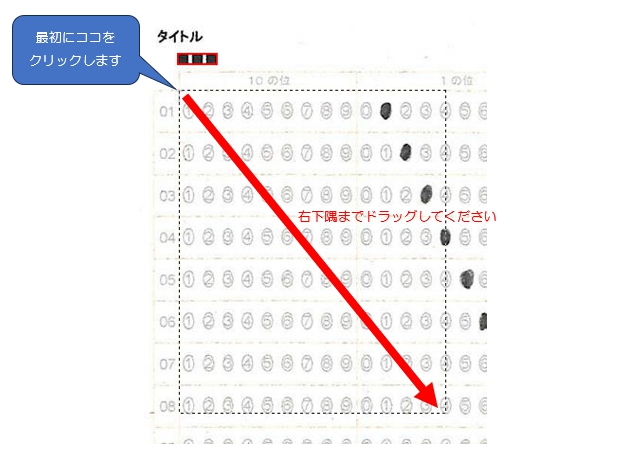
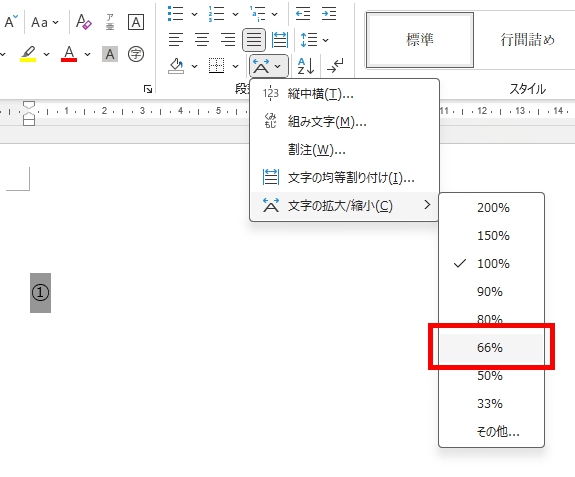
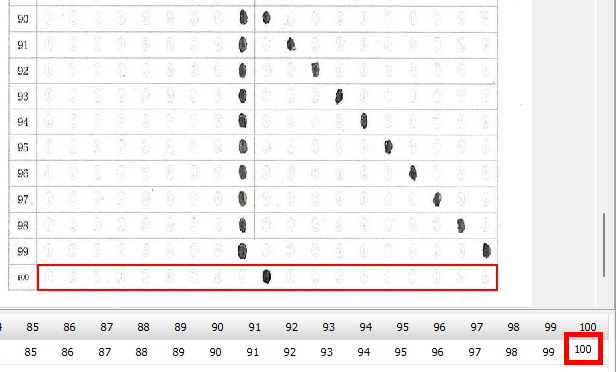
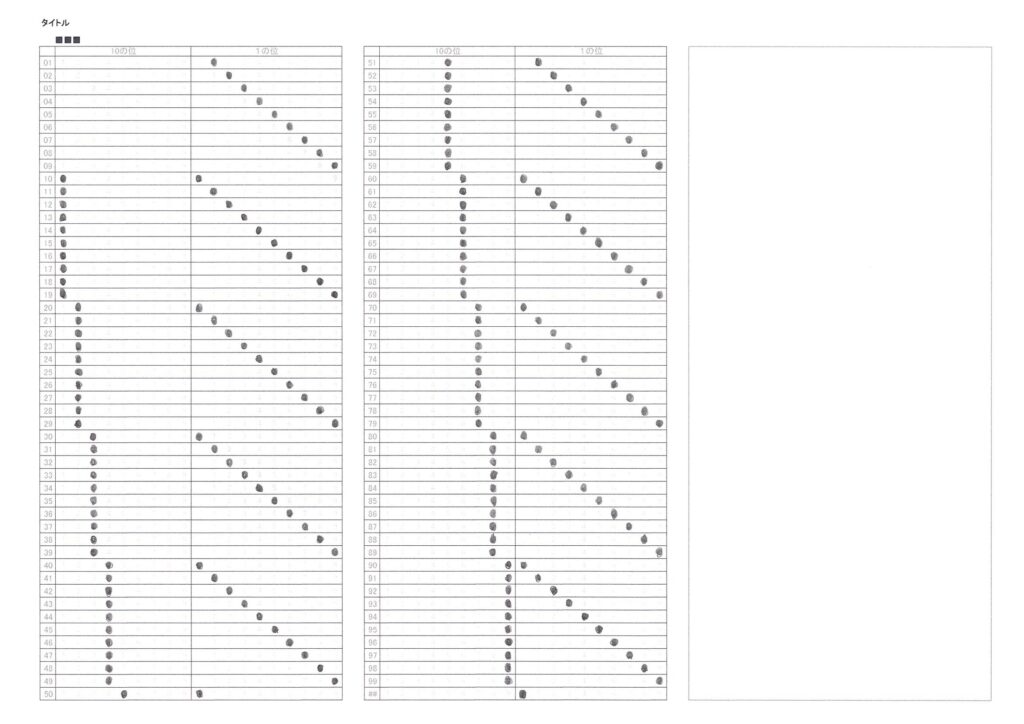
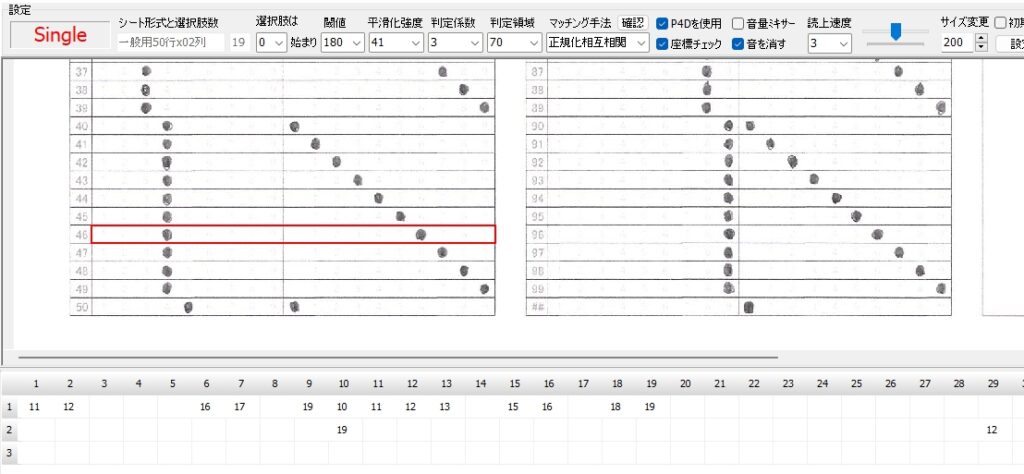
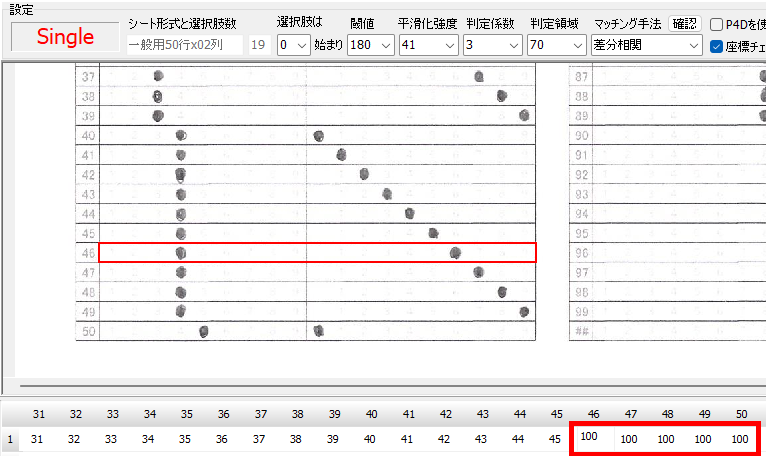
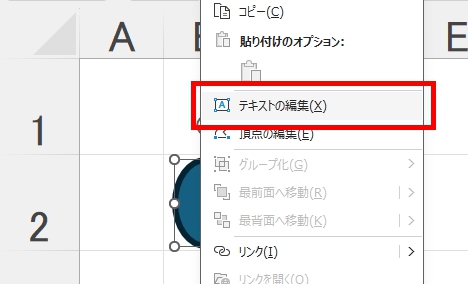
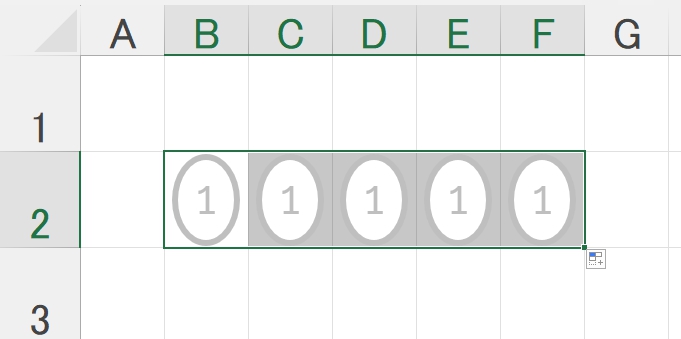
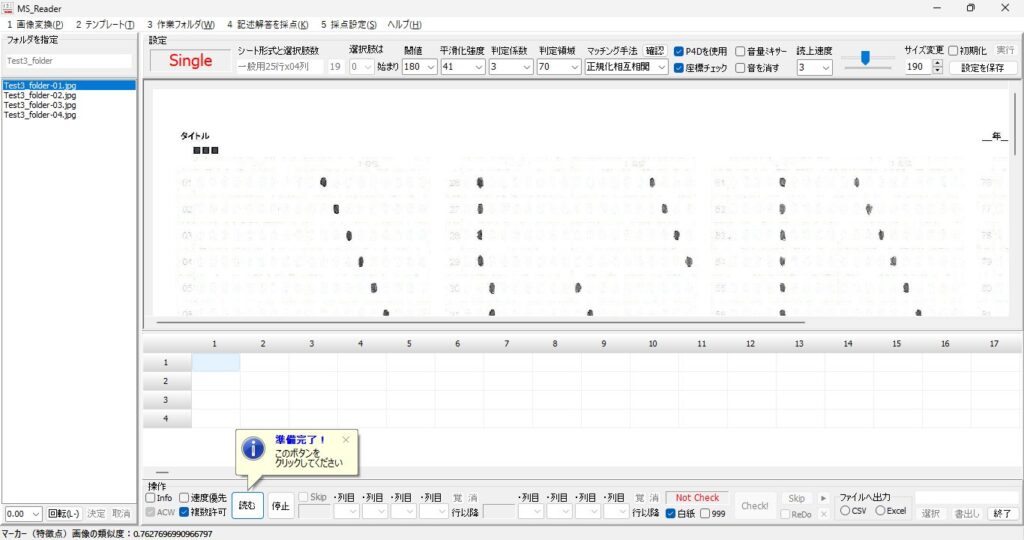
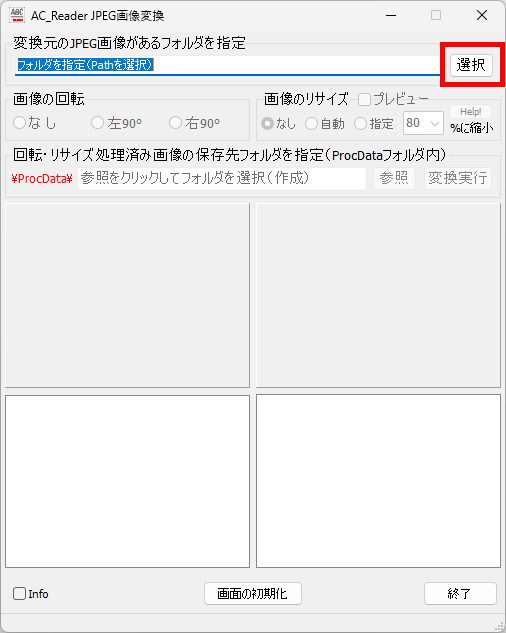
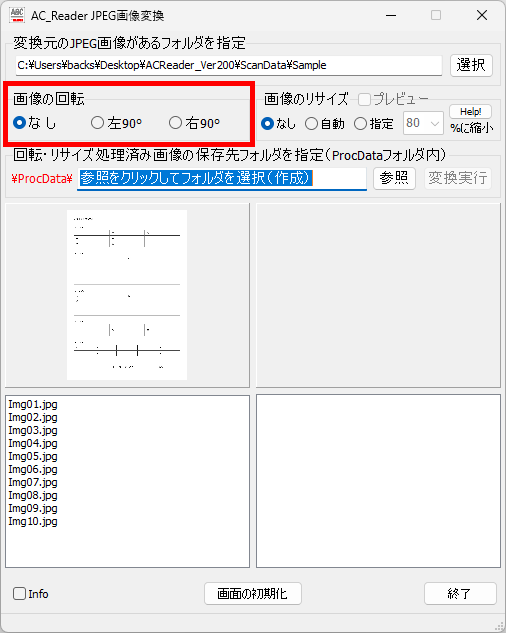
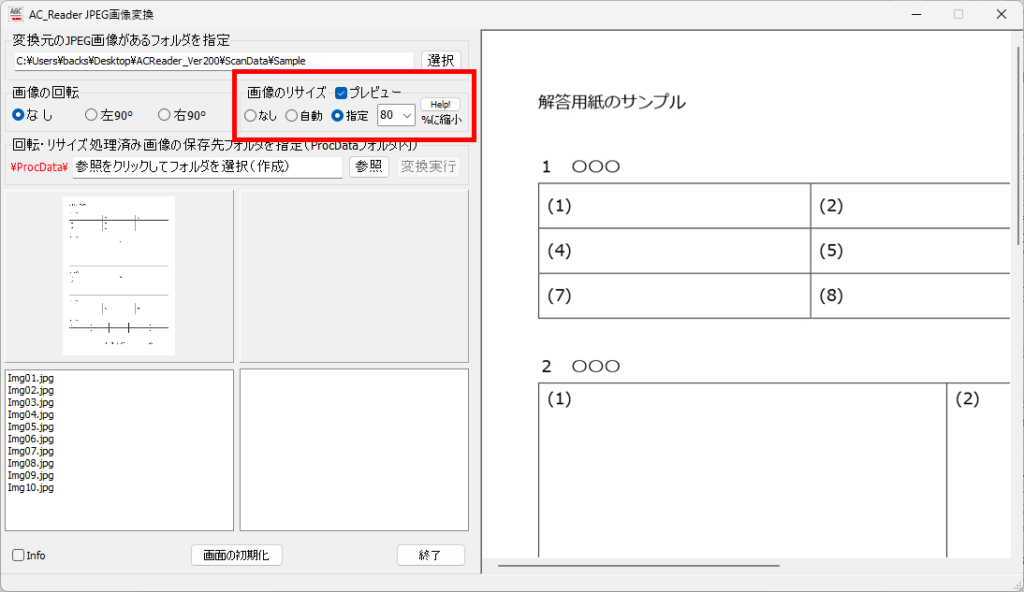
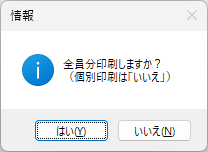
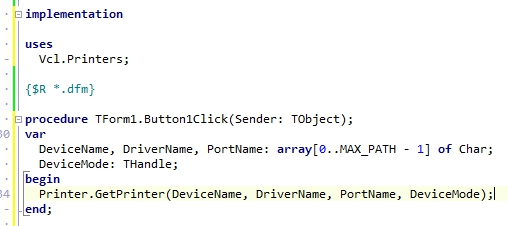
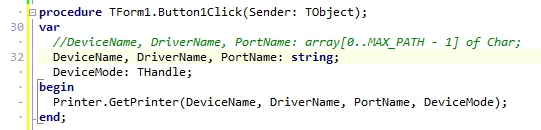
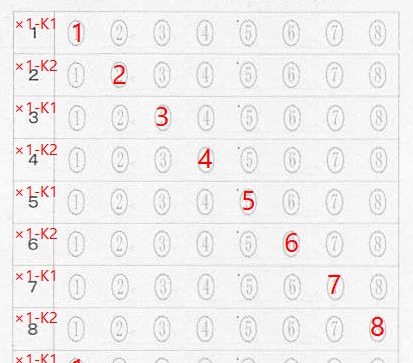
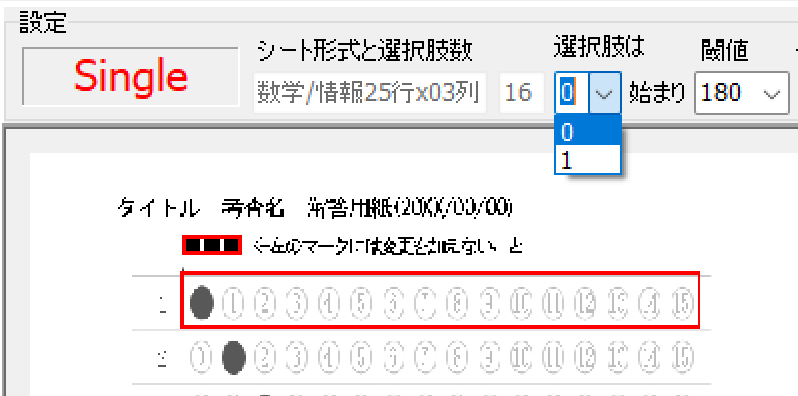
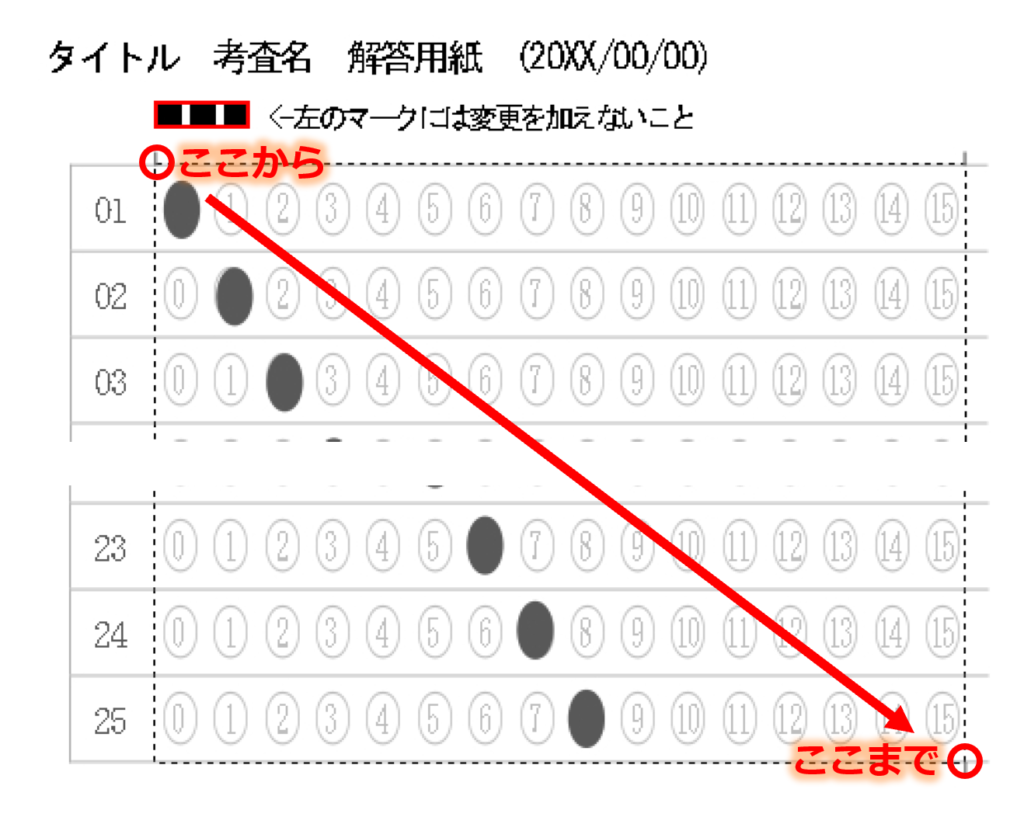
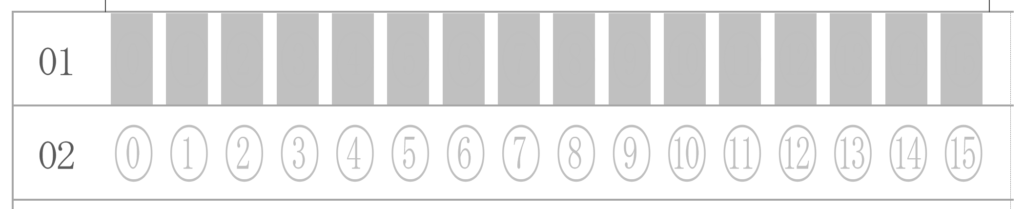
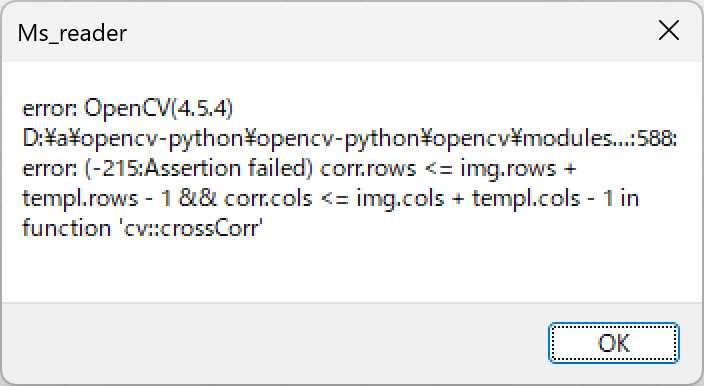
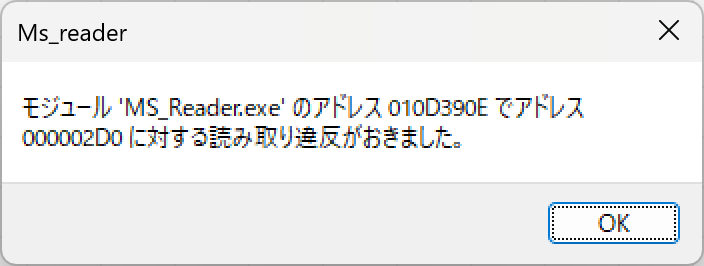
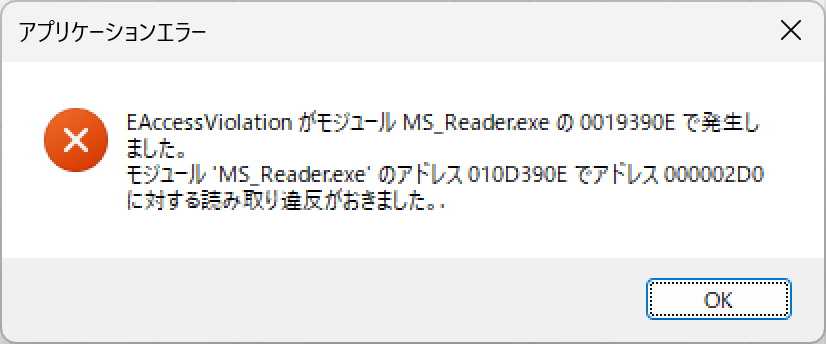
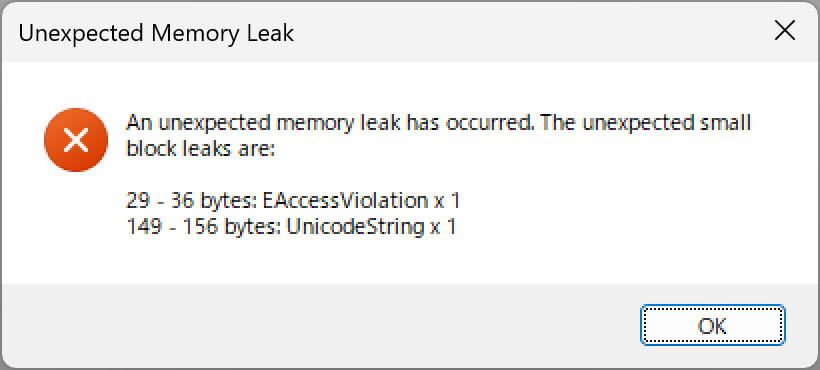
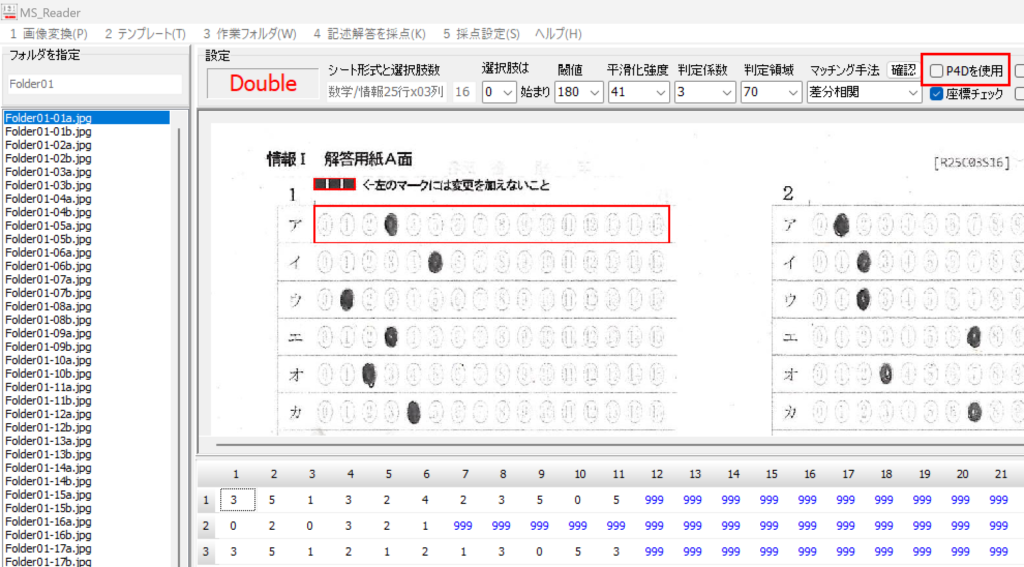
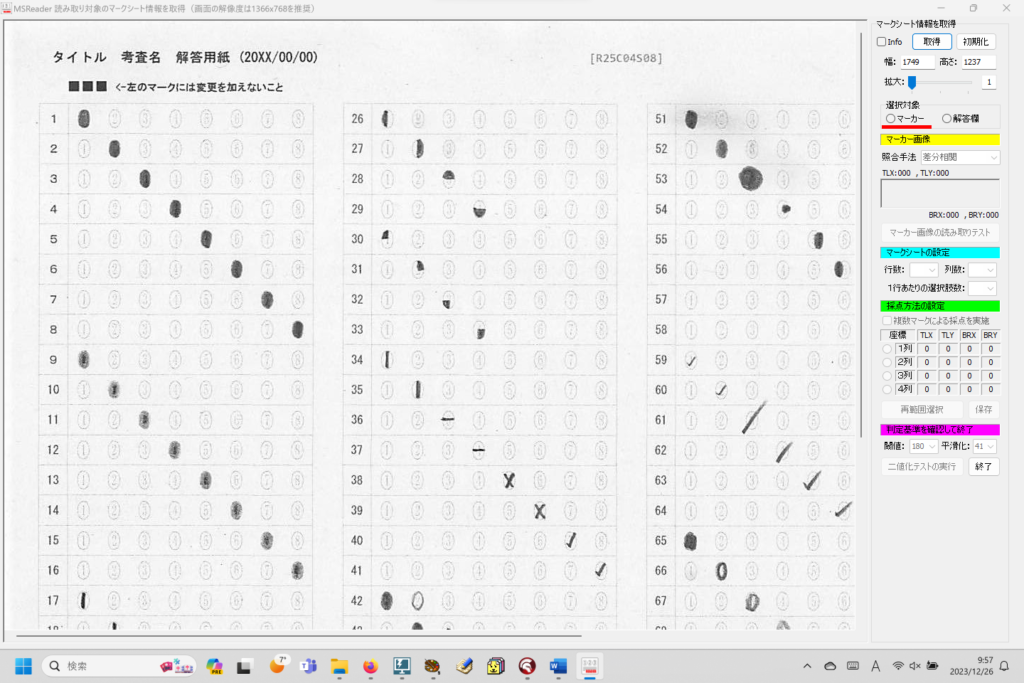
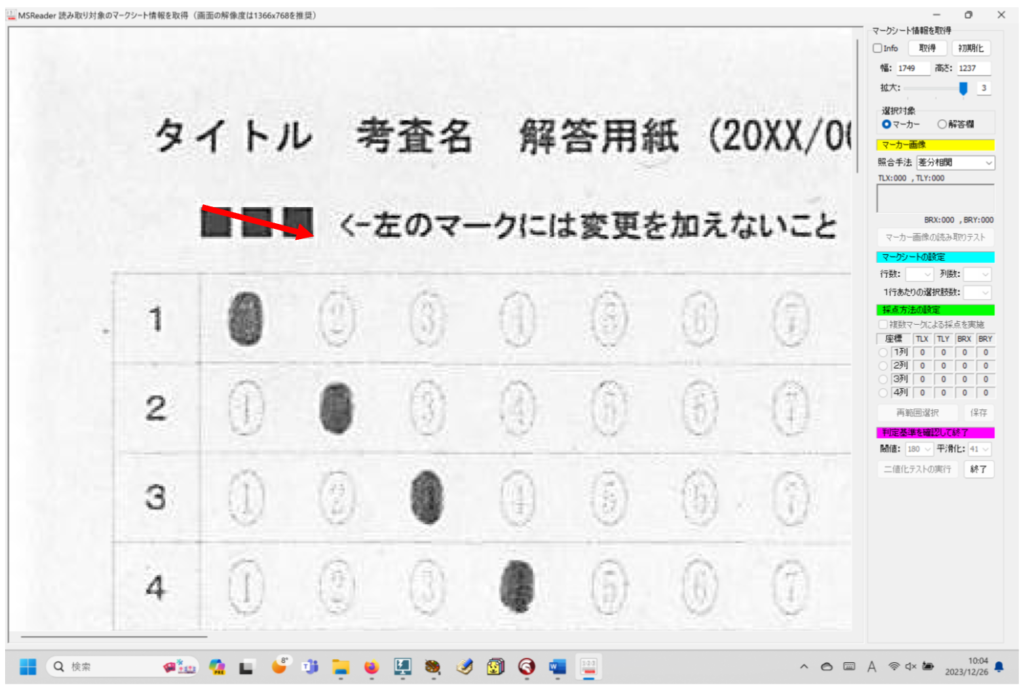
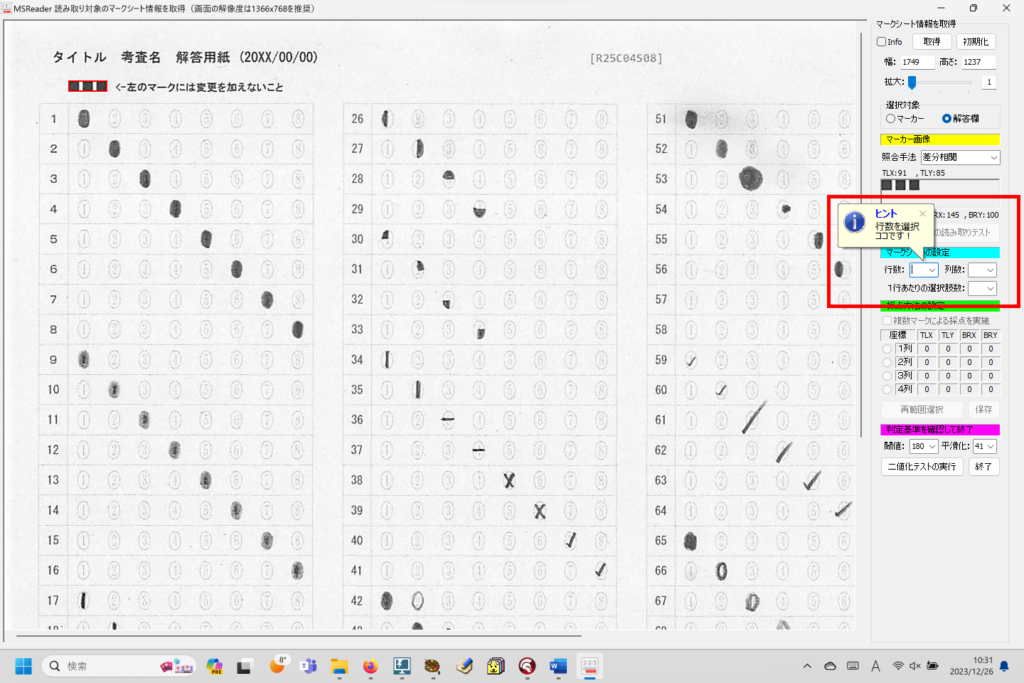
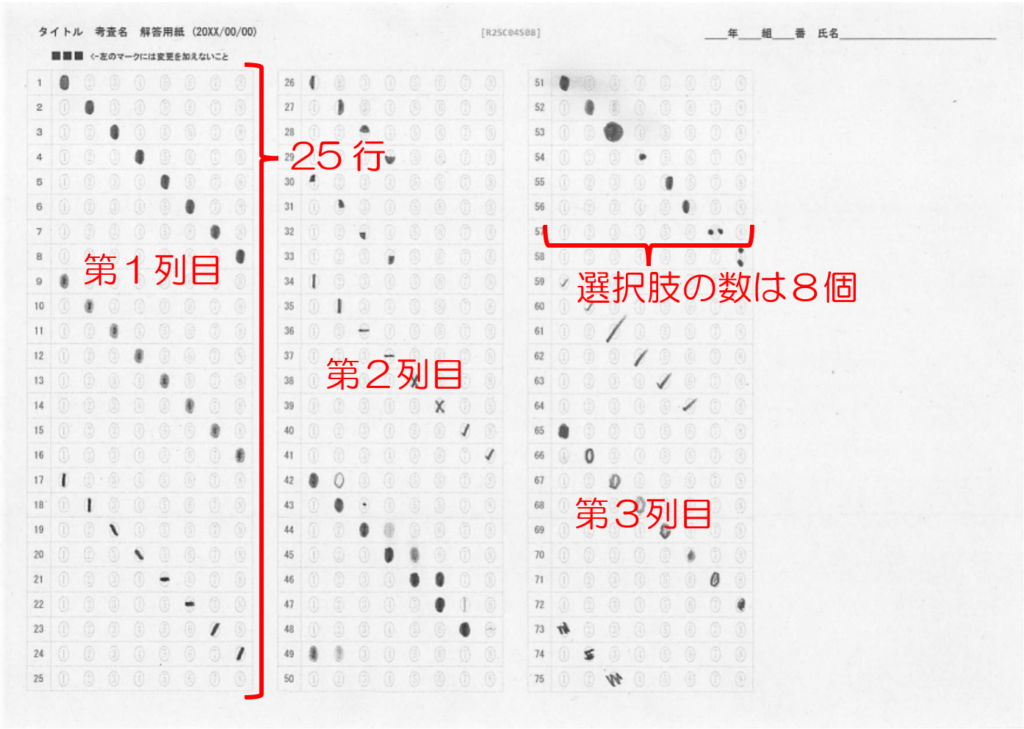
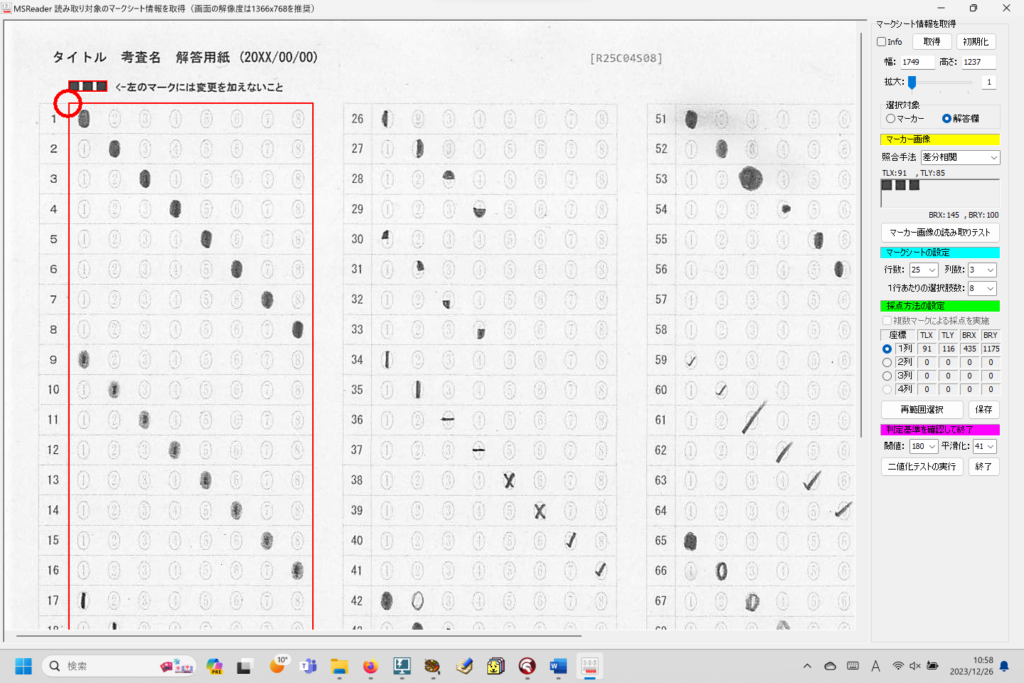
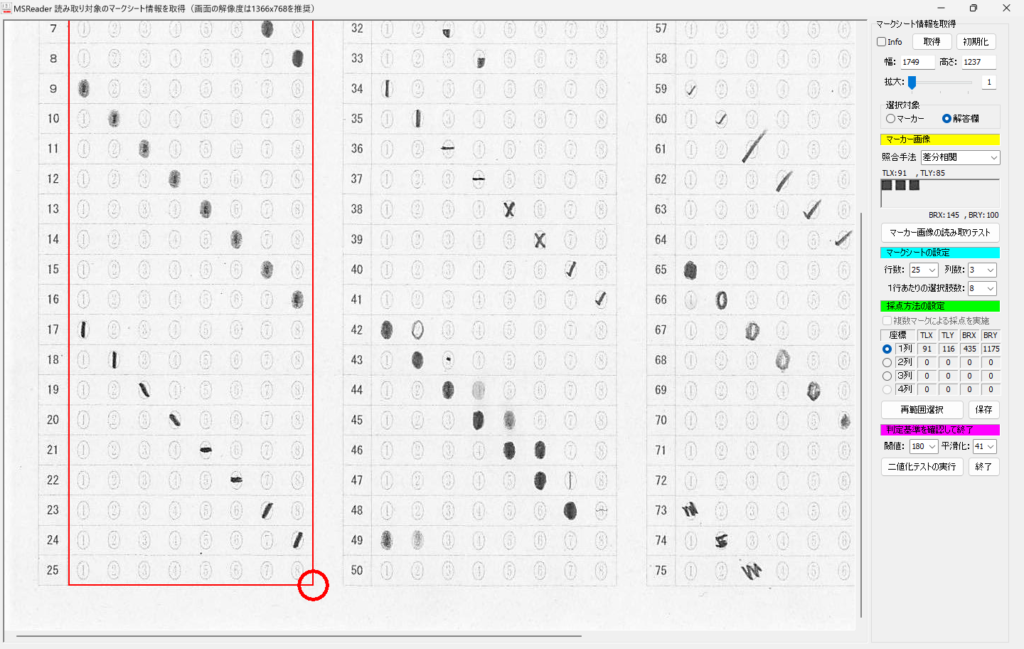
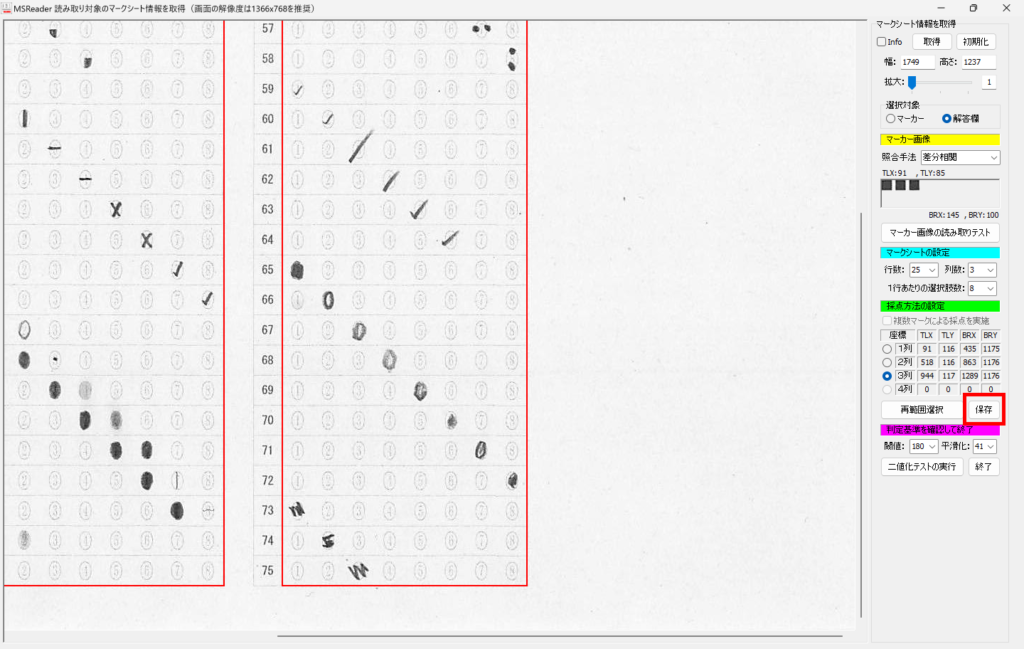
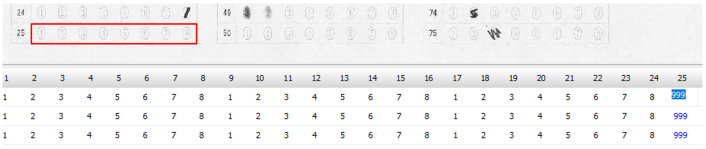
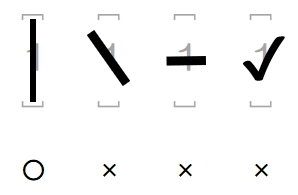対策として、『選択肢番号の外枠の楕円「0」部分をはみ出さないようにマークする』よう注意を徹底することをお願いしたのですが、それだけでは根本的な解決とならないように感じ、マークとマークの間隔が狭いためにこの問題が起きていることは明白ですから、1設問について100選択肢に対応を維持しつつ、1列25行×4列で100設問まで対応という現在のマークシート構成を見直し(マーク間の幅を広げるため列数を減らし)、1列33行×3列で99設問まで対応可能というマークシートを作成しました。また、50分という試験時間を考えると80設問あれば十分というご意見も頂戴しましたので、1列30行×3列で90設問まで対応可能なマークシートや、1列25行×3列で75設問まで対応可能なマークシートを作成し、これらのマークシートを1つの Excel Book にまとめました。以下のリンクからダウンロードできます。
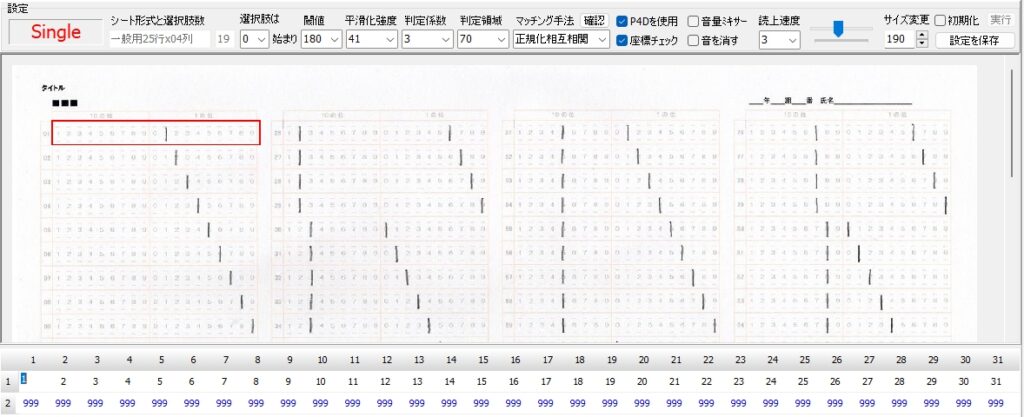
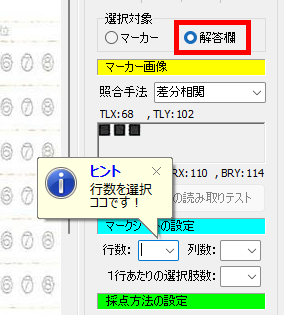
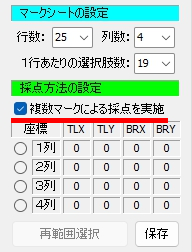
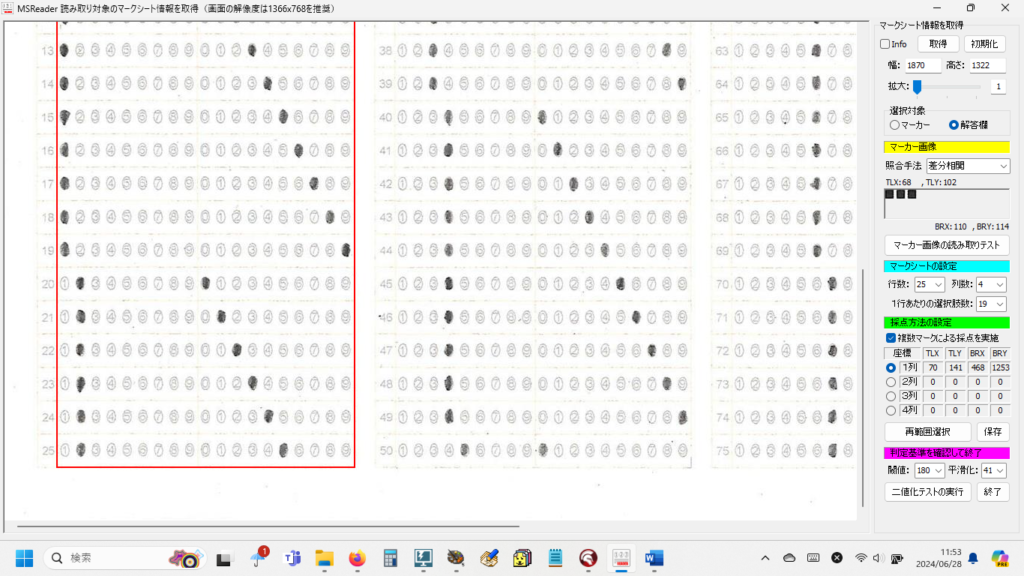
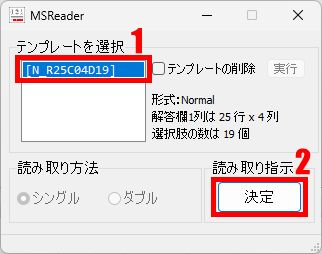
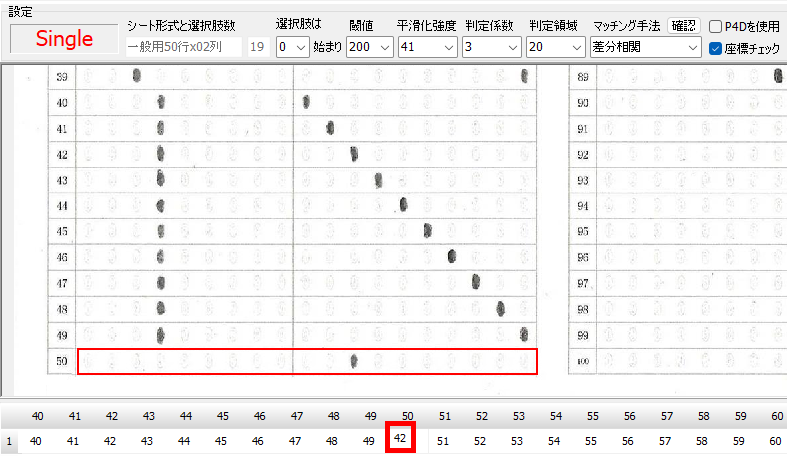
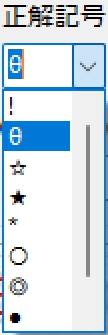
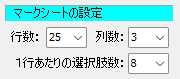
1列あたりの行数・全列数・選択肢の形式と選択肢数を「行・列・選択肢」順に並べています。 R は Row (=行)、すなわち1列 25 行より成ること、 C は Column (=列)、すなわち4列あること、 D は Double 型、すなわち複数マーク対応で、1行あたりの選択肢数は 19 個。 (ここが S の場合は Single 型、複数マーク不可)
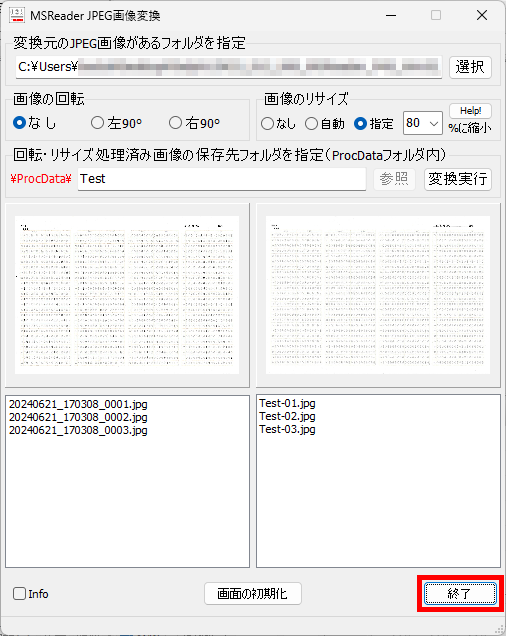
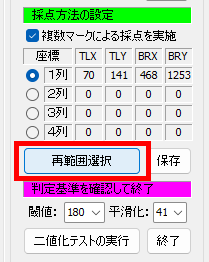
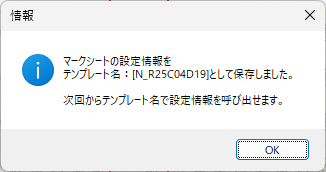
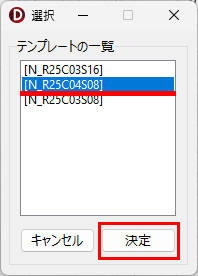
Word や Excel で作成したマークシートを、同じインクジェットプリンタで印刷して使用しているので、試験を実施する度にテンプレートを登録する必要はないはずなのですが、筆者はなんとなく不安で、毎回新しくテンプレートを登録し直して作業しています・・・
対策として、『選択肢番号の外枠の楕円「0」部分をはみ出さないようにマークする』よう注意を徹底することをお願いしたのですが、それだけでは根本的な解決とならないように感じ、マークとマークの間隔が狭いためにこの問題が起きていることは明白ですから、1設問について100選択肢に対応を維持しつつ、1列25行×4列で100設問まで対応という現在のマークシート構成を見直し(マーク間の幅を広げるため列数を減らし)、1列33行×3列で99設問まで対応可能というマークシートを作成しました。また、50分という試験時間を考えると80設問あれば十分というご意見も頂戴しましたので、1列30行×3列で90設問まで対応可能なマークシートや、1列25行×3列で75設問まで対応可能なマークシートを作成し、これらのマークシートを1つの Excel Book にまとめました。以下のリンクからダウンロードできます。
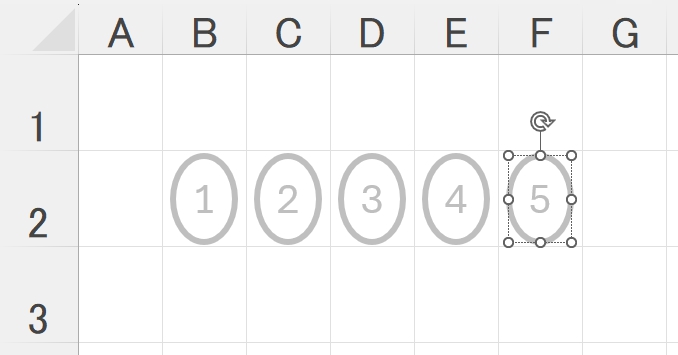
これまでのマークシートは Word で作成していたので、今回も Word を利用。・・・と言うか、本当は印刷設定の自由度が大きい Excel を使いたいのだが、Excel で縦楕円の丸囲み数字を上手に作成する方法がわからない。そこで縦楕円の丸囲み数字が簡単に作成できる Word を利用した・・・というのが正直なところ。
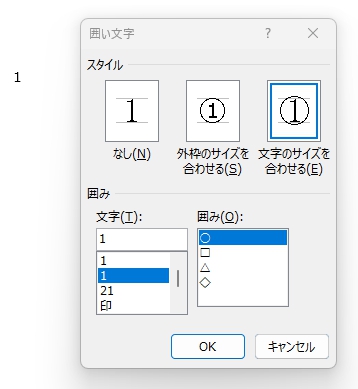
ちなみに Word で縦楕円の丸囲み数字(=「囲い文字」というらしい)を作成する方法は・・・
Word なら、Font は「メイリオ」を選択(フォントサイズを大きくしない場合)、丸囲みしたい数字を半角で入力、入力した数字をマウスでドラッグして選択してから、フォントリボンの「囲い文字」アイコンをクリックすると・・・
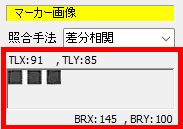
//複数マークの読み取り方法
