問題となりました。
const
AVList: array[0..4] of TAVInfo = (
(Name: 'MsMpEng'; Path: 'C:\Program Files\・・・\MsMpEng.exe'),
(Name: 'McShield'; Path: 'C:\Program Files\・・・\McShield.exe'),
(Name: 'savservice'; Path: 'C:\Program Files\・・・\XXX.exe'),
(Name: 'ccSvcHst'; Path: 'C:\Program Files (x86)\・・・\YYY.exe'),
(Name: 'avp'; Path: 'C:\Program Files\・・・\ZZZ.exe')
);PC 環境が異なっても上記 Path を確実に取得できるよう、次のようにしたり・・・
type
TAVInfo = record
Name: string;
Path: string;
end;
function DetectAVProcesses: TArray<TAVInfo>;
implementation
const
AVCandidates: array[0..4] of TAVInfo = (
(Name: 'MsMpEng'; Path: '') //動的に取得する
);
function GetProcessPath(const ProcName: string): string;
var
Snapshot: THandle;
ProcEntry: TProcessEntry32;
hProcess: THandle;
PathBuffer: array[0..MAX_PATH - 1] of Char;
begin
Result := '';
Snapshot := CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
if Snapshot = INVALID_HANDLE_VALUE then Exit;
ProcEntry.dwSize := SizeOf(TProcessEntry32);
if Process32First(Snapshot, ProcEntry) then
begin
repeat
if SameText(ProcEntry.szExeFile, ProcName + '.exe') then
begin
hProcess := OpenProcess(PROCESS_QUERY_INFORMATION or PROCESS_VM_READ, False, ProcEntry.th32ProcessID);
if hProcess <> 0 then
begin
if GetModuleFileNameEx(hProcess, 0, PathBuffer, Length(PathBuffer)) > 0 then
Result := PathBuffer;
CloseHandle(hProcess);
end;
Break;
end;
until not Process32Next(Snapshot, ProcEntry);
end;
CloseHandle(Snapshot);
end;
function DetectAVProcesses: TArray<TAVInfo>;
var
i: Integer;
L: TList<TAVInfo>;
Path: string;
Info: TAVInfo;
begin
L := TList<TAVInfo>.Create;
try
for i := Low(AVCandidates) to High(AVCandidates) do
begin
Path := GetProcessPath(AVCandidates[i].Name);
if Path <> '' then
begin
Info := AVCandidates[i];
Info.Path := Path;
L.Add(Info);
end;
end;
Result := L.ToArray;
finally
L.Free;
end;
end;さまざまに頑張ってみたのですが・・・、最終的に、どうやっても「’対象AVが見つかりません’」という表示が消えません・・・。つまり、AV プロセスを取得することが私の技術では出来ませんでした (ToT)
var
AVProcesses: TArray<string>;
begin
theSplashForm.TimeLabel.Caption := 'AV監視開始…';
AVProcesses := DetectAVProcesses;
if Length(AVProcesses) = 0 then
begin
theSplashForm.TimeLabel.Caption := '対象AVが見つかりません';
Exit;
end;
AVThread := TAVScanThread.Create(
AVProcesses, 10, 3, 60000,
procedure(const Msg: string)
begin
theSplashForm.TimeLabel.Caption := Msg;
end
);
AVThread.Start;
end;(1)「ウォームアップ import」をアプリ起動時に実行だけで十分な気がしてきました!
なので、ここは潔く・・・
撤退します!
(追記_20250825 ここまで)
【追記_20250924】
ユーザーの方から、「手書き答案の採点補助プログラム( AC_Reader )を使用していると、突然、白紙のメッセージがたくさん出て止まるんだけど・・・」という不具合発生の報告をいただきました。
私が動作確認した際には経験しなかった現象なので、具体的に「ナニを・どうすると・それが起きるのか」が当初まったくわからず、はたして不具合を解消できるかどうか、大いに不安でしたが、年齢層で言うとかなり高めの方からの不具合の報告であったことを念頭に置き、得点の「入力」、採点結果の「書込」、採点対象答案の「移動」あたりのボタンクリックに関する問題なのではないかと推測して、不具合の再現を図ったところ、予想が的中し、「書込」ボタンを連打すると PC がフリーズしてプログラムが落ちることを確認しました。
Delphi の VCL の Button コントロールには、最初からダブルクリックを受け付ける機能そのものがありません( = OnDblClick イベントが存在しない)。これは考えてみれば当然のことで、ダブルクリックイベントを許可すれば、意図しない二重実行が発生しまくるからです。
ただ、人間ですから、何かの拍子に、つい! ボタンを連打してしまうことはあって当然のことですので、ここはプログラム側できちんと連続クリックを受け取らないよう、対策しておく必要があります。
プログラマなら誰もが最初に考えることは、OnClick イベントの先頭に Button1.Enabled := False; を記述することだと思います。しかし、これでは対応できませんでした。連続クリックするとボタンが操作不可能になる前に、ボタンはクリックを拾ってしまいます。
そこで、FIsSaving: Boolean; のようなグローバル変数を設けて、ボタンクリックイベントの先頭行で、if FIsSaving then Exit; 次の行に FIsSaving := True を記述して連続クリックを阻止しようと考えました。しかし、この方法でも連続クリックの2回目以降を受け取らないようにすることはできませんでした。やはり、ボタンは連続クリックを拾ってしまうのです。
そこで、次のようにして、
Button1.Enabled := False;
Application.ProcessMessages;これなら上手く行くかと思いましたが、これもダメです。例え Button1.Enabled := False を設定しても、すでにクリックメッセージが処理順番待ち行列(キュー)に積まれていると(具体的には早打ちした WM_LBUTTONDOWN / WM_LBUTTONUP が複数積まれていると?)、OnClick イベントが複数回呼ばれてしまい、Application.ProcessMessages はそれらを即座に処理しますから、再入が発生し、データの保存(書込み)処理が複数回、同時実行されてしまうようです。
この同時実行によって、競合や例外が発生し、プログラムが落ちるわけです。
これはたいへんなコトになったと思いました。ボタンが連続クリックを拾ってしまうことを私の知識では止められない以上、別の方向性をとらざるを得ません。ですので途中から方針を変更し、連続クリックされても「クリックそのものは受け取って、同じ処理を繰り返し実行」、しかし、「プログラムは落ちない」方向で問題を解決(・・・というか、問題に対応?)することに決め、保存処理の実行ではプログレスバー以外の UI に一切触らず、エラー発生の原因となる保存手続き中の Application.ProcessMessages; はすべて削除して、手続きの外部へ移し、さらにボタンの OnClick イベントの直接呼出し等の処理は全部止めるよう見直しを図った結果、次のコードにたどり着くことができました。びっくりするくらいシンプルなコードです。書いた本人も驚きでした・・・ DoSaveData; 手続き内に保存の処理は全部詰め込んであります。
相変わらず、連続クリックそのものは、阻止できていませんが・・・ プログラムは落ちなくなりました。
procedure TForm1.Button1Click(Sender: TObject);
begin
Button1.Enabled := False;
try
DoSaveData;
Application.ProcessMessages;
finally
Button1.Enabled := True;
end;
end;で、DoSaveData 手続き側では、グローバル変数を利用し、さらなる安全策をとりましたが、これもやはり全然、はい。まったく!効いていませんが、プログラムはとにかく落ちません。少なくとも、私の環境では連続クリックに対応できるようになりました。
procedure TForm1.DoSaveData;
var
i:integer;
begin
if FIsSaving then Exit; // 多重実行防止
FIsSaving := True;
・・・ 省略 ・・・
end;なお、自動採点機能もどきを搭載した Version 3 の修正作業を行っているうちに、私の周囲では、旧版の Version 2 の方が手に馴染むと、そちらを使い続けてくださっている方が複数いることを思い出し、Version 3 に行ったものと同等の修正(今回の修正に加えて、高 DPI 環境下でのスケーリング問題への対応や、メモリーリークを防止するため、設定画面が表示されている際には「閉じる」ボタンを無効化する処理等)を Version 2 にも同様に施して、Version 3 側を「 AC_Reader_AutoGrading.exe 」、Version 2 側を「 AC_Reader_NoneAutoGrading.exe 」として、上記リンクからダウンロードできる「 デジタル採点 All in One.zip 」に同梱しました。
自動採点機能もどきを搭載した Version 3 は、初回起動時に必ず実行される Windows Defender や McAfee などの Anti-Virus Software : AV による『未知バイナリの初回スキャン』の対象ファイルが多いため、実行環境を別ディレクトリに移動した際等、必ずこの処理が走り、長い待機状態が発生します。自動採点機能が不要の場合は、それがなく、『未知バイナリの初回スキャン』の対象ファイルが少ない「 AC_Reader_NoneAutoGrading.exe 」をお試しいただいた方がいいかもしれません。
AI に確認したところ、『多くのAVは、過去にスキャン済みのファイル情報をキャッシュしており、安全と判断したファイルはスキャン対象から外すようにしているが、そのキャッシュには有効期限があるため、検査後一定時間が経過すると「再評価が必要」と判断され、再スキャンが実行される』とのことです(私の環境下では、たとえディレクトリ構成を変えていない場合でも、前回起動時からひと月ほど経過?していたりするとプログラム起動時に待機状態が長く続く現象を確認しました。なので、間違いなくキャッシュには有効期限があるようです)。この他にも『スケジュールされた定期スキャン』や『アイドル時スキャン( ScanOnlyIfIdle )』の実行時、さらに『ウイルス定義ファイル更新後に再評価対象とされた場合』等にも再スキャンされる可能性があるとのことです。安全のためには仕方のないこととは言え、もう少しスキャン時間が短くなるとありがたいのですが・・・。
(追記_20250924 ここまで)