if (Copy(strMS_Type,10,2)='19') and (chk_MultipleMarks.Checked) then
begin
//選択肢数が19で、複数マーク許可であった場合
StrList.Add(' var1.Value = str(res)');
end else begin
//複数マークは不許可であった場合
StrList.Add(' var1.Value = "99"');
end;
Python側で読み取った値をDelphi側で処理する部分も変更(一部を抜粋)。
//選択肢の始まりは「ゼロ」
if (Copy(strMS_Type,10,2)='19') and (chk_MultipleMarks.Checked) then
begin
//複数マークに対応
//strAnsList[intSG_k]の文字数を調査
strCount:=ElementToCharLen(strAnsList[intSG_k],Length(strAnsList[intSG_k]));
//チェック内容は、以下の通り
{
文字数が2文字の場合、末尾の1文字を取得する
10 -> 0
11 -> 1
19 -> 9
末尾1文字がマークした選択肢の番号になる
文字数が5文字の場合、
1 10 -> 2文字目が1、末尾2文字が10 -> 10
2 11 -> 2文字目が2、末尾2文字が11 -> 21
3 12 -> 2文字目が3、末尾2文字が12 -> 32
(2文字目×10)+(末尾2文字 - 10)がマークした選択肢の番号になる
}
case strCount of
2:begin
//2文字の場合は、末尾1文字が選択した選択肢の番号
StringGrid1.Cells[intSG_Col,intSG_Row]:=RightStr(strAnsList[intSG_k],1);
end;
3:begin
//空欄と判定された場合
if strAnsList[intSG_k]='999' then
begin
StringGrid1.Cells[intSG_Col,intSG_Row]:=strAnsList[intSG_k];
end;
end;
5:begin
//(2文字目×10)+(末尾2文字 - 10)がマークした選択肢の番号
StringGrid1.Cells[intSG_Col,intSG_Row]:=IntToStr(
(StrToInt(Copy(strAnsList[intSG_k],2,1)) * 10) +
(StrToInt(RightStr(strAnsList[intSG_k],2))) - 10);
end;
end;
end else begin
//1行につき選択肢数分Loopする_複数選択肢に対応(New)_20240614
if (Copy(strMS_Type,10,2)='19') and (chk_MultipleMarks.Checked) then
begin
//複数選択可能な場合_選択肢の数だけLoopする
for p := 0 to intCol-1 do
begin
//対象値pが平均値の3倍より大きいか、どうかでマークありと判定
if AryVal[p]>dblAvg * intKeisu then
begin
//マークありとした判定の数を記録
q:=q+1;
//マークした番号(記号)を記録
//intMark:=p+1;
//10の位(0-8)
case p of
0:strMark_A:='1';
1:strMark_A:='2';
2:strMark_A:='3';
3:strMark_A:='4';
4:strMark_A:='5';
5:strMark_A:='6';
6:strMark_A:='7';
7:strMark_A:='8';
8:strMark_A:='9';
end;
//1の位
case p of
9:strMark_B:='0';
10:strMark_B:='1';
11:strMark_B:='2';
12:strMark_B:='3';
13:strMark_B:='4';
14:strMark_B:='5';
15:strMark_B:='6';
16:strMark_B:='7';
17:strMark_B:='8';
18:strMark_B:='9';
end;
end;
end;
//Loop終了時にマーク数を判定
if q=0 then
begin
//マークした番号がない場合
iArr[i,Rep]:=999;
end else begin
//マークした番号があり、それが一の位である場合
if (q=1) and (strMark_A='') then
begin
//マーク数が1、かつ十の位が空欄であったら
iArr[i,Rep]:=StrToInt(strMark_B);
end else begin
//マーク数は1だが、それが十の位であったら
iArr[i,Rep]:=100;
end;
if (q=2) and (strMark_A<>'') and (strMark_B<>'') then
begin
//マーク数が2、かつ十の位と一の位がともに空欄でなかったら
strMark:=strMark_A+strMark_B;
iArr[i,Rep]:=StrToInt(strMark);
end;
if q>2 then
begin
//トリプル以上のマーク数を見分けるフラグは100
iArr[i,Rep]:=100;
end;
end;
end else begin
//選択肢の始まりは「ゼロ」(1の位を基準)
if (Copy(strMS_Type,10,2)='19') and (chk_MultipleMarks.Checked) then
begin
//strAnsList[intSG_k]の文字数を調査
strCount:=ElementToCharLen(strAnsList[intSG_k],Length(strAnsList[intSG_k]));
//チェック内容は、以下の通り
{
文字数が2文字の場合、末尾の1文字を取得する
10 -> 0
11 -> 1
19 -> 9
末尾1文字がマークした選択肢の番号になる
文字数が5文字の場合、
1 10 -> 2文字目が1、末尾2文字が10 -> 10
2 11 -> 2文字目が2、末尾2文字が11 -> 21
3 12 -> 2文字目が3、末尾2文字が12 -> 32
(2文字目×10)+(末尾2文字 - 10)がマークした選択肢の番号になる
}
case strCount of
1:begin
if StrToInt(strAnsList[intSG_k])<10 then
begin
StringGrid1.Cells[intSG_Col,intSG_Row]:='100';
end;
end;
2:begin
//2文字の場合は、末尾1文字が選択した選択肢の番号
StringGrid1.Cells[intSG_Col,intSG_Row]:=RightStr(strAnsList[intSG_k],1);
end;
3:begin
//空欄と判定された場合
if strAnsList[intSG_k]='999' then
begin
StringGrid1.Cells[intSG_Col,intSG_Row]:=strAnsList[intSG_k];
end;
//3文字と判定された場合、十の位の1~9のダブルマークの場合、
//2文字目は必ず半角の空欄になる
if Copy(strAnsList[intSG_k],2,1)=' ' then
begin
StringGrid1.Cells[intSG_Col,intSG_Row]:='999';
end;
end;
5:begin
//文字列の置き換え(先頭2文字を抽出&半角スペースを削除する)