また、このプログラムの動作には「Microsoft Visual C ++ ランタイムライブラリ」のインストールが必要です。お使いのPCに「Microsoft Visual C ++ ランタイムライブラリ」が入っていない場合は、下記 Web サイトから「VisualCppRedist_AIO_x86_x64.exe」をダウンロードし、ダウンロードしたプログラムを管理者権限で実行し、動作に必要なライブラリをPCにインストールしてください。なお、インストール時には Windows のユーザーアカウント制御(UAC) が起動し、管理者用のID とパスワードの入力を求められます。インストールでは、exe の名称からわかるように 32 ビット版と 64 ビット版それぞれの VC++ランタイムライブラリがお使いの PC にセットアップされます。なお、インストール後は(僕のPC環境では)再起動なしで、そのまますぐに AC_Reader.exe を実行できました。
「VisualCppRedist_AIO_x86_x64.exe」の入手先:
https://www.majorgeeks.com/files/details/visual_c_redistributable_runtimes_aio_repack.html
2025年6月11日現在、バージョンは「0.91.0」でした。上記 Web サイトの Download (64-Bit EXE) というリンクをクリックすればインストールプログラムをダウンロードできます。
1.論より証拠
自動採点実行時の画面のハードコピーを以下に示します。なお、テスト用データの手書き「文字・数字・記号」は、すべて「お手本」を参照しながら、僕自身が「お手本」を真似て書いたものです。
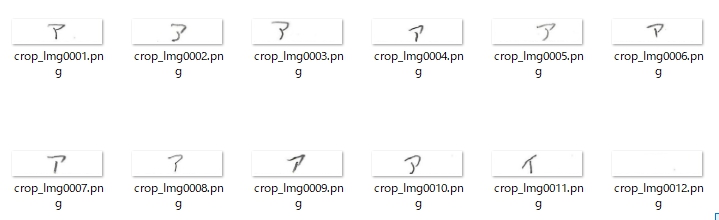
まず、最初にカタカナの「アイウエオ」5文字の推論結果です。
正解ラベル:「ア」の場合です。(全体を表示するため、解答欄画像は縮小表示しています)
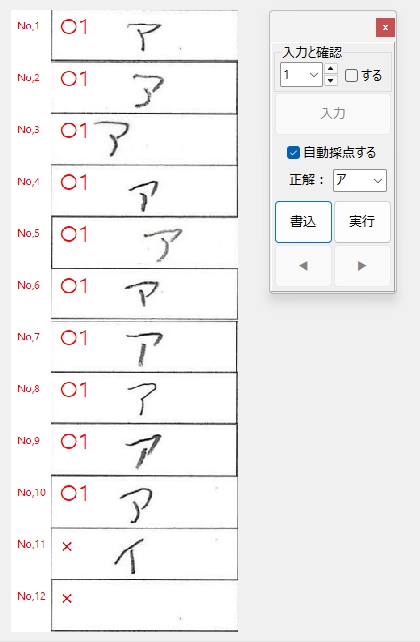
正解ラベル:「イ」の場合です。
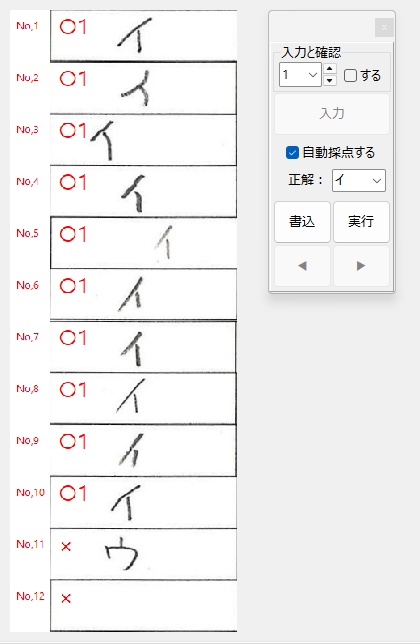
正解ラベル:「ウ」の場合です。
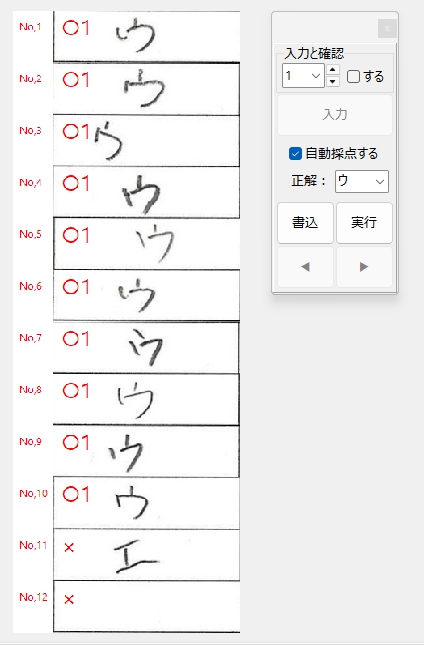
正解ラベル:「エ」の場合です。
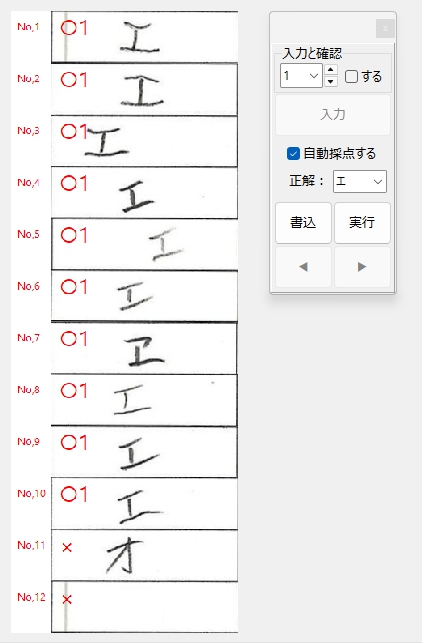
No,1とNo,12の画像に縦方向の直線状の汚れがありますが、推論用画像作成の前段階の処理でその除去に成功しています(これを除去しておかないと、例えばNo,12の画像の推論用データは空白の画像ではなく縦線「|」が入った画像になり、学習モデルは間違いなくこれを「1」と推論してしまうはずです)。
推論用データ(文字の輪郭を検出して縦横28ピクセルの画像として解答欄の画像から切り出す)を作成する前段階で、これらの汚れを除去する処理を入れています。
この「文字を消さずに汚れのみ除去する」処理はけっこう苦労しました。が、なんとか工夫を重ねて実現できました。「エ」の構成部品である「|」を消さずに、左側の汚れの「|」のみ除去するのは大変でしたが、線状の汚れと判断する基準にその高さ(長さ)を採用して、それが画像の高さとほぼ等しい場合は汚れと見なすことで、この問題はクリアできました。
以下、そのスクリプトです(ご参考まで)。
# 画像内の灰色の直線状汚れを除去
import cv2
import numpy as np
import os
from glob import glob
folder = r".\GrayLine"
image_extensions = ["*.png", "*.jpg", "*.jpeg"]
image_paths = []
for ext in image_extensions:
image_paths.extend(glob(os.path.join(folder, ext)))
tolerance = 20 # 画像の高さとの誤差許容範囲(ピクセル単位)
for image_path in image_paths:
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if image is None:
continue
height, width = image.shape[:2]
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, threshold1=20, threshold2=80, apertureSize=3)
lines = cv2.HoughLinesP(edges, rho=1, theta=np.pi / 180, threshold=50, minLineLength=50, maxLineGap=5)
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
angle = np.degrees(np.arctan2(y2 - y1, x2 - x1))
line_length = np.hypot(x2 - x1, y2 - y1)
# 垂直線かつ画像の高さとほぼ同じ長さのみ除去
if (abs(angle - 90) < 1 or abs(angle + 90) < 1) and abs(line_length - height) < tolerance:
cv2.rectangle(image, (x1-5, 0), (x2+5, height), (255, 255, 255), 2)
cv2.rectangle(image, (x1-4, min(y1, y2)-5), (x2+4, max(y1, y2)+5), (255, 255, 255), -1)
cv2.imencode(".png", image)[1].tofile(image_path)
正解ラベル:「オ」の場合です。
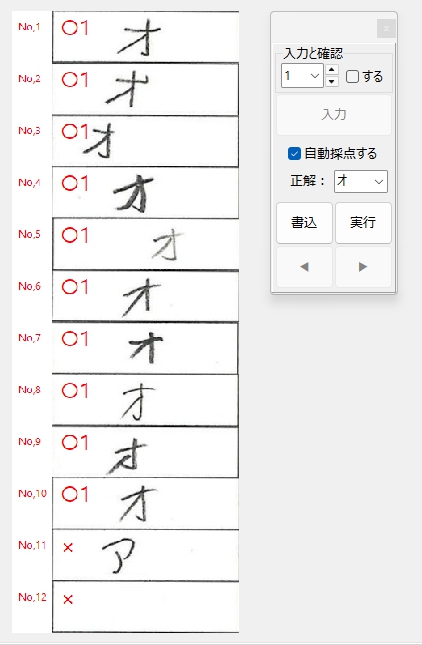
カタカナ「アイウエオ」の5文字は間違えずに推論できました。イイ感じです。
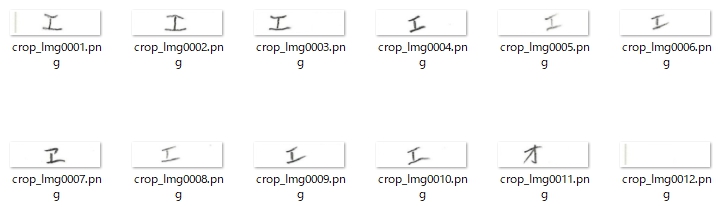
次は数字の「12345」。何となくイケそうな気がしてきました☆
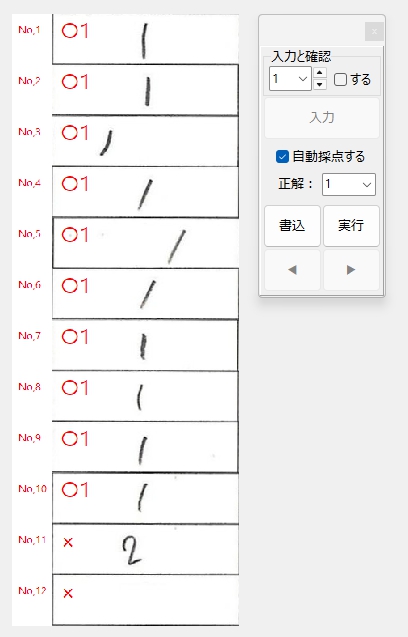
正解ラベル:「1」の場合です。
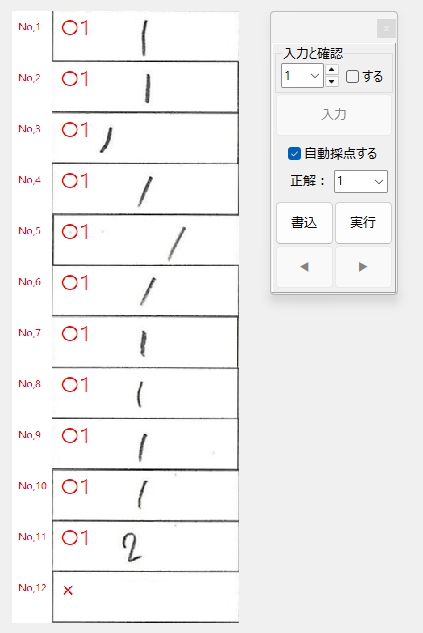
あ・れ・?