strData:=StringReplace(Copy(strAnsList[intSG_k],1,2),
' ', '', [rfReplaceAll, rfIgnoreCase]);
//Case 5で先頭2文字が10である場合はダブル以上のマークあり
if StrToInt(strData) > 9 then
begin
StringGrid1.Cells[intSG_Col,intSG_Row]:='999';
end else begin
//2文字目が半角スペースでなければ処理可能
if Copy(strAnsList[intSG_k],2,1)=' ' then
begin
StringGrid1.Cells[intSG_Col,intSG_Row]:='999';
end else begin
//(2文字目×10)+(末尾2文字 - 10)がマークした選択肢の番号
StringGrid1.Cells[intSG_Col,intSG_Row]:=IntToStr(
(StrToInt(Copy(strAnsList[intSG_k],2,1)) * 10) +
(StrToInt(RightStr(strAnsList[intSG_k],2))) - 10);
end;
end;
end;
6..99:begin
StringGrid1.Cells[intSG_Col,intSG_Row]:='999';
end;
end;
end else begin
//複数選択を許可しないマークシートの処理
end;
end;
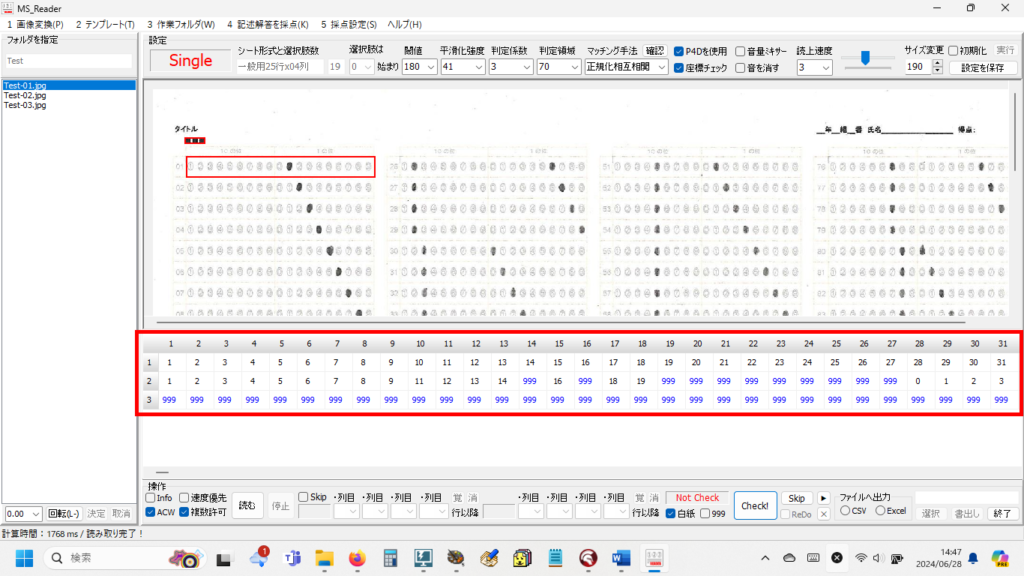
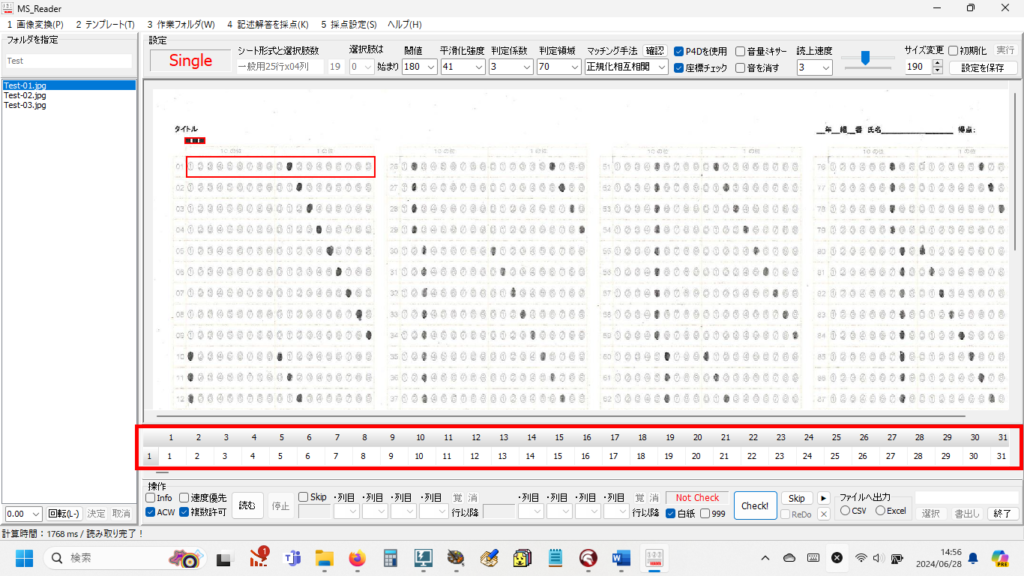
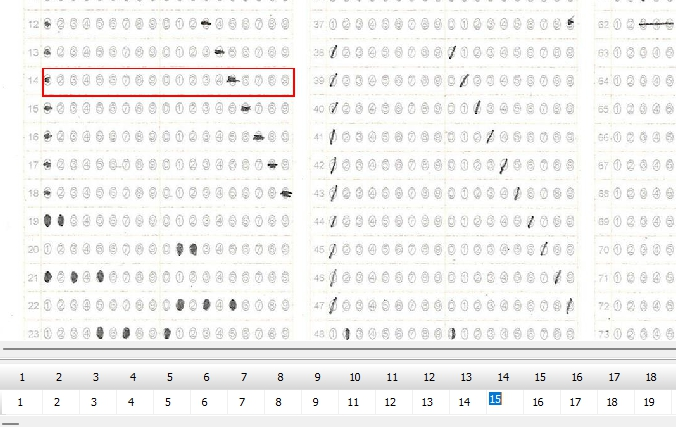
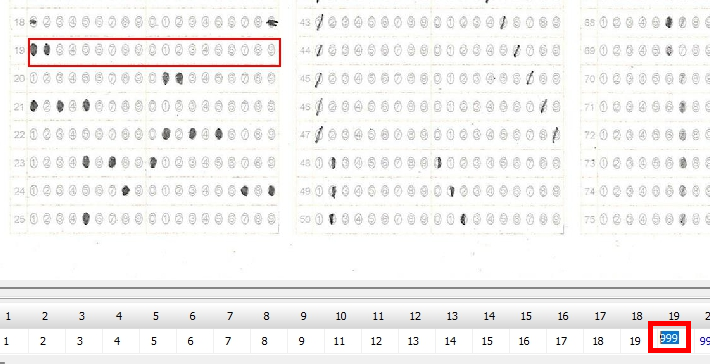
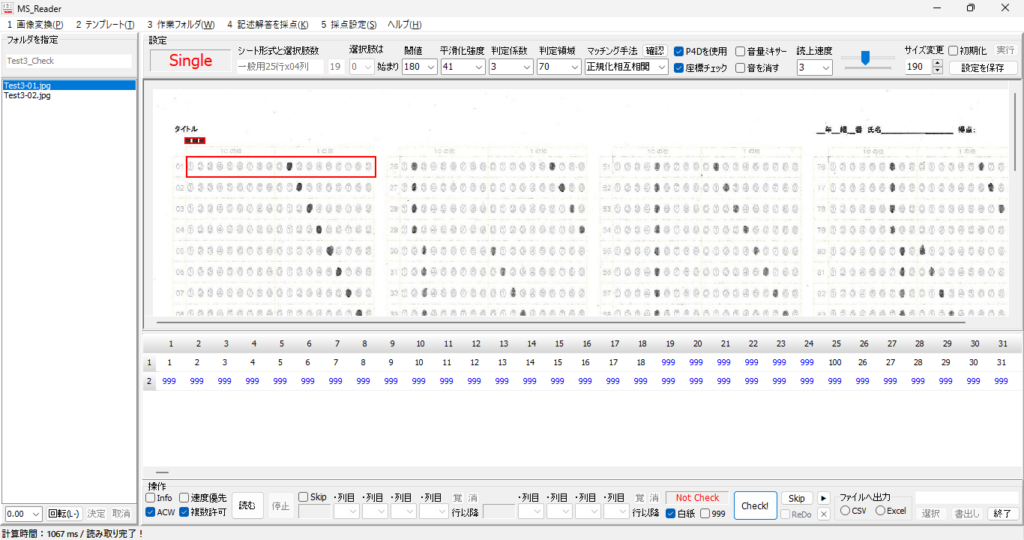
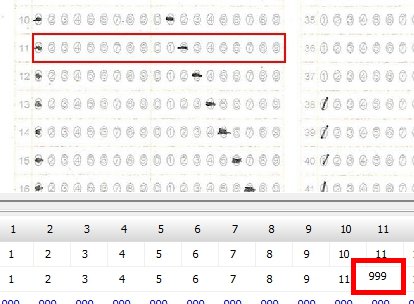
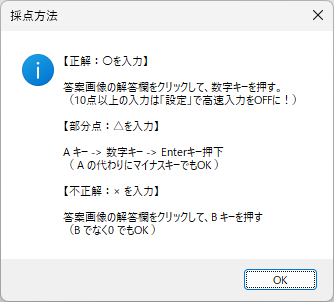
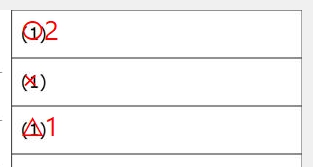
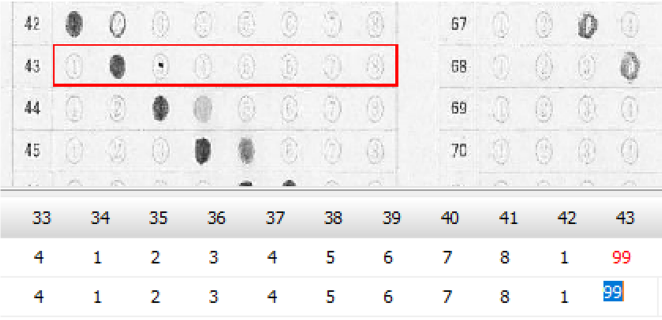
この際、読み取りエラーをすべて「999」で処理すれば、これまでの経験から、読み取り結果のチェックプログラムは確実に「空欄」=「999」位置を教えてくれるし、もし、それが本当に「空欄」である場合は、人が見ればそれは一目瞭然、もし、それが空欄でない場合は、それを見た「人」に、マークの有無 or 空欄 or その他複数マークの判断を委ねればいい。そしてもし、「人」が見て、マークが正しければプログラムの判定結果を正しく修正、そうでなく、マークが「空欄でない」・「必要数以上にマークされていた」場合は、そのまま「空欄として処理(999)」してもらえば、採点結果には一切影響を与えないはずだ。
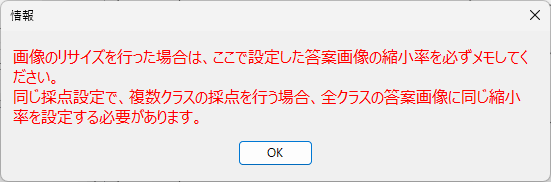
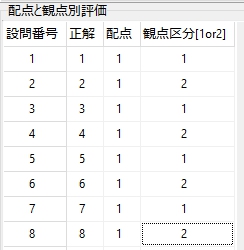
また、派生版であるため、プログラムには Excel Book に読み取り結果を出力する機能がありますが、大語群に対応した採点結果通知作成用の Excel ファイルは、Zipファイルを展開後、 eFile フォルダ内にあるテンプレートから生成できる Excel ファイルをマクロ有効な Excel Book として保存し、これを元にご自身で作成していただく必要があります。※ Zip ファイルに添付した Excel Book は、大語群マークシートに対応しておりません。
procedure TForm1.ButtonExitClick(Sender: TObject);
var
hWndPSWindow: HWND;
begin
//PowerShellを閉じる
hWndPSWindow:=FindWindow(nil, PChar('Windows PowerShell'));
if hWndPSWindow <> 0 then
begin
SetForegroundWindow(hWndPSWindow);
//文字列の送信
SendKeys('Exit');
//Enterキーの送信
SendKeys(#13#10);
end else begin
ShowMessage('PowerShellのウィンドウが見つかりません!');
end;
end;
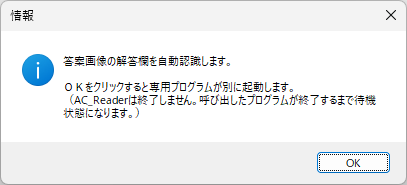
当Blogで紹介してきた自作のデジタル採点プログラムを一つにまとめました。次のリンク先にその紹介とダウンロードリンクがあります。この記事で紹介している手書き答案のデジタル採点プログラムAC_Reader Version 2.1.1 と、AC_Reader Version 2.1.1 に自動採点機能を追加で搭載した Version 3.1.1 がプログラムセットに同梱されています。
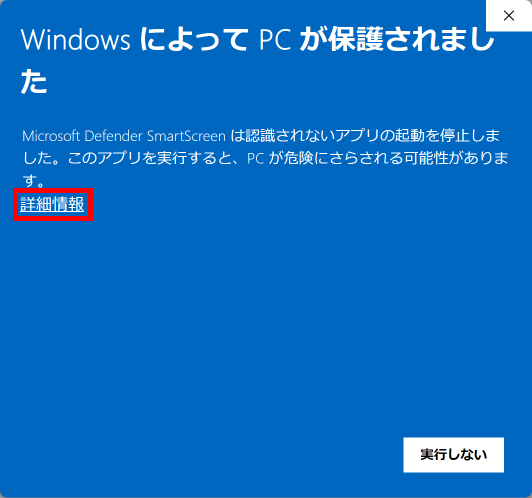
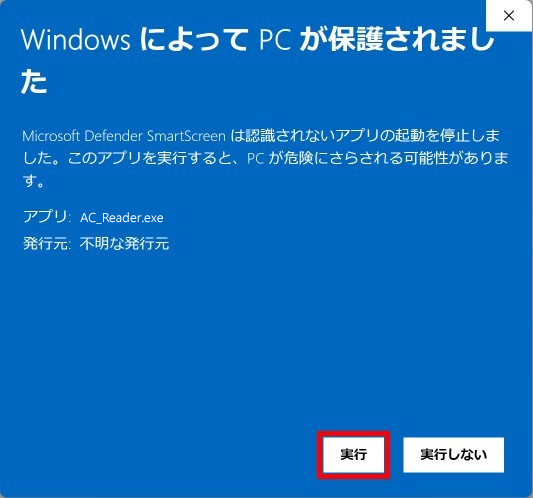
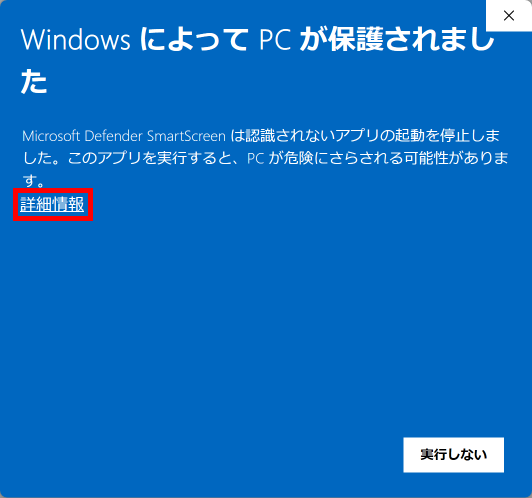
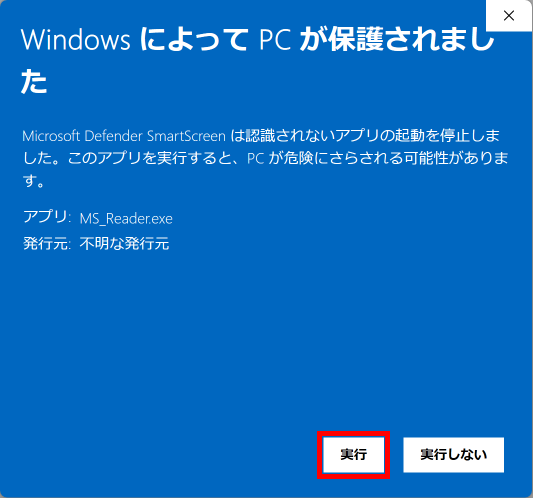
2025年8月25日更新版に含まれている「手書き答案採点補助プログラム AC_Reader Version 3.1.0 )には自動採点機能が新しく追加で搭載されています。プログラムのダウンロード&展開後、初めてこの自動採点機能を実行する際に、Windows Defender や McAfee などの Anti-Virus Software : AV による『未知バイナリの初回スキャン』が行われるようです。このため2~3分間程度 PC は待機状態になります(2回目以降はスムース?に動作します)。また、実行形式ファイルの PC 内での位置が変わった場合にも AV によっては再度『未知バイナリの初回スキャン』が行われ、初回同様の待機状態となる場合があります。このことについては、この Blog の別の記事に詳しい説明があります。下記リンク先の記事をご参照ください。
するとPDFiumというライブラリがあるとCopilotさんが教えてくれました。ただ、紹介されたのは「PDFium Component Suite for FireMonkey」だったので、どちらかというとWindows専用にVCLコンポーネントを使ってプログラムを書きたい自分的には(FireMonkeyはちょっと・・・)という感じだったのですが・・・、「溺れる者は藁をもつかむ」と、まさにそんな気持ちでありましたから・・・記事に目を通してみることに。
Swanman (id:tales)さんのBlogの記事に紹介されていた Windows Runtime(略称がWinRT)なるものの存在を、これまで僕は知りませんでした。Win32 API なら名前だけは知ってましたが、どうやらそれより新しいAPI であるとのこと。難しいことはわかりませんが、このWinRTでPDFの画像化ができるのであれば、Windowsの機能を使ってそれが実現できるのですから、新規に何かライブラリを追加したりする必要がなく、それこそ理想的です。
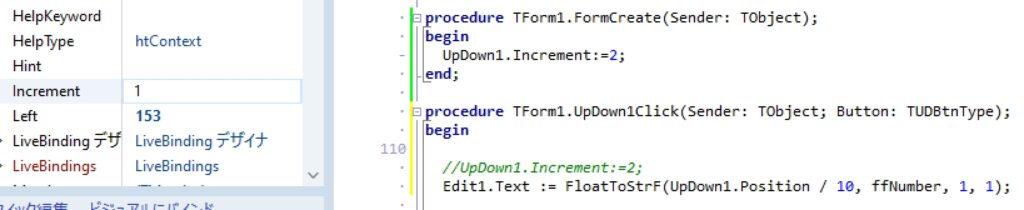
procedure TForm1.UpDown1Click(Sender: TObject; Button: TUDBtnType);
var
Value: Real;
begin
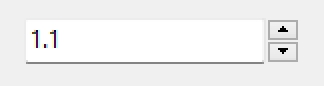