なんで「2」に〇が・・・
夢なら覚めてくれ・・・ T_T
一瞬。そう思いましたが・・・
大丈夫。転ぶのには慣れています。これまでだって さんざん・・・、
ここまで来て、あきらめるなんて、そっちの方が無理です。
急いで推論用の画像を確認。
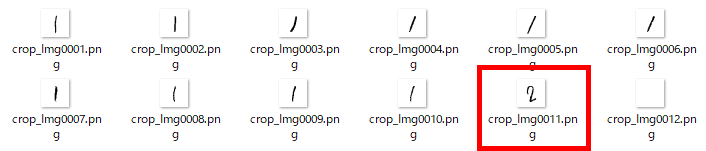
・・・ ということ は、学習データに問題があった ってコトか?
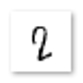
左へ 微妙に傾いているように見えます・・・
よくよく考えてみると、このような左に傾いた「2」は、利き腕が右の場合、なんとなく書きにくいような気もします。このことから、つまり、推論をミスした原因は、学習用データとして用意した画像の中に、左に傾いた「2」が少なかったため(?)ではないかと思えてきました。
見たところ、この「2」の画像には極端なシミも汚れもなく、色の濃さも十分、形状もちょっと縦に伸びてるかなって感じもしますが、まぁ、これは一般的にどう見ても「2」です。輪郭検出にも間違いなく成功して期待通りに切り出せている以上、やはり推論ミスの原因は「その傾きにある」としか思えません。
そこで・・・ ナニをしたかというと、
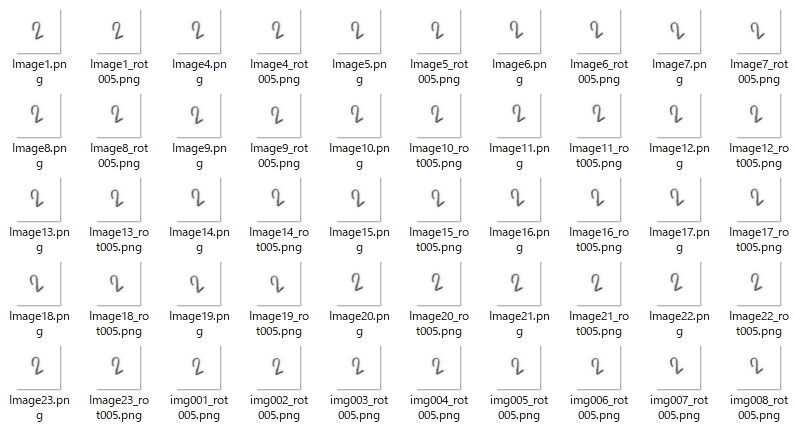
取りあえず、1~20°の範囲で、0.5°ずつ傾きに変化をつけ、推論をミスした「2」を左に回転させた画像を上のように50枚用意(処理する際に名称は関係ないので、ファイル名に一貫性はありません)して、さらに「2」の学習データは全体で約7000枚あるので、その1割にあたる700枚を抜き出し、ランダムに5°、10°、15°、20°のいずれかの角度で左に回転させ、先に用意した50枚と合わせて水増し学習データを合計750枚作りました。
「水増し」なんて言うと(文脈にもよりますが)どちらかと言えばネガティブな意味を含むことが多く、なんだか、とてもずる賢い・よからぬことをしているように感じますが、機械学習で使われる「水増し」という言葉は、 データ拡張(Data Augmentation) という概念を表すもので、基本的に悪い意味はないようです。むしろ、このテクニックは、モデルの汎化性能を向上させ、過学習(Overfitting)※を防ぐために重要な技術とされているようです。十分な学習データがない場合に、画像の回転・拡大・ぼかし・ノイズ追加などを行うことで、実質的にデータ数を増やせますし(=過学習の防止という意味でもこれは有効)、既存の学習用データに回転(やりすぎは禁物!)や、サイズ変更して作成した水増し学習用データを加えて学習モデルを作れば、異なる角度やサイズの文字にも対応できる、より頑健なモデルにすることができます。
※ 過学習(Overfitting):学習用データが少なかったりすると、学習モデルがそのデータに最適化されすぎてしまい、汎化性能が低下してしまうことを言うそうです。つまり、見たことがあるデータしか、推論に成功しなくなる(見たことがないデータに対して非常に弱くなる)わけですね。
こうして作成した水増し学習用データをを元の約7000枚に追加し、画像をランダムに並び替えて、連番の名前を付け直し、約7800枚の「2」の画像データを作り、そのうち1/3のデータは余白「4」、1/3のデータは余白「5」、1/3のデータは余白「6」を設定(余白の取り方を変更してモデルの汎用性を高めるため)して再学習用の縦横28ピクセルの画像データに変換し、1、3、4、5の各学習用データと合わせて、カタカナ「アイウエオ」の学習モデルを再度構築し直しました。
実際は、再度ではなく、再々々々・・・度の「構築し直し」ですが。
夢は、きっと、叶えるために、あります。
基本的な考え方としては(間違っているかもしれませんが)、学習用データの余白分布が4~6ピクセルであれば、モデルはその範囲内の「平均的」な状態、すなわち中央値に近い値(つまり5ピクセル)に合わせた特徴抽出を学習する(=最も代表的な状態に合わせて内部の重みが調整される)と仮定して・・・
(推論用データの余白の設定を中央値にすると正解率が良いように経験的に感じたのです)
この仮定がもし正しければ、推論用の画像データはそのすべてを「検出した輪郭の周囲に余白5を指定して作成」することで、モデルは最も慣れている条件下で推論動作を行える=最も良い正解率を示すはずだと・・・