//注意:このコードは、期待通りに動作しません
Value := StrToFloatDef(Edit1.Text, 0);
case Button of
btNext: Value := Value + 0.1;
btPrev: Value := Value - 0.1;
end;
Edit1.Text := FloatToStrF(Value, ffNumber, 1, 1);
end;
procedure TForm1.Button1Click(Sender: TObject);
var
Value: Double;
begin
if TryStrToFloat(Edit2.Text, Value) then
begin
Value := Value + 0.1;
Edit2.Text := FloatToStr(Value);
end
else
ShowMessage('Invalid number');
end;
procedure TForm1.Button2Click(Sender: TObject);
var
Value: Double;
begin
if TryStrToFloat(Edit2.Text, Value) then
begin
Value := Value - 0.1;
Edit2.Text := FloatToStr(Value);
end
else
ShowMessage('Invalid number');
end;
var
Value: Double;
Epsilon: Double;
begin
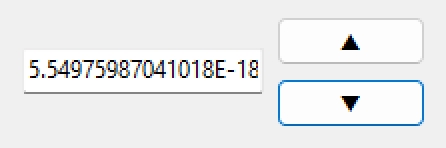
Epsilon := 1E-15; //閾値を設定
Value := SomeCalculation(); //計算を実行
if Abs(Value) < Epsilon then
Value := 0;
Edit1.Text := FloatToStr(Value);
end;
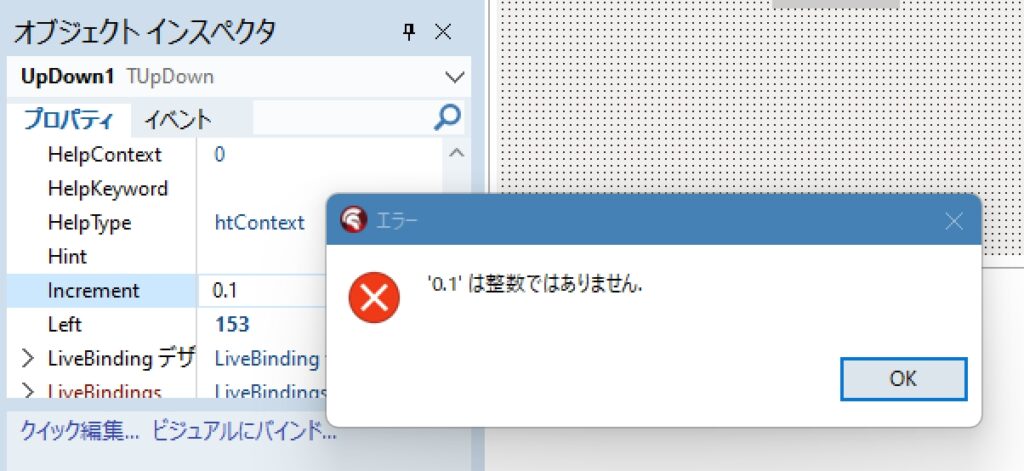
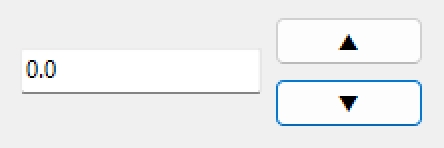
4.コードを修正
Copilotさんが教えてくれたコードを読んで、「0.0」と表示されるように修正しました。
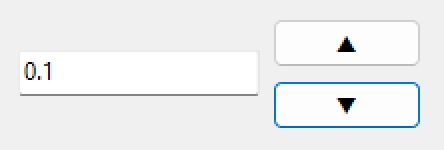
procedure TForm1.Button3Click(Sender: TObject);
var
Value: Double;
Epsilon: Double;
begin
Epsilon := 1E-15; //閾値を設定
if TryStrToFloat(Edit3.Text, Value) then
begin
Value := Value + 0.1;
if Abs(Value) < Epsilon then
begin
Value := 0;
Edit3.Text := '0.0';
end else begin
Edit3.Text := FloatToStr(Value);
end;
end;
end;
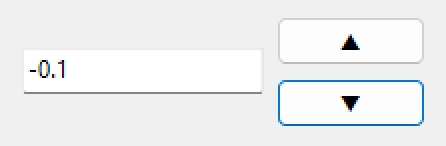
procedure TForm1.Button4Click(Sender: TObject);
var
Value: Double;
Epsilon: Double;
begin
Epsilon := 1E-15; //閾値を設定
if TryStrToFloat(Edit3.Text, Value) then
begin
Value := Value - 0.1;
if Abs(Value) < Epsilon then
begin
Value := 0;
Edit3.Text := '0.0';
end else begin
Edit3.Text := FloatToStr(Value);
end;
end;
end;
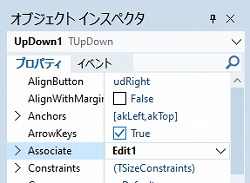
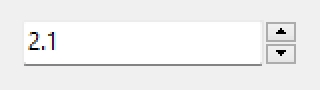
procedure TForm1.UpDown1Click(Sender: TObject; Button: TUDBtnType);
begin
Assert(Sender is TUpDown);
with TUpDown(Sender) do
begin
Assert(Associate is TEdit);
TEdit(Associate).Text := FloatToStrF(Position / 10, ffNumber, 1, 1);
end;
end;
procedure TFormXXX.PanelXStartDock(Sender: TObject;
var DragObject: TDragDockObject);
begin
DragObject:= TToolDockObject.Create(Sender as TPanel);
end;
procedure TFormXXX.PanelXStartDock(Sender: TObject;
var DragObject: TDragDockObject);
begin
//これでちらつかなくなった
DragObject:= TToolDockObject.Create(Sender as TPanel);
//設定し忘れないための予防的措置
if not FormXXX.DockSite then
begin
FormXXX.DockSite:=True;
end;
end;
ドロップ時のOnDockDropイベントは・・・
procedure TFormXXX.FormDockDrop(Sender: TObject;
Source: TDragDockObject; X, Y: Integer);
var
r:TRect;
begin
if IsDragObject(Source) then
begin
r.Left:=X;
r.Top:=Y;
r.Right:=X+PanelX.Width;
r.Bottom:=Y+PanelX.Height;
PanelX.ManualFloat(r);
//解放
Source.Free;
if FormXXX.DockSite then
begin
FormXXX.DockSite:=False;
end;
end;
end;
procedure TFormCollaboration.PanelXStartDock(Sender: TObject;
var DragObject: TDragDockObject);
begin
DragObject:= TToolDockObject.Create(Sender as TPanel);
try
if not FormXXX.DockSite then
begin
FormXXX.DockSite:=True;
Application.ProcessMessages; //おまじない
end;
finally
DragObject.Free; //メモリの解放
end;
FormXXX.DockSite:=False;
end;
DragObject:= TToolDockObject.Create(Sender as TPanel);
try
if not FormXXX.DockSite then
begin
FormXXX.DockSite:=True;
Application.ProcessMessages; //おまじない
end;
finally
DragObject.Free; //メモリの解放
end;
Microsoft Windows [Version 10.0.22631.3007]
(c) Microsoft Corporation. All rights reserved.
C:\Windows\System32>cd \
C:\>cd C:\Users\XXX\Downloads\ViVeTool-v0.3.3
C:\Users\XXX\Downloads\ViVeTool-v0.3.3>vivetool /query /id:41799415
ViVeTool v0.3.3 - Windows feature configuration tool
[41799415]
Priority : Service (4)
State : Enabled (2)
Type : Experiment (1)
C:\Users\XXX\Downloads\ViVeTool-v0.3.3>vivetool /disable /id:41799415
ViVeTool v0.3.3 - Windows feature configuration tool
Successfully set feature configuration(s)
C:\Users\XXX\Downloads\ViVeTool-v0.3.3>
上記リンク先でダウンロードできる「デジタル採点 All in One !」は、ここからダウンロードできる教科「情報」用マークシートも同梱しています。「デジタル採点 All in One !」には、マークシートリーダーの他、マークの読み取りを高速化するPython環境、手書き答案の採点プログラム、受験者に採点結果を通知する個票及び成績一覧表の作成プログラム、実際の採点現場で要請に応じて作成した各種のマークシート等を同梱しています。何の保証もサポートもありませんし、「All 自己責任でお願いします」という制約はありますが、すべて無料でお使いいただけます。
そうやって新しいマクロ有効Excel Bookを作成。これを入れる所定のフォルダを作り、保存。準備万端にして、新しい Windows VCLアプリケーションも作成。で、これまで勉強した中で、いちばん動作が確実と思えるコードで「ワークシート間で式をコピーする」手続きを作成、コンパイル、そして「実行」。期待通りに、エラーなく、データのコピー(読み出しと書き込み)終了。胸がすっきり。Bookを開いて結果を確認。データはちゃんと書き込まれ、ワークシートが初期化されてる。もちろん、Excelもきれいに終了。タスクマネージャーで確認してもプロセスは残ってない。
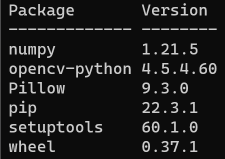
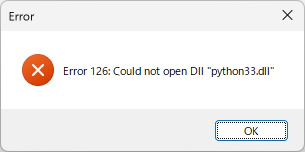
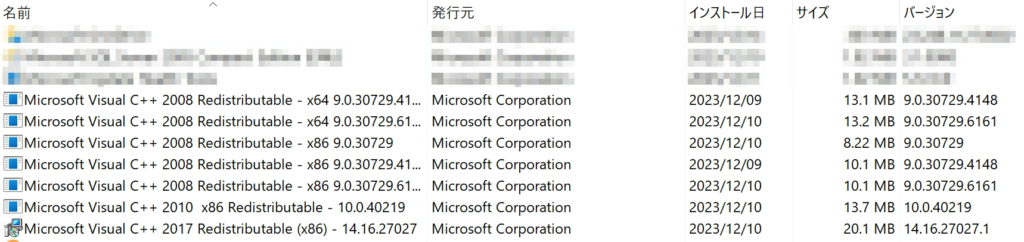
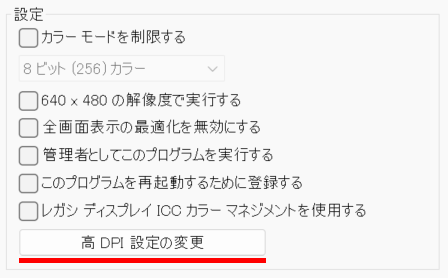
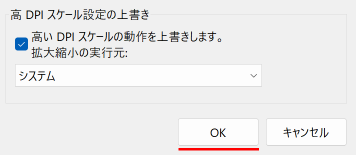
お使いのPCで、Visual C++ ランタイム ライブラリのインストール状況を確認するには、[スタート] ボタンを右クリックし、「ファイル名を指定して実行」をクリックして、appwiz.cpl と入力して[Enter]を押します。Python環境を組み込んだ MS_Reader が動作する環境であれば、システムにインストールされている Microsoft Visual C++ ランタイム ライブラリが以下のように表示されるはずです。
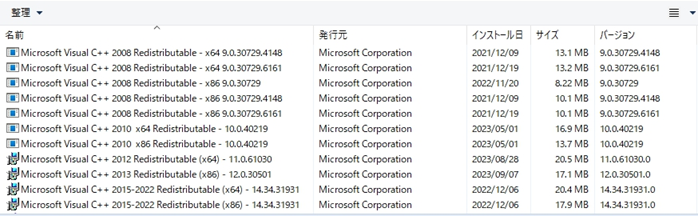
現在、私のシステム(Windows 11 Pro 23H2)にインストールされているC++ランタイムライブラリの一覧。 もちろん、このシステムでPython環境を組み込んだマークシートリーダーが正常に動作しています。
エラーを解決するには、Visual C++ランタイムライブラリをインストールすればいいわけですが、上の例のように Visual C++ ランタイムはたくさんあるので、手動でひとつひとつダウンロードしてインストールするより、Visual C++ ランタイムインストーラーを使って全ての Visual C++ ランタイムを一括インストールする方が簡単です。
システムをリカバリする前は、次のようにして Visual C++ ランタイムをインストールしていました。
【ご注意願います!】
ここで紹介する方法で Visual C++ ランタイムをインストールする場合、他のプログラムの実行環境との整合性は、一切保証できません。また、最悪の場合、Windowsが起動しなくなるトラブルが発生することも十分に考えられます。インストール作業の全てが自己責任であることを十分ご理解の上、重大な問題が発生した場合は元の環境に戻せるよう、システムのバックアップを取る・現在の設定をメモに記録する等、不具合の発生に備え、必要かつ十分な準備を整えた上で、Visual C++ ランタイムのインストールを行ってください。
以下のサイトから「Visual C++ v56.exe」をダウンロードしてインストール(私の環境にインストールする分には、なんの問題も起きませんでした。もちろん、マークシートリーダーも問題なく起動し、安定動作しました)。
ここから先は、上記のインストーラーを用いて Visual C++ ランタイムをインストールした際、私が実際に経験したトラブル?です(最終的にインストールは成功しました)。