実は、この輪郭検出(=文字認識)後、その周囲にどの程度の余白を設定するかについて最初は適当に「8」とか指定していたのですが、モデルの汎用性を高めるためには、学習データの余白の設定は一律に同じ設定としない方が良いはずなので、ある時、ふとその1/3に余白「8」、1/3に余白「9」、1/3に余白「10」を設定して学習モデルを作成し、推論の成否を確認していたところ、推論用データの余白を「9」に設定した場合に正解率がよくなるように感じました(正確に統計をとったわけではありません)。それと最終的には、学習用データ・推論用データともに縦横28ピクセルの画像とすることから、中央に配置した文字が実質縦横20ピクセル程度の領域に入る余白「4・5・6」あたりが最も適当であろうと考えたわけです。MNISTの作りを見ても、この考えは正しいように思われました。
もちろん、学習用データの余白を3・4・5として、推論用データの余白を中央値の4とする設定も考えましたが、余白が3ピクセルではさすがに小さすぎるのではないかと思い直し・・・ つまり、ちょっとした輪郭抽出のズレでも、文字がフレームに近づきすぎて、文字の上下左右の位置のバラつきが大きくなり、モデルが位置変動に過敏になる可能性が大きいと考えました。
逆に余白が6ピクセルと大きい方が、余白を3ピクセルとした場合よりも、文字が中央に安定しやすく、多少のズレがあっても特徴が大きく変わらなくなるはずです(機械学習においては、機械が覚え込んだ特徴量に近い特徴量を示す推論対象が正解とされるわけですから、このことは非常に重要です)。解答欄画像から輪郭検出を行って推論用データを作成する際の余白の設定を様々に変えて試行している際に、わずか1ピクセル、余白の設定を変更しただけで、正解になったり、不正解になったりする事実(プログラムのテストを繰り返す中で、この現象に気づいた当初は本当に不思議に感じました)は、まさにこの推測が正しいことの証明ではないかと思われました。
最終的には、すべて縦横28ピクセルの画像データとするわけですから、このあたりの判断がコトの成否を分ける、言わば「運命の分岐点」であったと、今、ここまでの歩みを振り返って思います。
また、この各数字の画像が約7000枚ずつあるというのは、僕の制作環境においては学習モデルを作成可能な制限ギリギリの値であったようで、学習モデル作成にあたってはまずPCそのものを再起動し、他のアプリが一切動作していない(メモリが十分に空いている)状態を作ってから、学習モデルを作成するスクリプトを実行する必要がありました。
ちなみに僕のPC環境(仕様)は、以下の通りです。
【デバイスの仕様】
プロセッサ 11th Gen Intel(R) Core(TM) i7-1185G7 @ 3.00GHz 3.00 GHz
実装 RAM 32.0 GB (31.7 GB 使用可能)
システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ
ペンとタッチ 10 タッチ ポイントでのペンとタッチのサポート
【Windowsの仕様】
エディション Windows 11 Pro
バージョン 24H2
インストール日 2024/10/05
OS ビルド 26100.4351
エクスペリエンス Windows 機能エクスペリエンス パック 1000.26100.107.0様々なアプリを使用した後や、Webブラウザを開いたままの状態で学習モデルを作成するスクリプトを実行すると、必ず「メモリが足りません!」というエラーメッセージが表示され、学習モデルの作成に失敗してしまうので、「再起動直後に実行する」という手を思いつく前は、「もはやこれまで」とせっかく作った学習データを減らそうかと思ったりもしました。
誰も教えてくれる人はいませんので、すべてが手探り状態で、後から考えれば実に様々な「それくらい最初から気がつけよ!」みたいな「プロから見れば当たり前のこと」に気づくまでに、試行錯誤を繰り返し、膨大な時間を費やしつつ、一歩一歩前進するしかありません。
昼間は仕事があるし・・・、夜はあたまの回転がトロくなるし・・・、なんや・かんやで、
だいたい日付が変わる頃に目を覚まし、あとは朝が来るまで、ちいさな灯りをともして・・・
僕の人生の中で、いちばん充実した「時」を過ごします・・・
自動採点を、あきらめない以上は・・・ その時々で、僕に出来る最善を尽くすのみ です。
何はともあれ、左に傾いた「2」を新しく学習したモデルが出来ました!
このモデルを用いて「1」の推論に再チャレンジした結果です。
やった! やった!!
なせばなる!!!
もちろん、余白の設定は「5」としてあります。
正解ラベル:「2」の場合です。
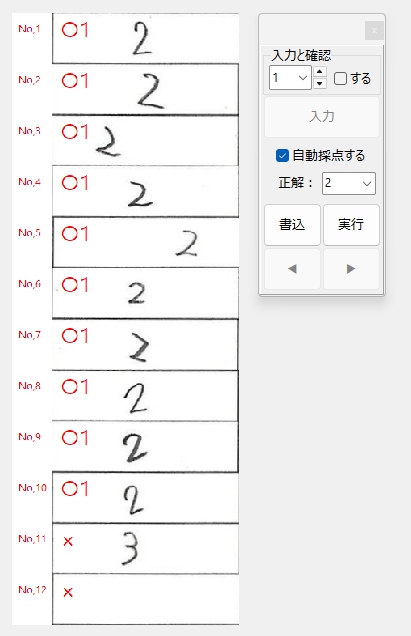
実は、No,11の画像は、検証用にわざと誤りのデータを他の画像から切り貼りして作成したものです。
つまり、正解ラベル「1」のNo,11の「2」と、上のNo,10の「2」は同じデータと思われます。
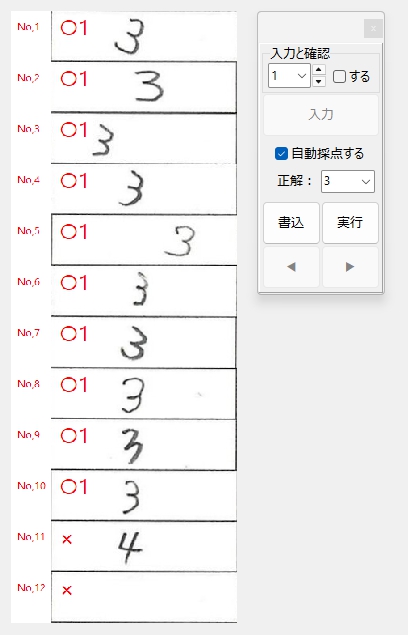
正解ラベル:「3」の場合です。
正解ラベル:「4」の場合です。
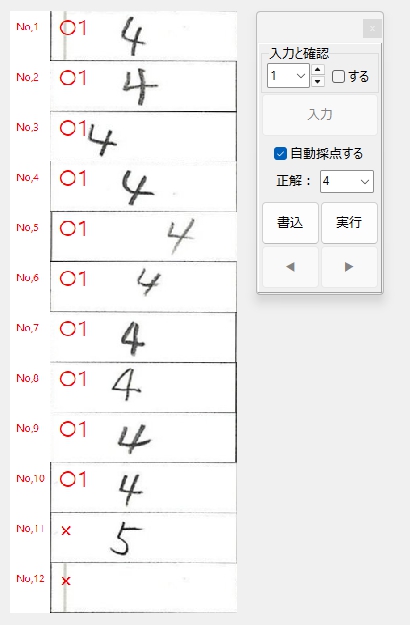
正解ラベル:「5」の場合です。
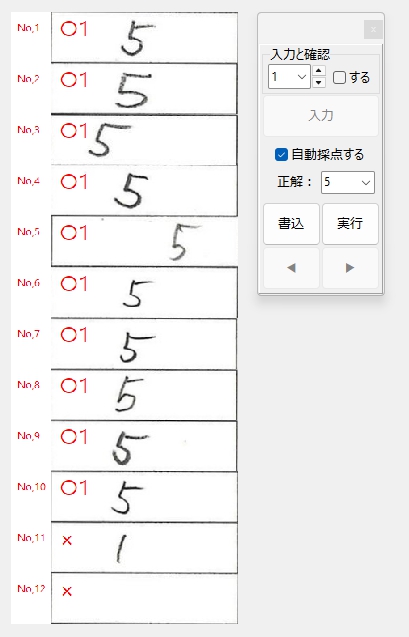
数字も正しく読めるようになりました☆
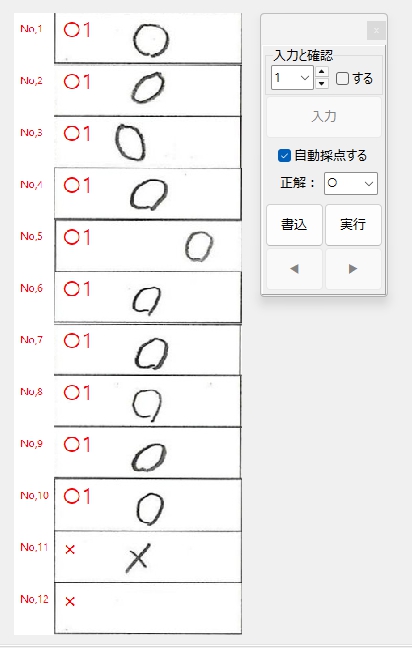
次は、記号の「 ○ と × 」です。
正解ラベル:「 ○ 」の場合です。
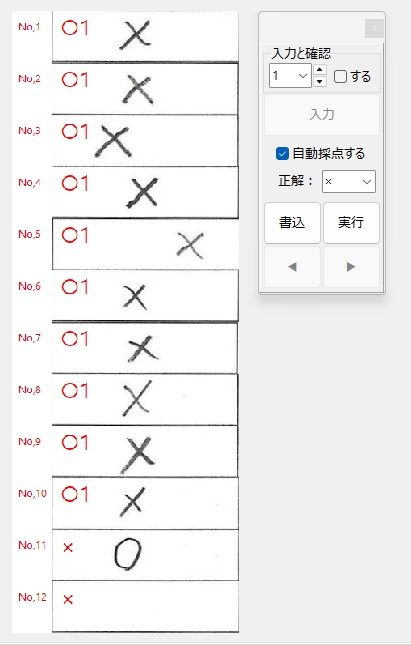
正解ラベル:「 × 」の場合です。
・・・・・・・
2025 年 6 月 15 日 午前4時
とうとう・・・
夢がかないました!
とても静か・・・
まだみんな
眠っています。
これも夢かもしれません。
夢なら、どうか・・・
覚めないでください。
2.自動採点機能の使い方
ダウンロードした zip ファイルを展開すれば、すぐにお試しいただけるよう、次に紹介する採点サンプルデータを同梱してあります。記事の説明を参照しながら、操作していただけますよう、お願い申し上げます。
この記事の冒頭にも書きましたが、プログラムの動作には「Microsoft Visual C ++ ランタイムライブラリ」のインストールが必要です。お使いのPCに「Microsoft Visual C ++ ランタイムライブラリ」が入っていない場合は、下記 Web サイトから「VisualCppRedist_AIO_x86_x64.exe」をダウンロードし、ダウンロードしたプログラムを管理者権限で実行し、動作に必要なライブラリをPCにインストールしてください。なお、インストール時には Windows のユーザーアカウント制御(UAC) が起動し、管理者用のID とパスワードの入力を求められます。インストールでは、exe の名称からわかるように 32 ビット版と 64 ビット版それぞれの VC++ランタイムライブラリがお使いの PC にセットアップされます。なお、インストール後は(僕のPC環境では)再起動なしで、そのまますぐに AC_Reader.exe を実行できました。
「VisualCppRedist_AIO_x86_x64.exe」の入手先:
https://www.majorgeeks.com/files/details/visual_c_redistributable_runtimes_aio_repack.html
2025年6月11日現在、バージョンは「0.91.0」でした。上記 Web サイトの Download (64-Bit EXE) というリンクをクリックすればインストールプログラムをダウンロードできます。
【採点の準備】
AC_Reader.exe をダブルクリックしてプログラムを起動したら、「採点作業」ボタンをクリックします。ここで「Windows によって PC が保護されました」と書かれた青い画面が表示された場合は、当 blog の過去記事に対応方法の詳細な説明を載せてありますので、そちらをご参照ください。
この青い画面( Windows Defender SmartScreen )に関するより詳細な説明は、次の過去記事にも掲載しています。もし、よろしければ合わせてご参照ください。
「採点作業」ボタンをクリックすると、次のメッセージが表示されます。
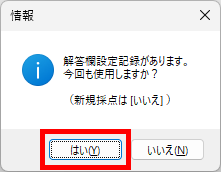
「はい」をクリックすると、既存の採点設定を選択できるようになります。
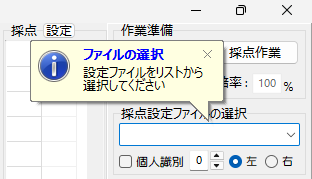
採点設定ファイルを選択するには、ComboBox の右側の ∨ マークをクリックします。すると候補の選択肢として採点サンプルファイルが1つだけ表示されますので、これをクリックして選びます。
案内メッセージが表示されます。
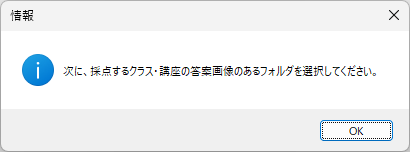
「フォルダ選択」用のダイアログが表示されますので、解答用紙画像の入っている「フォルダを選択」してから OK をクリックしてください。
【重要】 選択するのは「フォルダ」であって、「ファイル」ではありません!