お決まりのUAC起動後(PCの設定によっては)管理者ID 及びパスワードの入力が求められますが、これを入力すると、そのままPCがフリーズしたような状態になり、数分待機しても進展が見られないので、いったん作業を Ctrl+Alt+Delete でキャンセルし、再度、「Visual C++ v56.exe」を起動して Visual C++ ランタイムのインストール作業を実行、今度はトラブルなくインストールに成功する事例です。これは「ある特定のAD環境下にあるPCのすべてに共通して見られた」現象です。現在もその原因はわかりませんが、ご参考まで。
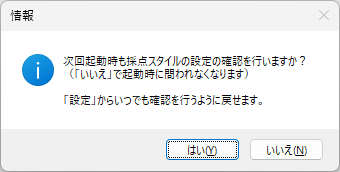
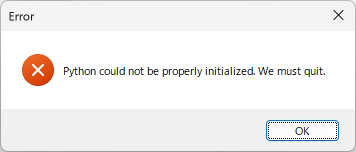
この初期化を「するか・しないか」で、MS_Reader 起動後、初めてマークを「読む」ボタンをクリックした際のプログラムの挙動がまるで違ったものになります。初期化を行った場合は、ごくスムーズにマーク読み取りが始まるのに対し、行わなかった場合は PC が一瞬フリーズしたような状態になり、その後、息を吹き返すかのようにマークの読み取りが始まります。
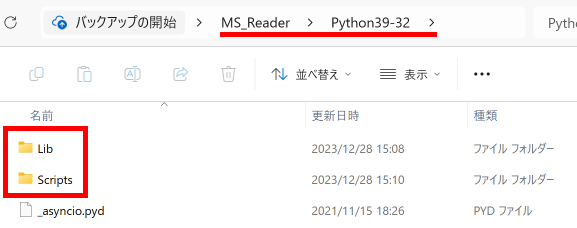
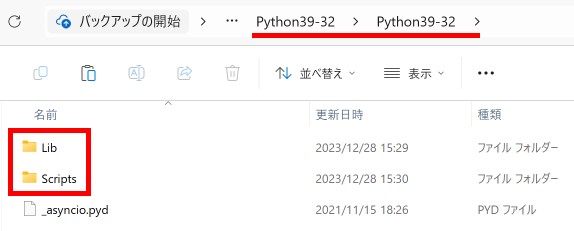
Python Engine の初期化コードです。
AppDataDir:=ExtractFilePath(Application.ExeName)+'Python39-32';
if DirectoryExists(AppDataDir) then
begin
//フォルダが存在したときの処理
CheckPython.Enabled:=True;
CheckPython.Checked:=True;
PythonEngine1.AutoLoad:=True;
PythonEngine1.IO:=PythonGUIInputOutput1;
PythonEngine1.DllPath:=AppDataDir;
PythonEngine1.SetPythonHome(PythonEngine1.DllPath);
PythonEngine1.LoadDll;
PythonDelphiVar1.Engine:=PythonEngine1;
PythonDelphiVar1.VarName:=AnsiString('var1');
PythonEngine1.Py_Initialize;
//イニシャライズされたことを記憶
P4D_ini:=True;
end else begin
CheckPython.Checked:=False;
CheckPython.Enabled:=False;
PythonEngine1.AutoLoad:=False;
P4D_ini:=False;
end;
(どこに問題があるのでしょうか?)
PC によっては、この Python Engine の初期化に非常に長い時間を要することがあるようです(エラーメッセージは出ません。この沈黙の時間が終わった後、プログラムは問題なく動作します)。偶然、ある PC でこの現象に巡り合い、あわてて時間を計ってみたところ、その PC では初期化に4分必要でした! なぜ、このような現象が発生するのか、その理由がわからないのですが、「そのようなことがある」ことだけは経験的に明らかですので、ここに書いておくことにしました。
Excel Book への読み取り結果の書き出しは、自分用に(あれば便利かなー☆)と思って作成したものです。ですので、式の入ったセルを保護する等、第三者が使うことへの配慮は何一つ行っていません。セルに入力された式やVBAの内容をご自身でメンテナンスできる方なら、お使いいだけるかな? という程度のシロモノです。
添付した Excel Book はこれまでに何度も「実際に使用して動作に誤りがないことを確認済み」ですが、誤って式を削除したりした場合は(当然ですが)意図した通りに動作しません。ですので、こちらも動作保証は一切ありません。ご使用はあくまでも自己責任でお願いします。この Excel Book に対しても、このプログラムの使用要件にあります免責事項がそのまま適用されますことを申し添えます。
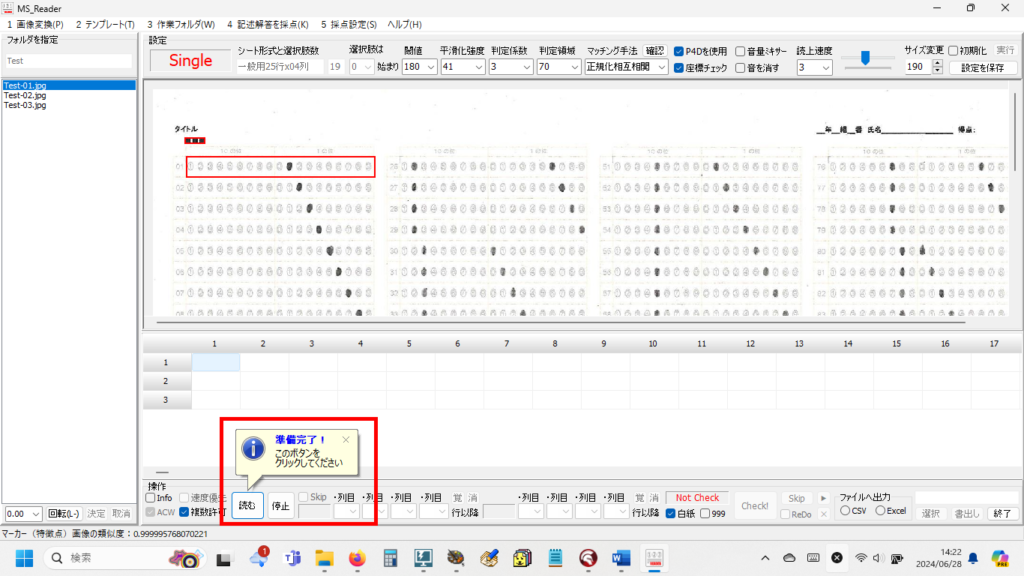
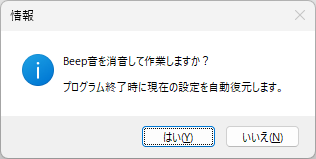
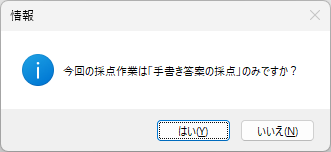
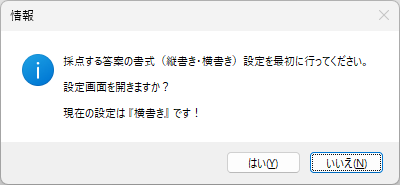
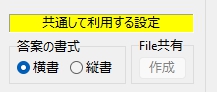
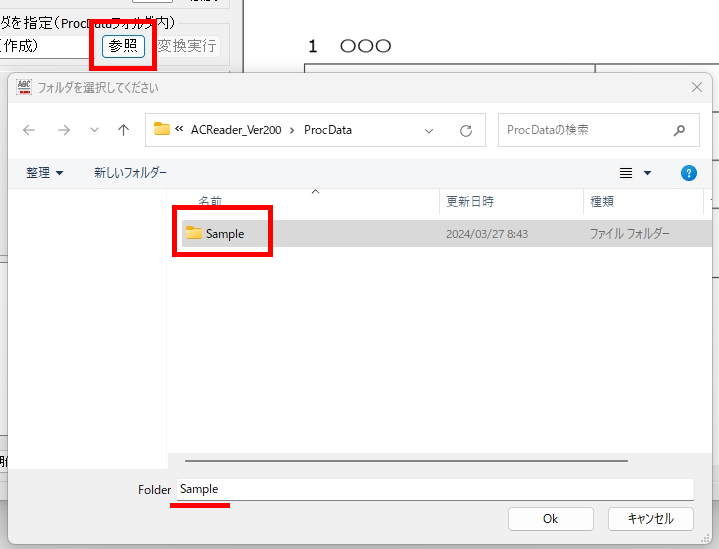
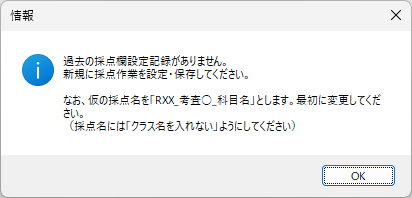
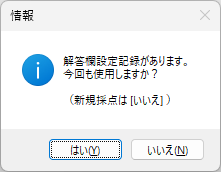
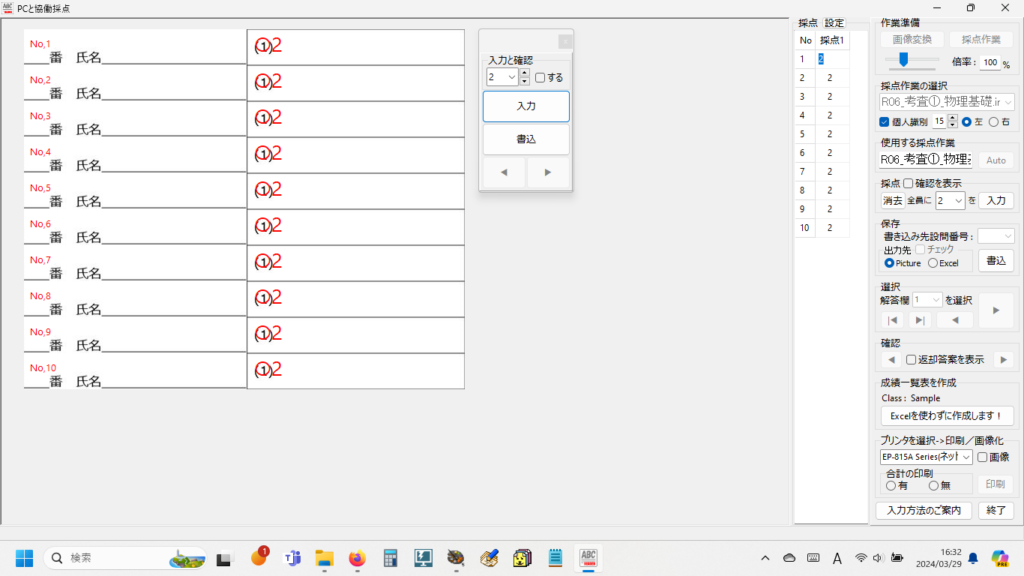
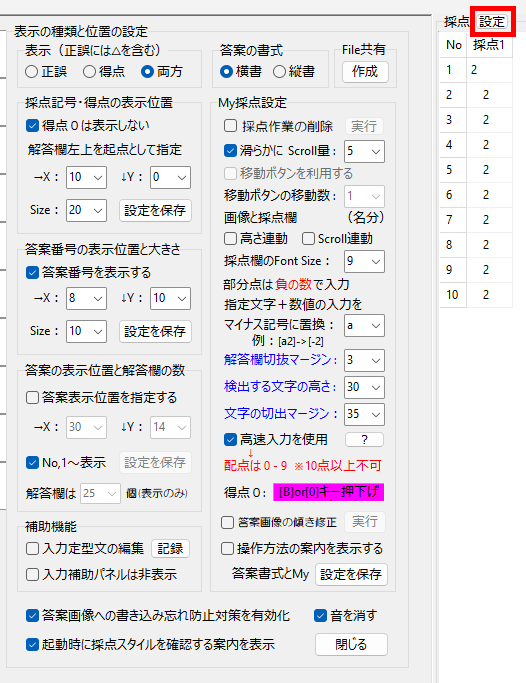
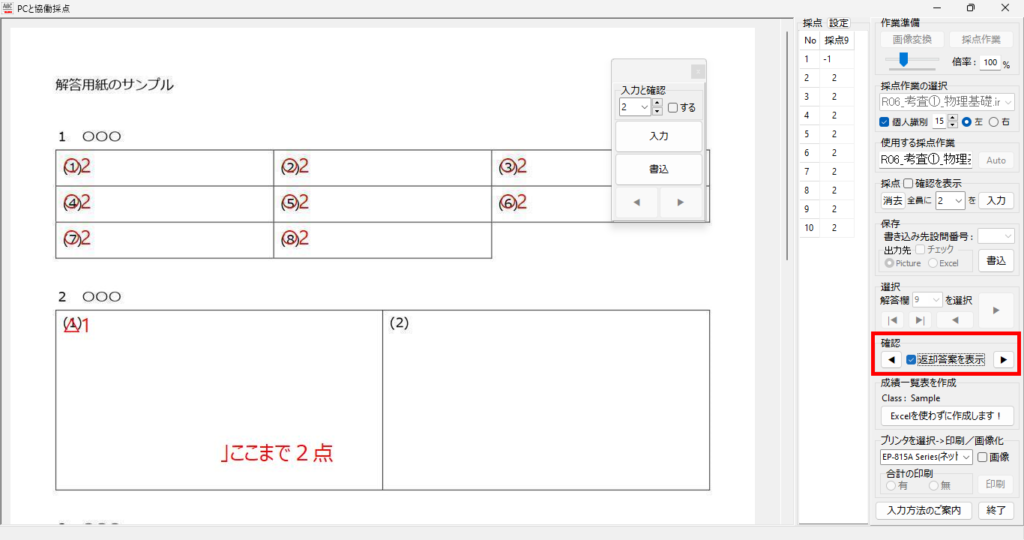
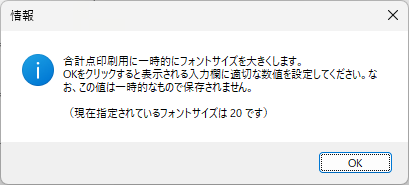
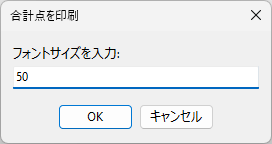
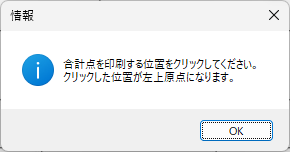