案内メッセージが表示されます。よく読んで OK をクリックしてください。
【採点設定ファイルとフォルダの関係】
最初に選んだ「採点設定ファイル」は、試験で使用した解答用紙の解答欄の座標他が登録されています。ですので、同じ解答用紙を使用して行った試験であれば、すべて同一の採点設定ファイルで採点作業を行うことができます。
通常、テストは「クラス単位」で実施されますが、採点設定ファイルはどのクラスに対しても共通で利用しますので、クラス名を入れない名称を付けて保存(例:R7_考査①_数学Ⅰ)するよう、ユーザーの皆さまにはご案内しています。
解答用紙の画像は、通常であれば「クラス名を付けたフォルダ(例:R7_考査①_数学Ⅰ_1A)」に保存するのが一般的であると思います。
ですので、このプログラムの実際の運用に当たっては、「採点設定ファイルにはクラス名を入れず、解答用紙の画像を保存するフォルダにはクラス名を含めた名前を付けてください。」とユーザーの皆さまへご案内しております。
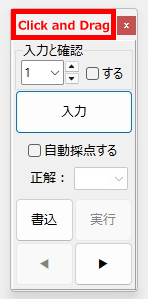
【採点方法】
自動採点は、次の GUI で行います(僕は「フローティングパネル」と呼んでいます)。いろいろ考えてデザインしましたが、使い勝手がよくないと感じられる方もいらっしゃるかもしれません。そうだったら、ほんとに、ごめんなさい。
そのまま(左ボタンを押したまま)ドラッグすると、
フローティングパネルを任意の位置へ移動できます。
(閉じるボタンは無効化してあります)
まず、現在、採点しようとしている設問への配点を設定します。
以下、手動採点時の採点方法の説明です。
手動採点時には、このまま、配点設定欄の下にある入力ボタンをクリックすると、配点設定欄が「0」であれば、現在表示されているすべての解答欄に不正解の「×」が、配点設定欄が「1以上」であれば、現在表示されているすべての解答欄に正解の「○」が(設定によっては配点の数字も)自動で入力されます。
これは、つまり、手動採点時には、初めに解答欄全体の出来栄えを見て、全体的によく出来ているような場合は一括して正解とし、不正解の解答欄だけを手動で採点、逆に全体的に出来がよくない場合には、一括して不正解とし、正解の解答欄だけを手動で採点した方が、効率よく採点できると考えて、このような仕様としました。
もちろん、自動採点時には、この入力ボタンをクリックする必要はありません。
また、配点を設定する ComboBox の右隣りの CheckBox「□する」にチェックを入れると、手動採点時に入力ボタンをクリックして、一括採点操作が行われる前に確認メッセージが表示されるようになります(誤入力を防ぎたいという、ユーザーからの要望で追加した機能です)。
【ここから自動採点の実行方法の説明です】
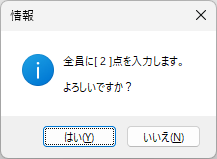
配点を入力後、自動採点を行う場合は、「□自動採点」にチェックを入れます。
次に、その下にある ComboBox からその設問の正解を選び、実行ボタンをクリックします。
正解として指定できるのは・・・
・カタカナの「ア・イ・ウ・エ・オ」のいずれか1文字、
・記号の「○・×」のどちらか1つ、
・数字の「1・2・3・4・5」のいずれか1つです。
これ以外のカタカナ(例えば「カ」)、記号(例えば「△」)、数字(例えば「6以上の数字」)は指定できません(決まりとして指定できないだけで、正解ラベルとしてComboBoxの入力欄に入力することはできます・・・が、正しく採点することは絶対に不可能です)。ただ、数字のゼロは、たぶん記号の「○」で代用が可能かと思われます・・・ ので、数字については、もしかしたら「0・1・2・3・4・5」の6種類が採点可能かも?しれません(試していませんが)。
また、正解ラベルに指定する文字・記号・数字は、直接入力せず、ComboBox の選択肢から選択してください。記号の「○:まる」に誤って漢数字の「ゼロ:〇」を指定しないようご注意願います。漢数字のゼロは「まる」の変換でも IME の変換候補の選択肢に表示されるので十分注意してください。
採点が完了すると、解答欄の画像の左上に、採点記号(自動採点を利用した場合は、○ or × のいずれか)と、先に設定した配点が赤く表示されます(表示位置は任意の位置に変更できます。変更方法は上で紹介しました当 blog の過去記事をご参照ください)。
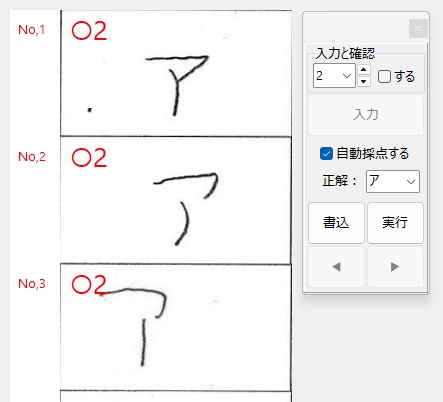
【お願い】
ここで、全ての解答欄について、機械の採点結果を目視で必ず確認してください。
※ このプログラムは、添付した学習モデルの性能が及ぶ範囲で「正解・不正解」のいずれかを判定する自動採点を実行しますが、自動採点結果について、それが常に 100 %「正しい」ことを保証するものではありません。自動採点を行った結果につきましては、必ず、ご自身の責任で、直接、目視によって、その成否をご確認いただけますよう、お願い申し上げます。この使用条件に完全に同意し、かつ確実に目視による確認作業を実行していただける方のみ、このプログラムをお使いいただけますことを申し添えます。このプログラムに搭載した手動及び自動の採点機能を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。
【修正が必要な場合】
もし、修正が必要な場合は、修正対象の解答欄の画像をまずクリックします。
・正解に修正する場合は、配点に相当する数字キー(その設問の配点が「2」なら「2」のキー)を押下げします。
・不正解に修正する場合は、「B」キーを押下げします。ちなみに「B」は「 ×:Batsu 」の頭文字で、右手でマウス・左手で手動採点する際に「B」キーは押しやすい位置にあり、また、機能を覚えやすいんじゃないかと考え、「B」を不正解の入力キーとしました。
【採点結果の保存方法】
採点結果を保存(=書込み)しないと、次の解答欄を表示することはできません。実行の左隣にある「書込」ボタンをクリックしてください。採点結果が保存されます。
3.推論用画像データの確認
プログラム設計時の動作検証用に作成した機能ですが、解答用紙画像から切り出した解答欄画像と、その解答欄画像から切り出した推論用画像データの状態を確認することが出来ます。