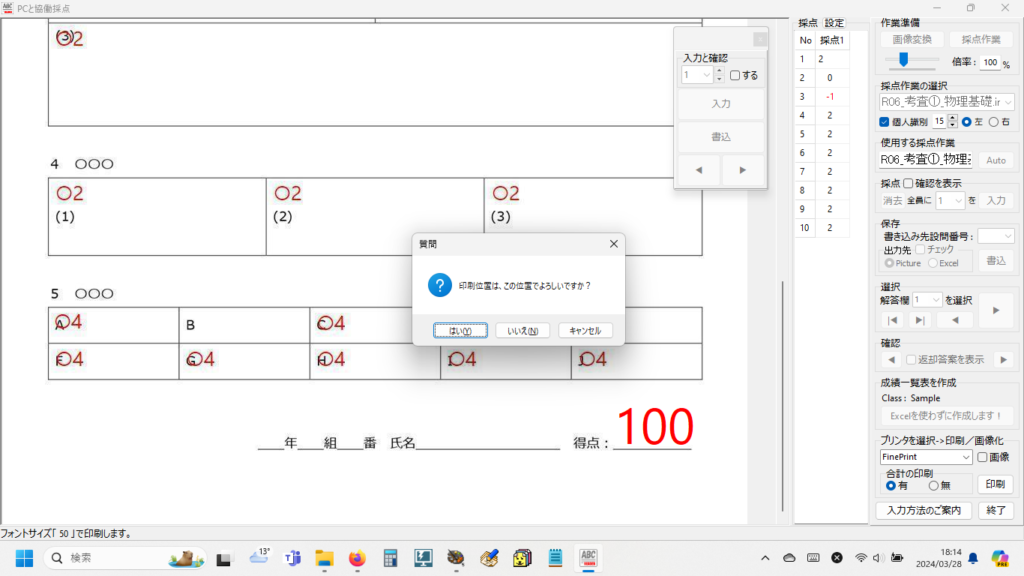
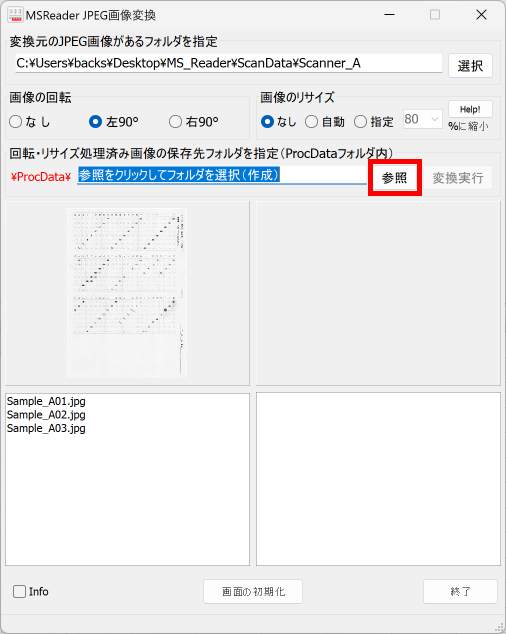
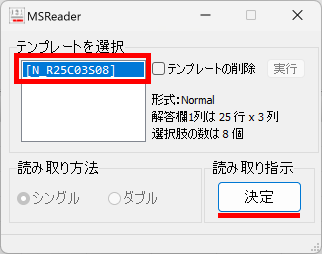
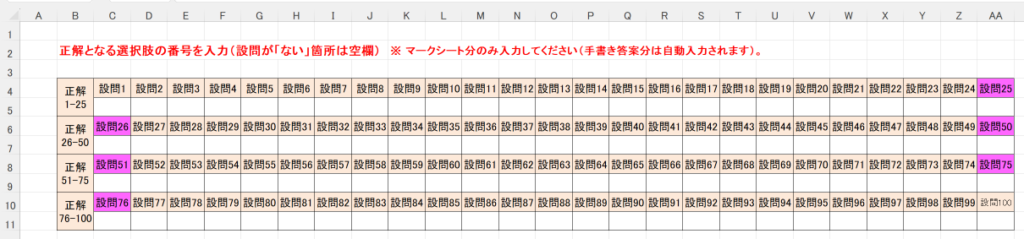
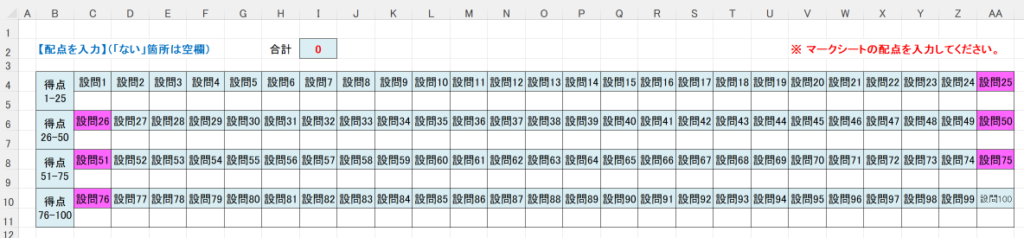
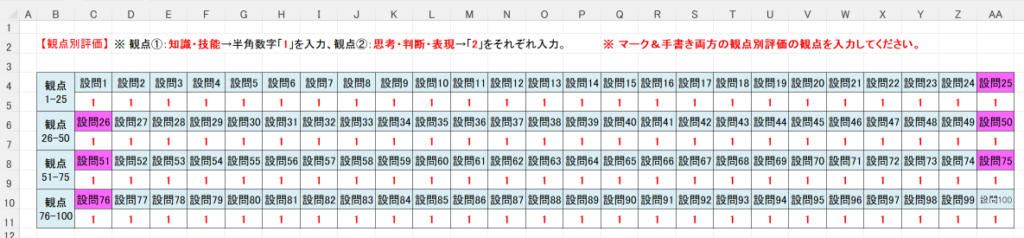
以下、試験実施前に行っておくとよい採点準備作業です。
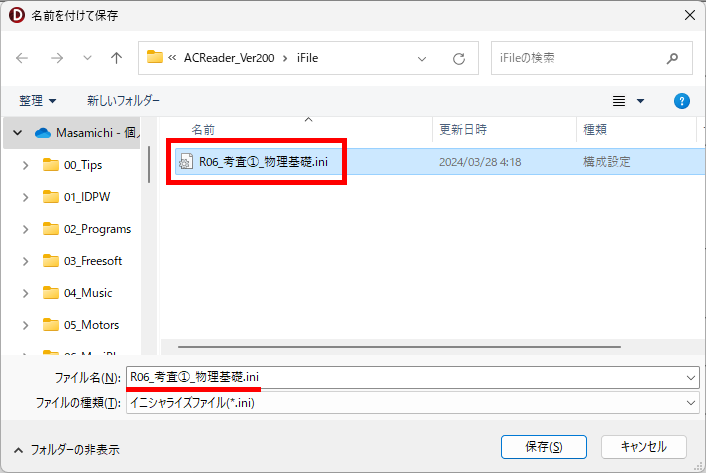
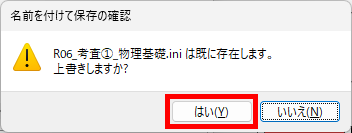
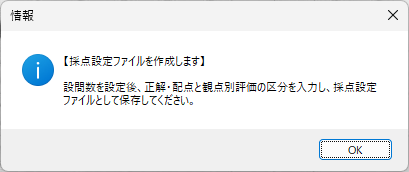
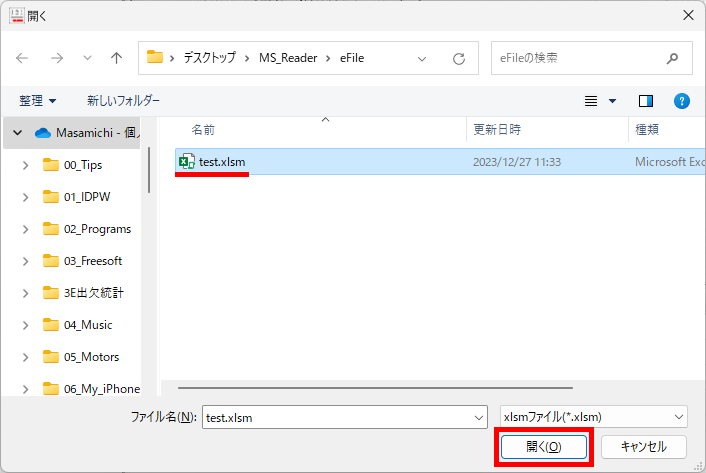
eFile フォルダに「一般用マークと手書き併用採点シート.xltm」というマクロ有効テンプレートがあります。これをダブルクリックすると「一般用マークと手書き併用採点シート1.xlsx」という名前で新しい Excel Book が作られます。拡張子に注意してください。「.xlsx」です。このままでは期待通りに動作しませんので、適切な名前を付け、拡張子を「.xlsm」(マクロが有効な Excel Book )に変更して eFile フォルダ(必ずこのフォルダに保存してください!)に保存します。
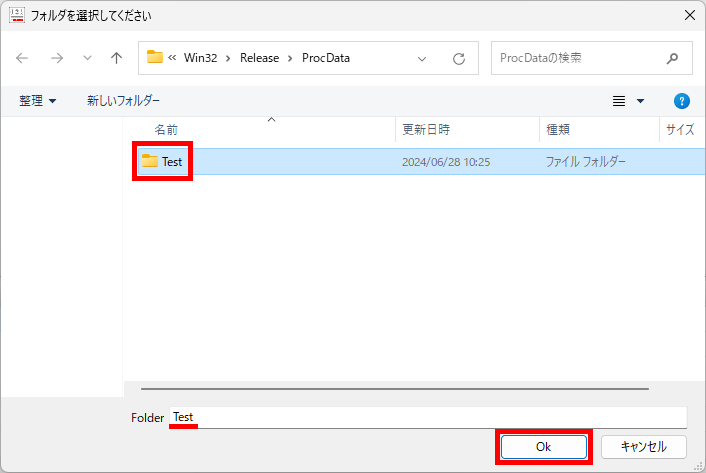
ここでは test.xlsm という名前で保存したことにして説明を続けます。
「コンテンツの有効化」をクリックしてマクロが実行できるようにしてください。
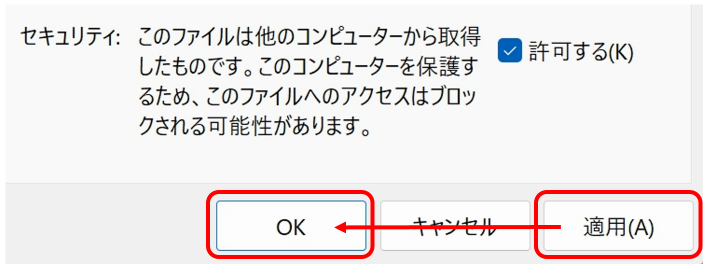
【インターネットからダウンロードしたマクロ有効 Excel Book の取り扱い】
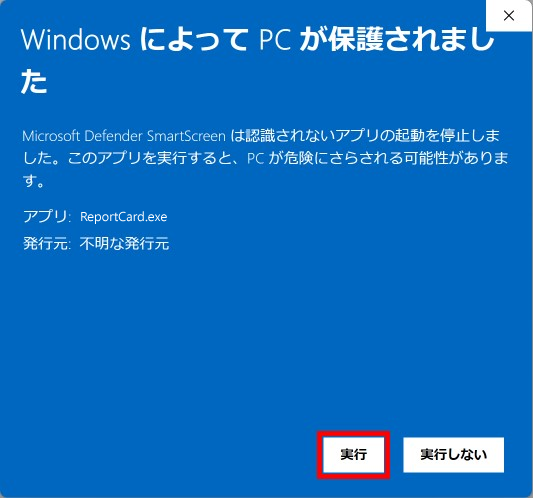
いつからこうなったのか、わかりませんが、インターネットからダウンロードした拡張子 xlsm の Excel Book をダブルクリックして開くと、次のメッセージが表示されるようになりました。
「編集を有効にする」をクリックすると・・・マクロを動かすことができません!
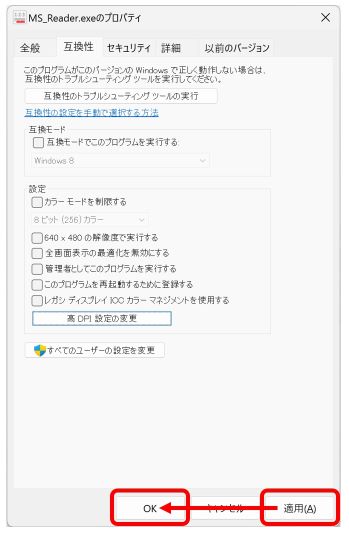
こうなった時は、いったん Book を閉じて、その Excel ファイルを右クリックして表示されるサブメニューのプロパティをクリックして、全般タブのいちばん下にある「セキュリティ:」の「許可する」にチェックします(チェックする=マクロの実行をご自身の責任で行うことになります。どうか、ご注意ください)。
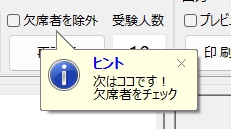
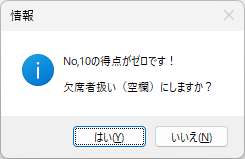
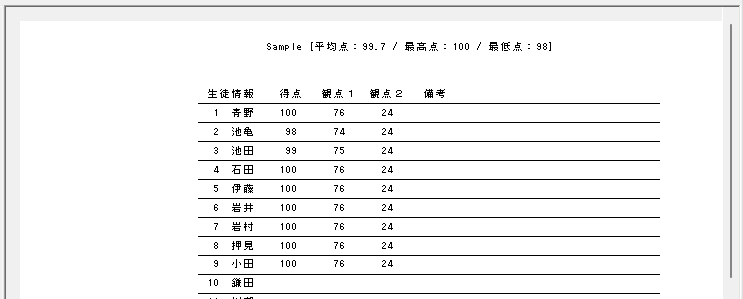
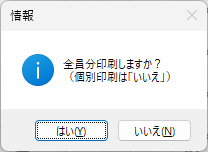
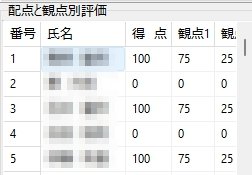
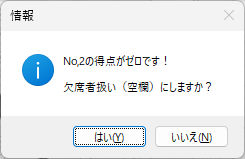
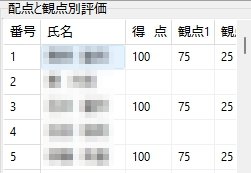
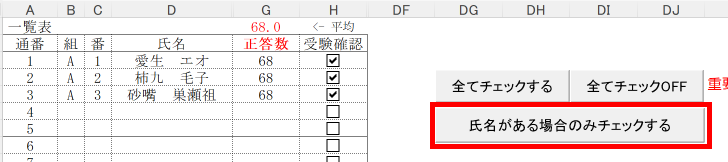
Excel Book を利用して採点する場合、大変重要な注意事項があります。それは欠席者がいた場合の処理です。該当試験に欠席者がいる場合は、その欠席者の出席番号位置に未使用のマークシートを挿入し、シートが確実に出席番号順に並んでいることを確認してから、スキャナーでスキャンしてください。 ※ 可能であれば、この用途専用に未使用のマークシートを複数枚、最初から手元に準備しておくとよいと思います。
Excel へデータを書き込む際は、上記注意事項を必ずお守りください。この注意を忘れて Excel が起動したまま、Excel Book への書き込みを実行すると最悪の場合、Excel のプロセスが幽霊のように残り、これを終了することが出来なくなって、復旧するには、システムの再起動しかない状態になります。未保存の重要なデータがあるような場合、当然そのデータは失われます。Excel Book へのデータ書き込み時は、Excel が起動していないことを(タスクバーに眠っている Excel Book がないことも含めて)十分確認した上で、書き込み作業を行ってください。
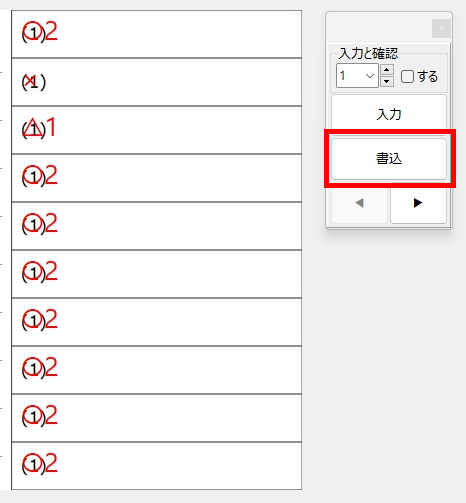
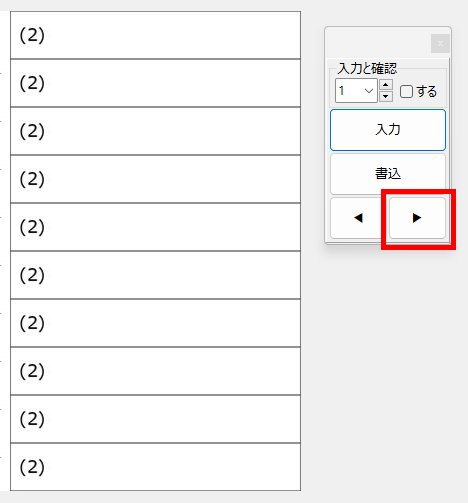
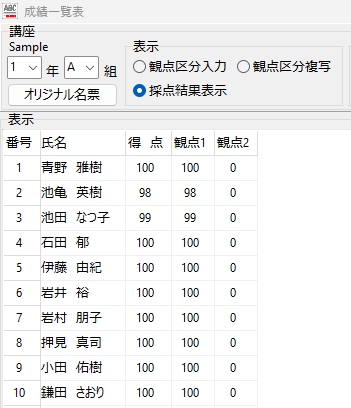
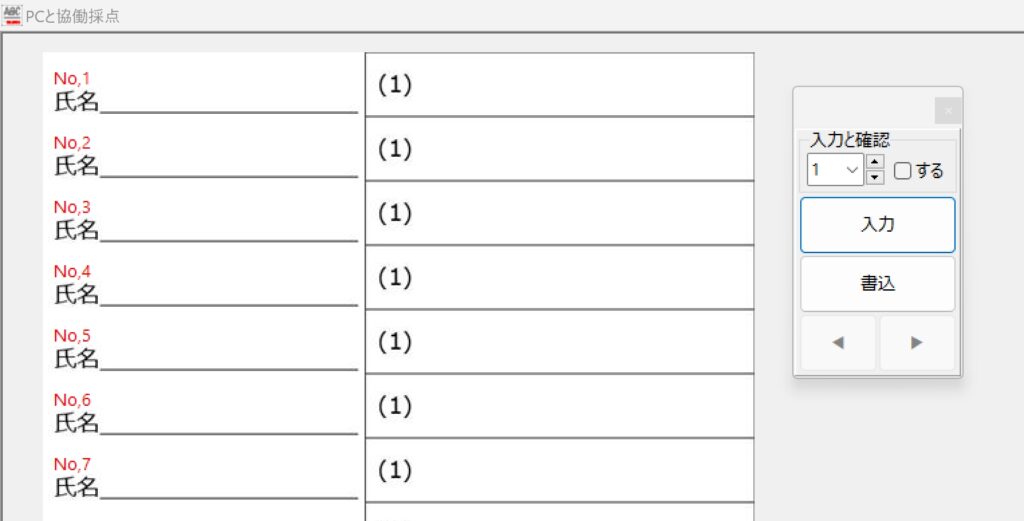
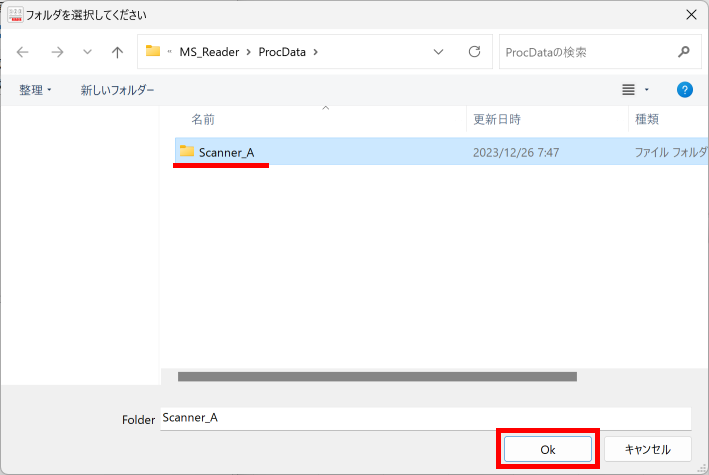
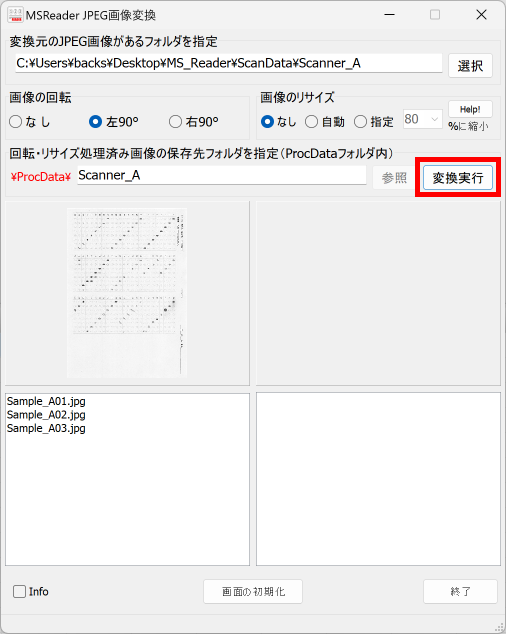
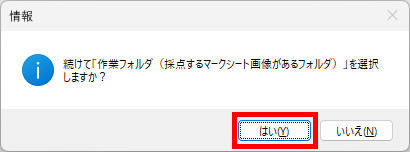
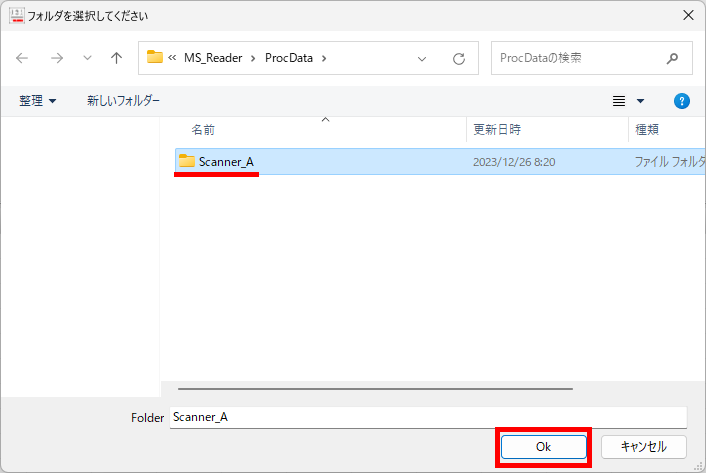