【解答欄画像の確認方法】
まず、次のように、正解ラベルが「空欄」の状態で確認作業を実行した場合、解答用紙画像から切り出した解答欄画像を確認することが出来ます。
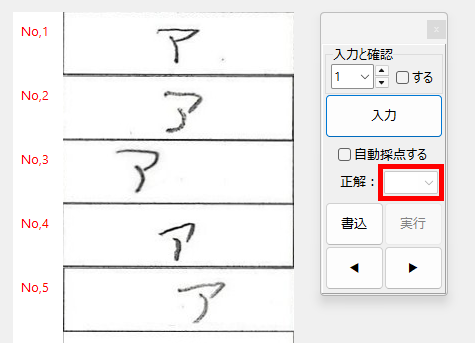
正解ラベルが「空欄」のままであることを確認した後、「設定」→「推論用画像を確認する」の順にクリックしてください(元々、開発時に推論用画像を確認するために設けた機能なので、ボタンの名称が「解答欄・・・」ではありません)。
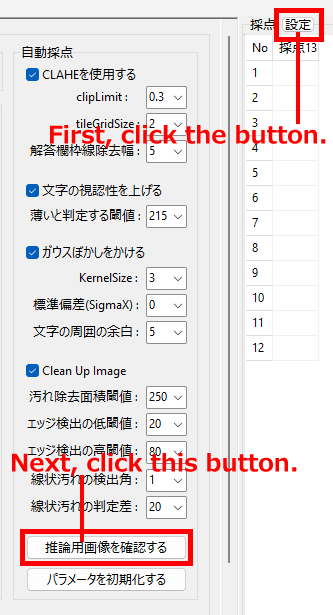
【重要】 設定画面表示中は、Form の「閉じる」ボタンは無効化されます。
解答欄画像が表示されます。
解答用紙から切り出した解答欄画像のクリーニングは、採点作業補助用の GUI (フローティングパネル)の CheckBox 「□自動採点する」をチェックして、さらに正解ラベルが空欄ではない状態で、実行ボタンをクリックすると行われる(ように設定してある)ので、クリーニング前の状態を確認したい場合は、自動採点を実行する前の段階、すなわち、「◀」もしくは「▶」ボタンをクリックした直後の、まだ「□自動採点する」をチェックせず、正解ラベルも指定していない状態で、「設定」ボタンをクリックして、「推論用画像を確認する」※をクリックすれば(クリーニング前の解答欄画像を)表示できます。
※リリース版では、上のプロトタイプの状態にさらに画像のクリーニング機能を追加、パラメータが増えたため、ボタンのキャプションは単に「推論用画像」としています。
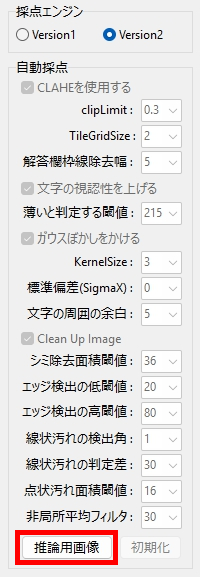
Version1 を選択した場合は、各パラメータを調整できます。
(デフォルト設定は、パラメータを調整済みの Version2 としてあります)
プログラムは、「実行」ボタンをクリックすると、まず、解答用紙から切り出した解答欄画像のクリーニングを行って、それから自動採点を行います。初回のみならず、2度目、3度目の見直し採点時であっても、プログラムは「修正等を一切加えていない無加工の解答用紙画像」から解答欄を切り抜いて解答欄画像として表示しているので、汚れのある解答欄が毎回表示されます。クリーニングが行われるのは、実行ボタンをクリックした後であることにご留意ください。
【点状汚れの除去の例】

クリーニング後の画像は・・・

(ここは後日、さらに改良してより白くなるように修正しました)
【線状汚れの除去の例】
クリーニング後の画像は・・・

【推論用画像の確認方法】
自動採点を実行すれば、推論用に解答欄画像から切り出した、縦横28ピクセルの推論用画像を確認できます。自動採点時、実際に機械が見ているのは、この推論用画像になります。
上の図のような状態で、「実行」ボタンをクリックした後で、「設定」→「推論用画像」の順にクリックします。

縦横28ピクセルの、この小さな画像を思った通りに切り出せるようになるまで、いったいどれくらいの試行錯誤を繰り返したか、今はもうそのすべてを思い出せませんが、自分の中に「あきらめる」という選択肢だけはなかったように思います。
これまでの経験から、ただひとつだけ言えることは、機械学習の成否はこの機械が見る(機械に見せる)画像にあるということです。
学習用データとまったく同じ手法で作成した推論用画像を自分では「ブレない画像」と呼んでいますが、画像中の汚れ・シミ等も含めて輪郭検出した部分の面積を計算し、その大きな部分を組み合わせた範囲を文字として切り抜き、中心位置を計算し、最適な余白を設け、汚れ・シミを除去し、白い部分はより白く、逆に薄い灰色は黒く(濃く)する等、文字の特徴量抽出を阻害する要素をできるだけ取り除いた、わずか縦横28ピクセルの、このちいさな文字。その「作り方」として、僕のとった方法が正解であったかどうかの答えを AC_Reader が出してくれると信じています。
もりろん、手書き文字にひとつとして同じ文字はありませんから、そのような意味で「正しいア」は存在しません。ただ、これまでの経緯から、特徴量抽出で機械が学んだ「ア」こそ、もしかしたら「正しいア」に最も近い「ア」なのではないかと思うようになりました。
ひとことで言えば、「正解がないのに、正解を探す旅」それが今、僕が思う機械学習のイメージです。
4.プログラムのダウンロード
この記事で紹介した「手書き答案の採点補助プログラム AC_Reader.exe」他、この Blog の過去記事に掲載しましたデジタル採点関連のプログラム一式を同梱した DigitalSaiten_All_in_One.zip を次のリンク先からダウンロードできます。なお、ダウンロードとご使用にあたっては、免責事項及び使用条件への同意が必要です。免責事項及び使用条件の詳細は付属の License.txt をご覧ください。
【更新履歴】
・2024年9月29日 初版公開
・2025年8月25日 不具合の修正及び新機能を追加したバージョンアップ版に更新
・2025年8月26日 Anti-Virus Software による『未知バイナリの初回スキャン』の待機状態を改善
・2025年9月22日 連続ボタンクリックで落ちる問題を改善/自動採点機能無し版も同梱
5.お願いとお断り
このサイトの内容を利用される場合は、自己責任でお願いします。記載した内容(プログラムを含む)を利用した結果、利用者および第三者に損害が発生したとしても、このサイトの管理者は一切責任を負えません。予め、ご了承ください。
追記_返却用答案の印刷方法について
元々、この AC_Reader には簡易的な合計点の計算と返却用答案の印刷機能があったのですが、高等学校現場における観点別評価の導入に伴い、返却用答案の印刷プログラムは、マークシートリーダーと共用の別プログラム(ReportCard_2024.exe)としました。
AC_Reader.exe から ReportCard_2024.exe を呼び出して実行できます。ReportCard_2024.exe の操作方法は、当ブログの過去記事をご参照ください。
こちらの過去記事にも ReportCard_2024.exe の操作方法の解説があります。上の記事と合わせてご参照ください。