【書き出し処理】
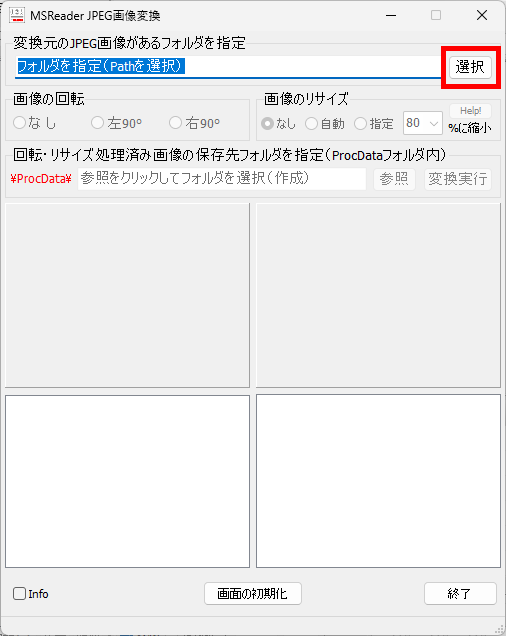
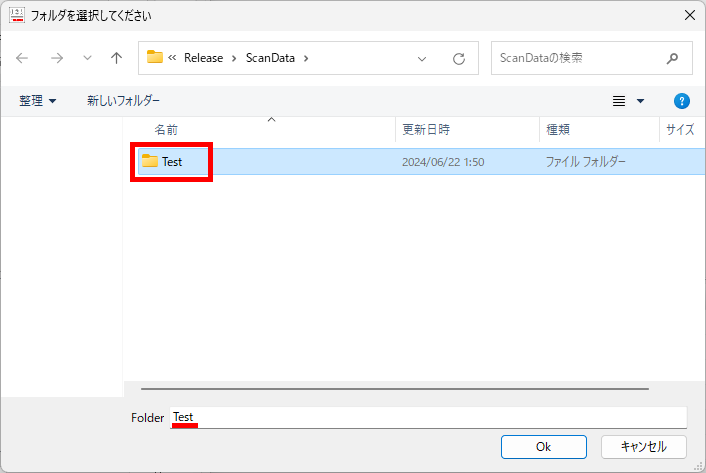
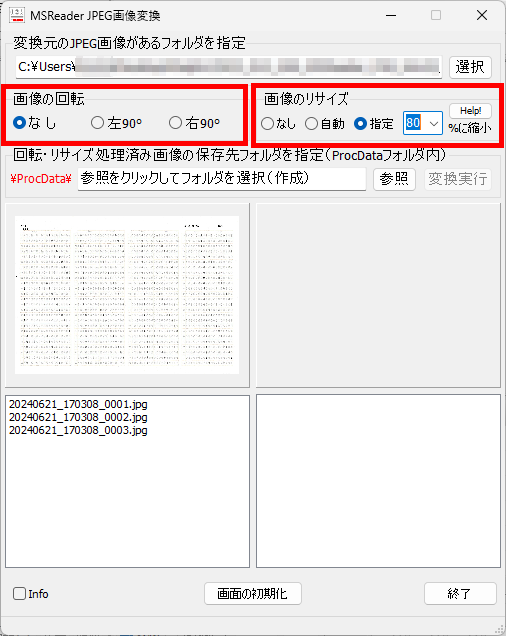
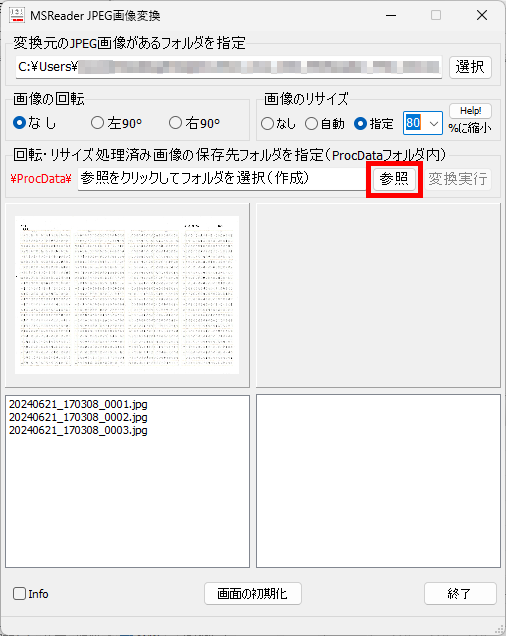
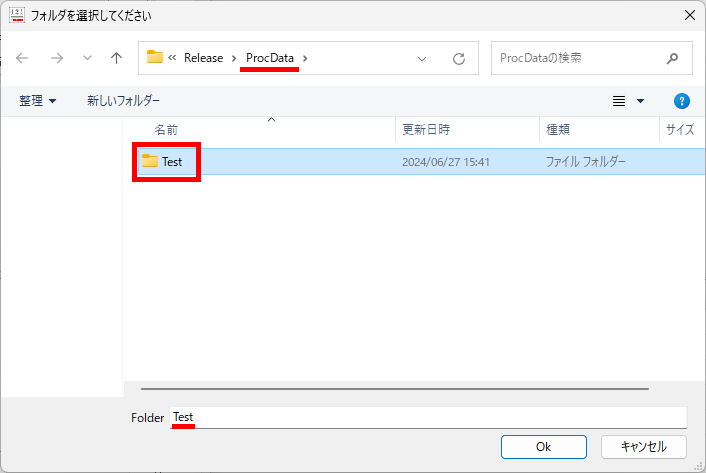
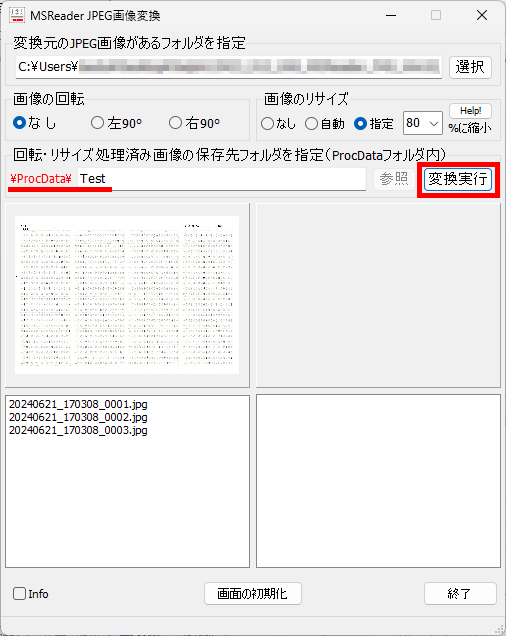
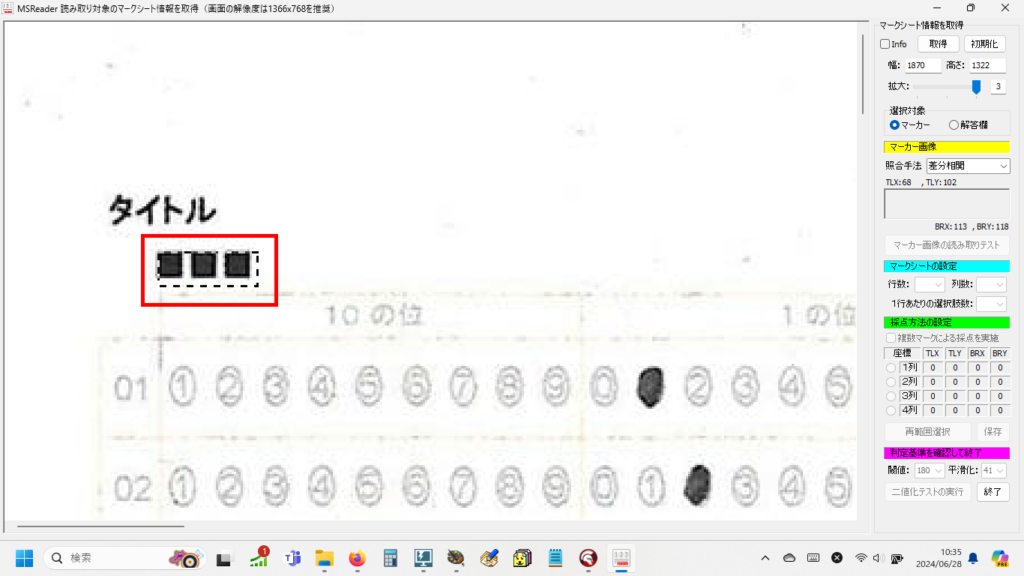
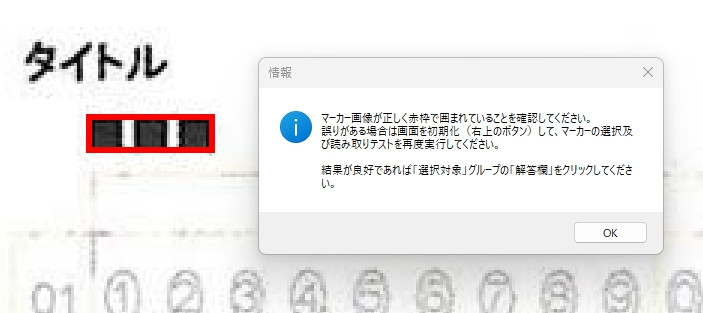
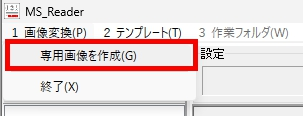
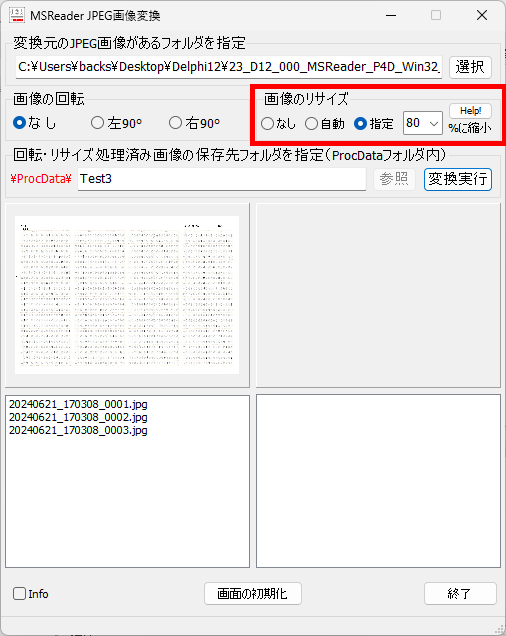
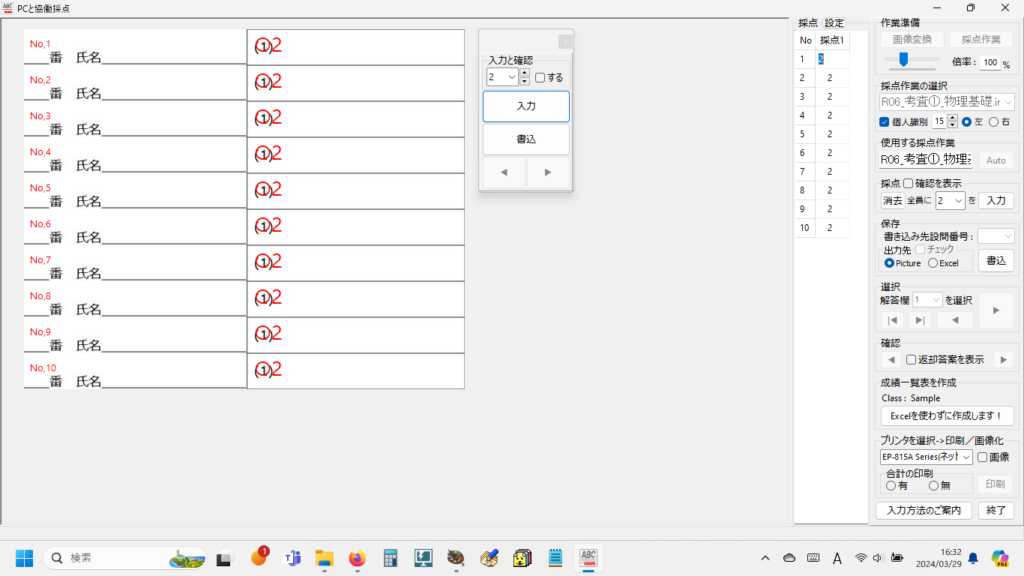
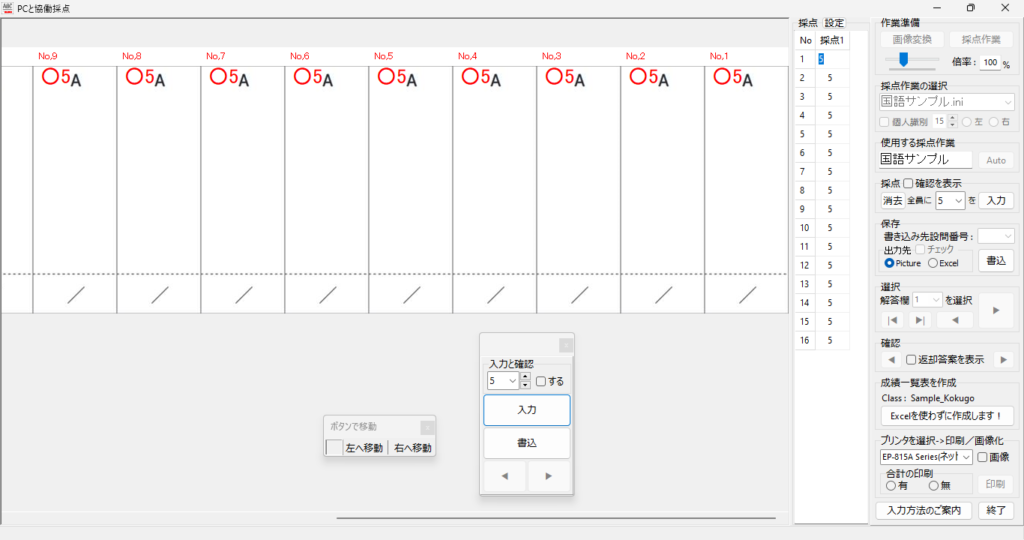
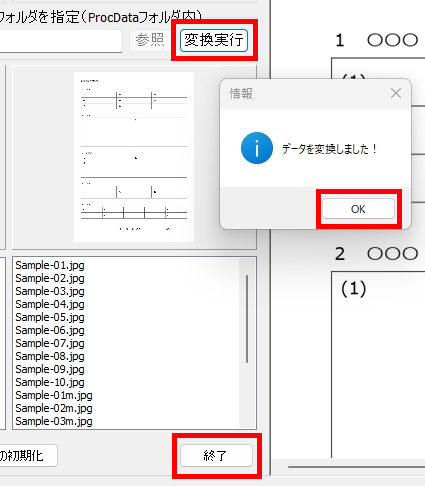
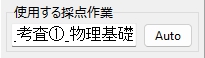
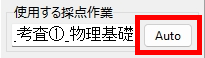
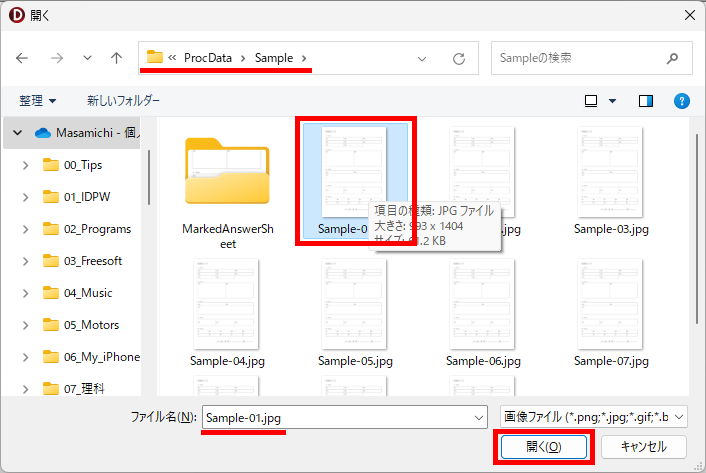
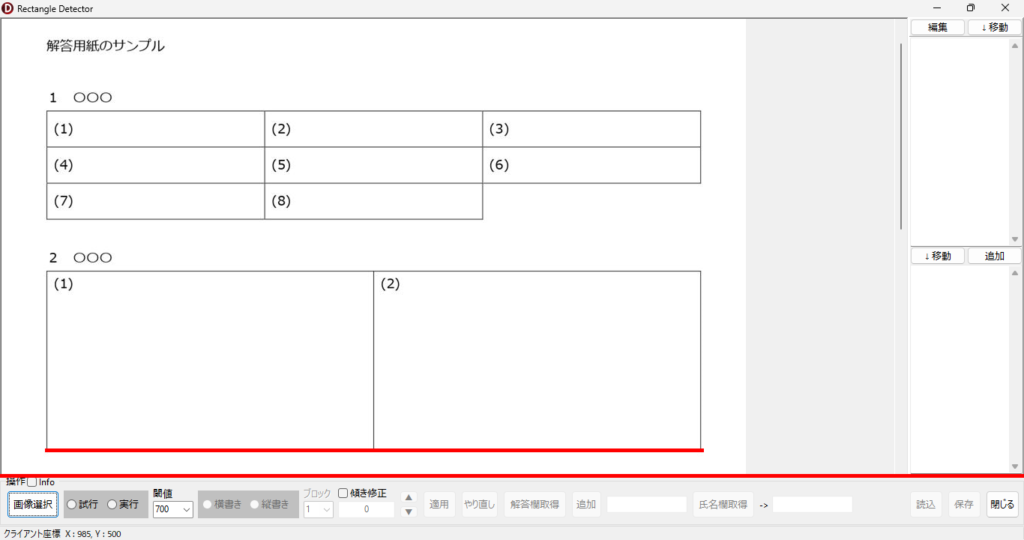
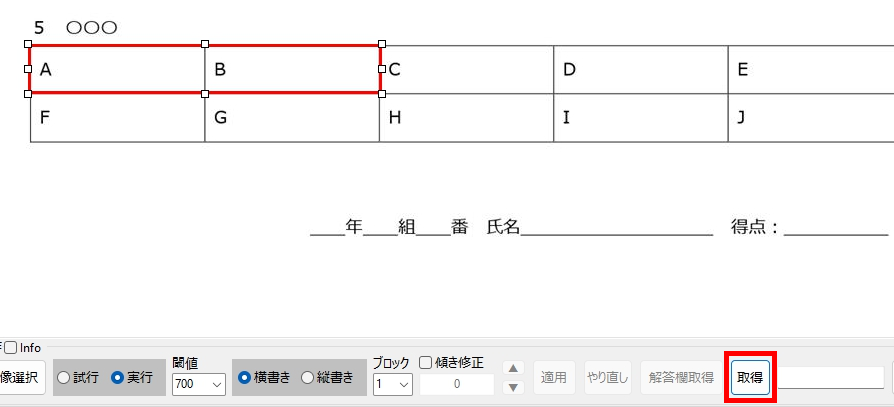
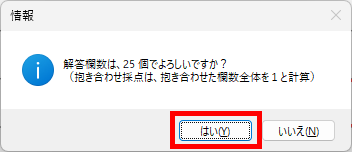
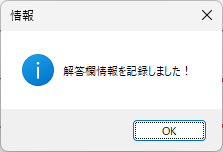
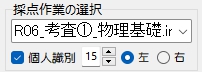
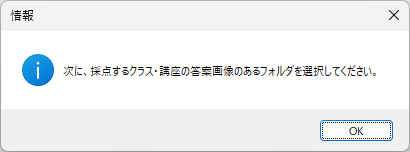
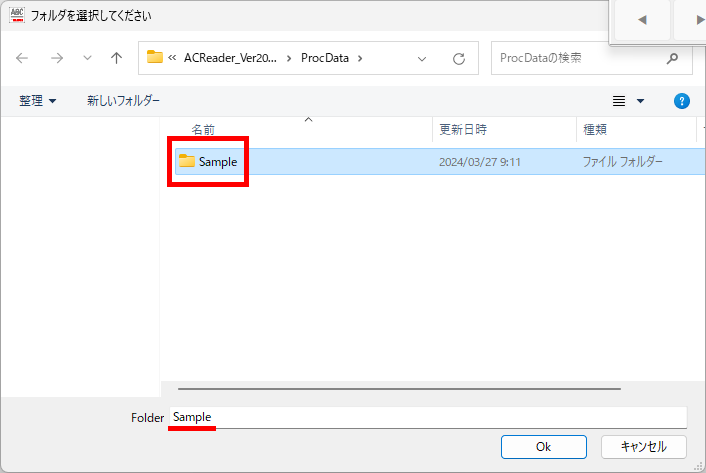
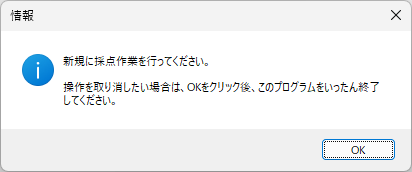
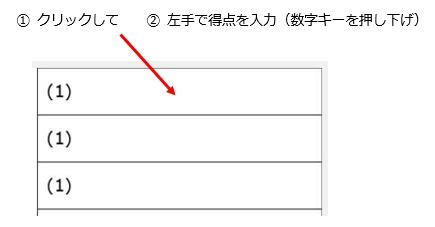
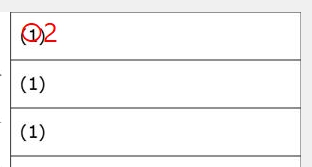
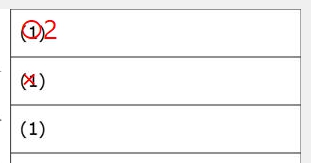
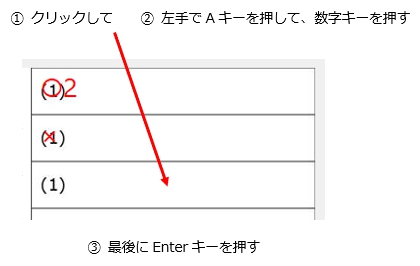
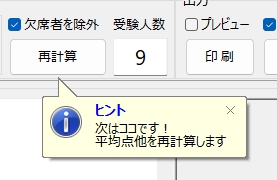
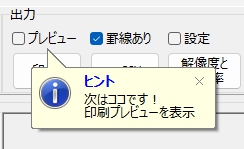
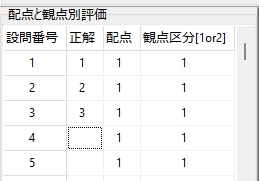
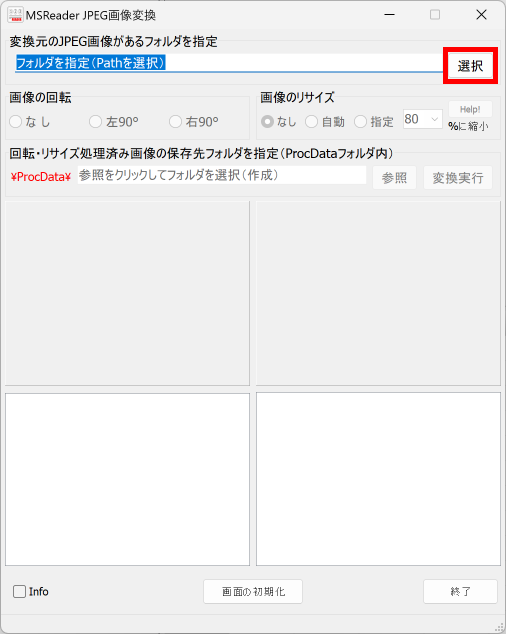
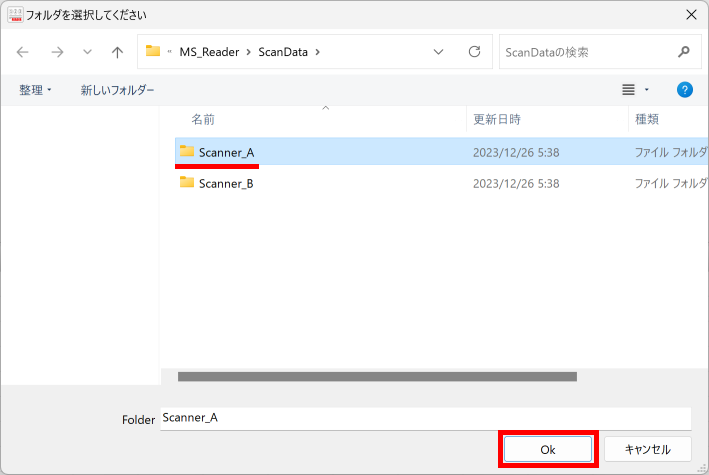
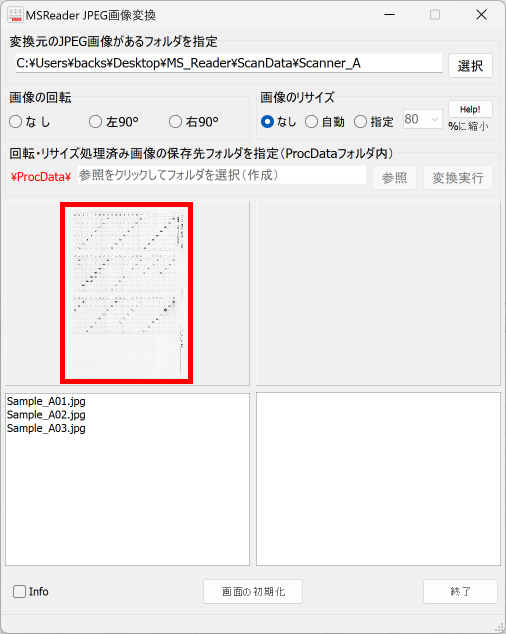
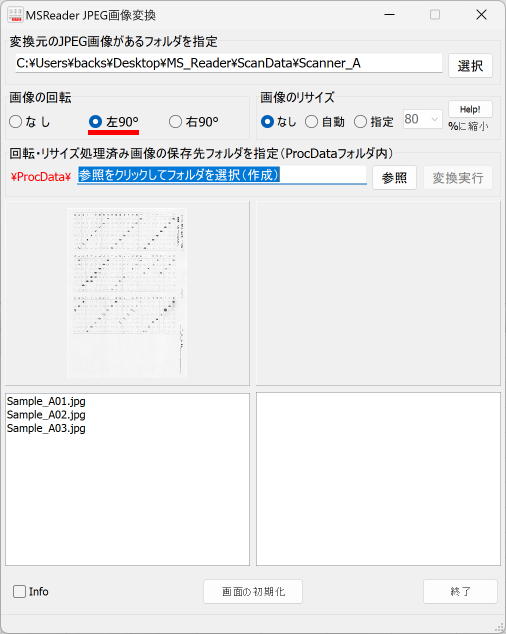
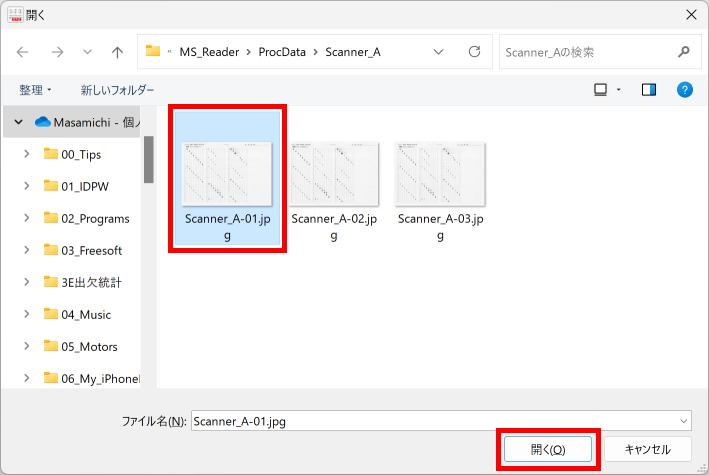
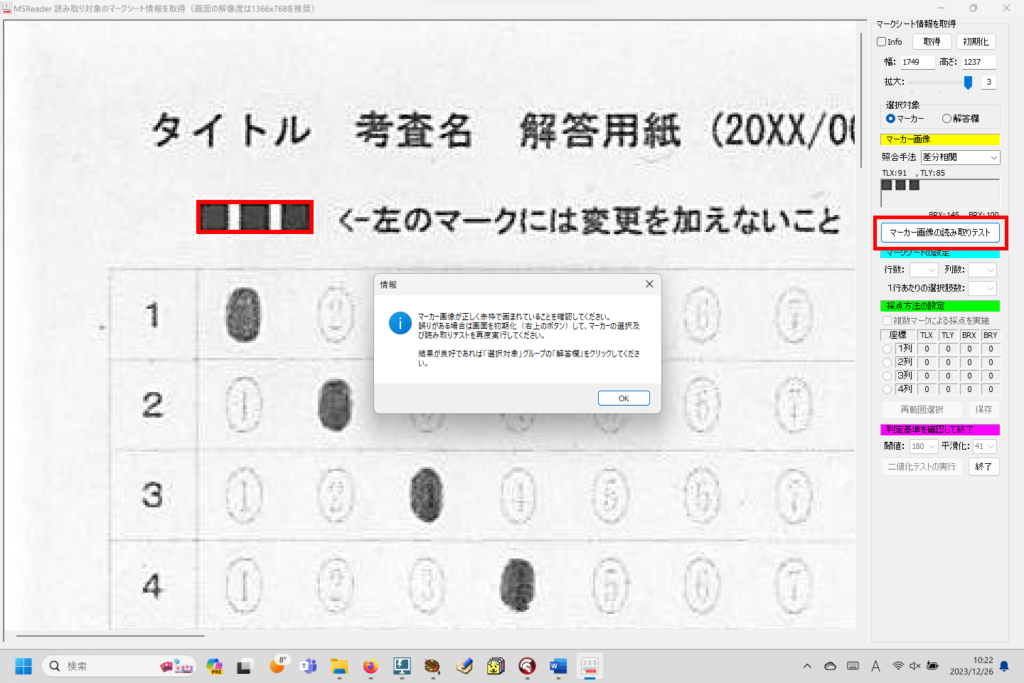
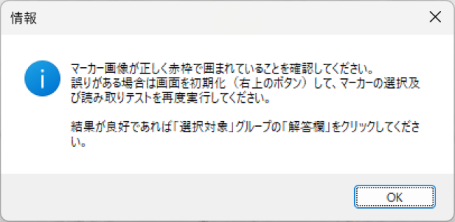
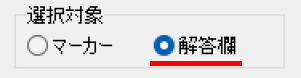
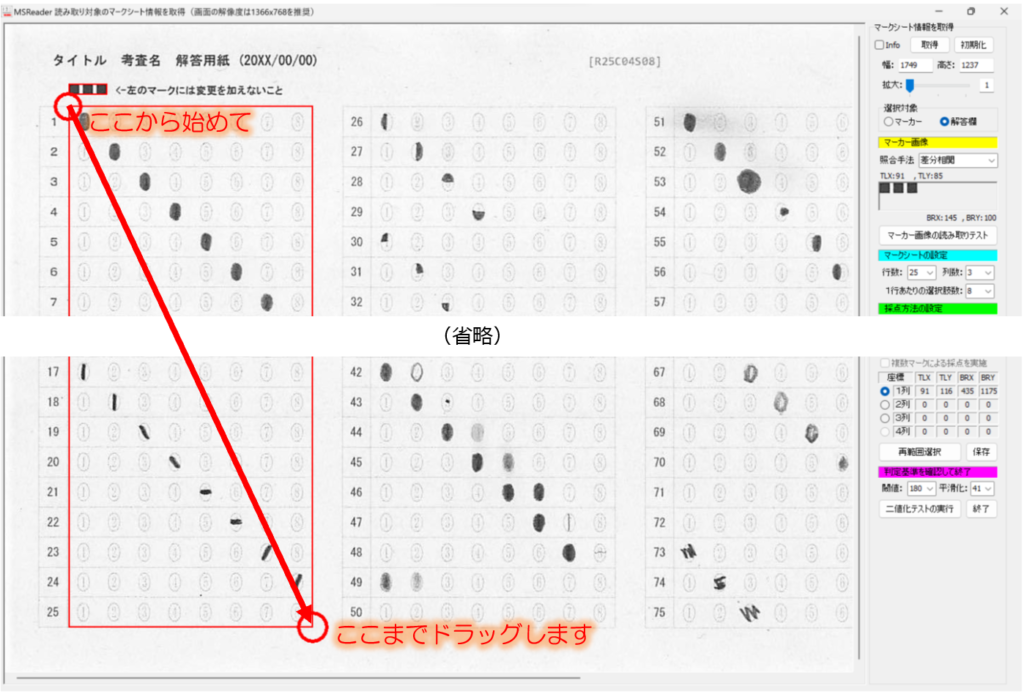
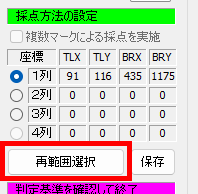
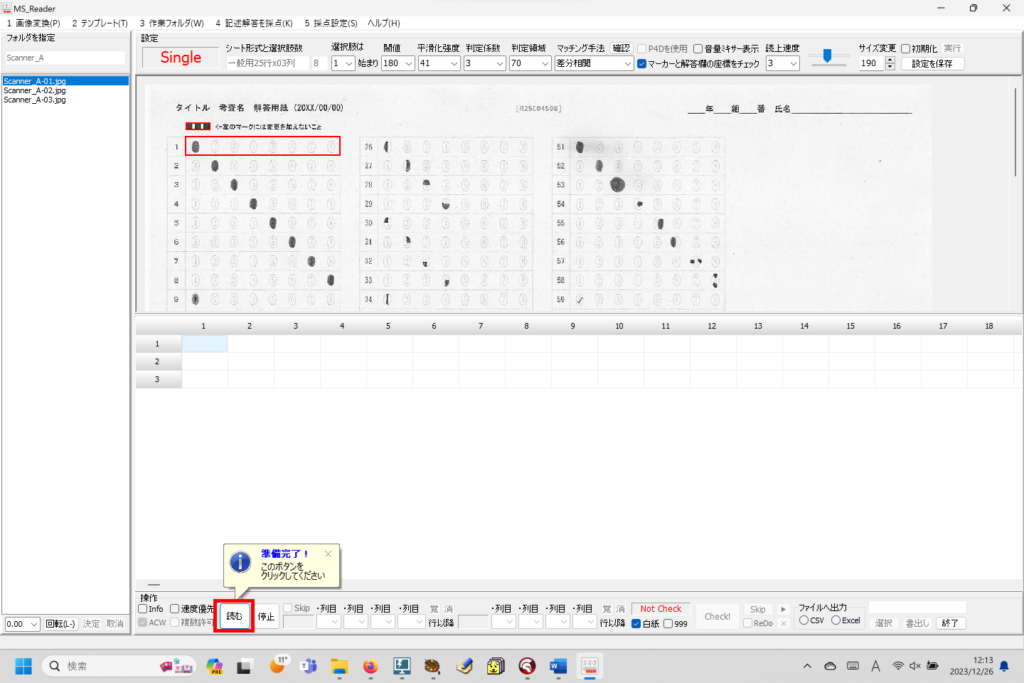
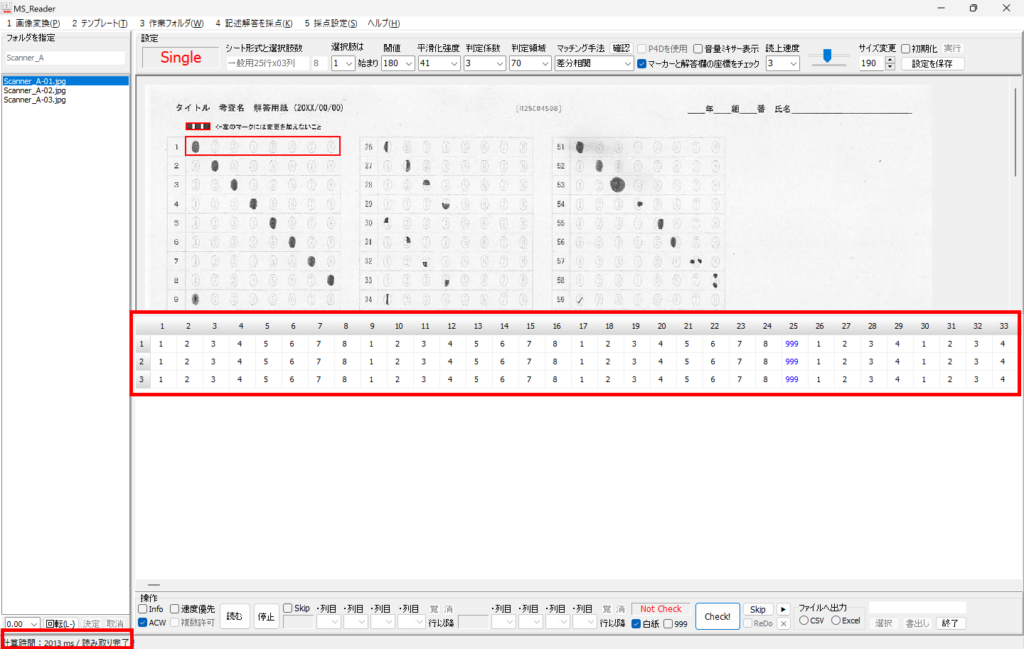
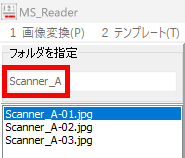
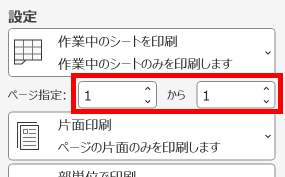
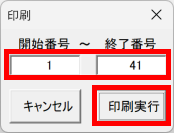
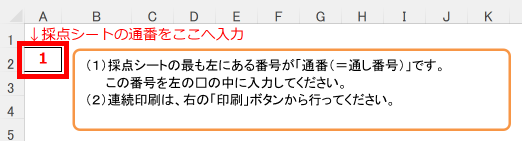
マークシートを読み取り後、読み取り結果のチェックまで完了したら、Excel Book への読み取り結果の書き出しが可能となります。次のようにマークシートリーダーを操作してください。
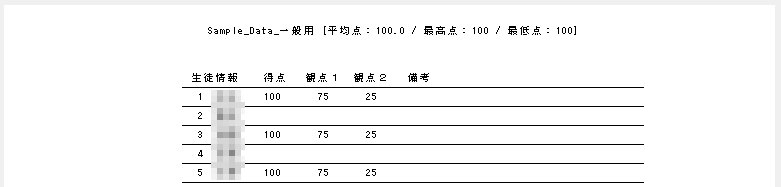
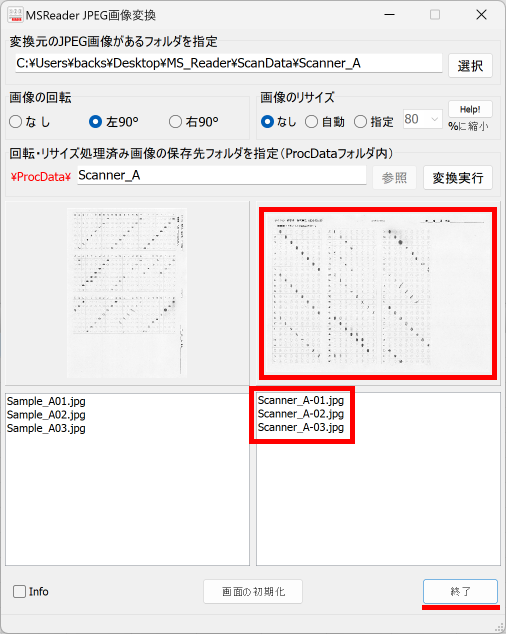
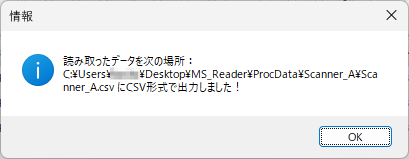
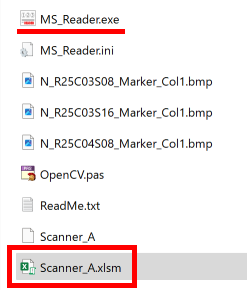
ファイル名がなぜ「Scanner_A.xlsm」になったかというと、マークシートの読み取り元フォルダとして選択したのが、ProcData\Scanner_A であったためです。プログラムは、マークシートの読み取り元フォルダの名称をそのまま、原本「test.xlsm」をコピーして生成する読み取り結果書き込み先 Excel Book の名称として利用します。